Distributed learning for heterogeneous clinical data with application to integrating COVID-19 data across 230 sites
Published in Healthcare & Nursing
What do we know about data integration?
Starting from the 2010s, the adoption of EHR systems grows rapidly in the United States. The real-world data (RWD), including EHRs, claims, and billing data among others, have become an invaluable data source for comparative effectiveness research (CER) during the past few years1,2. Synthesis of the RWD stored electronically in the EHR systems from multiple clinical sites provides a larger sample size of the population compared to a single site study3. Analyses using larger populations can benefit the accuracy in estimation and prediction. The integration of research networks inside healthcare systems also allows rapid translation and dissemination of research findings into evidence-based healthcare decision making to improve health outcomes, consistent with the idea of a learning health system4–9.
In multi-center studies, maintaining privacy of patient data is a major challenge10–12. The Health Insurance Portability and Accountability Act of 1996 (HIPAA) introduced a privacy rule to regulate use of protected health information (PHI) often found in EHRs, requiring de-identification of PHI before use in biomedical research11. De-identified PHI has been shown to be susceptible to re-identification, causing concern among patients13,14.
In light of patient privacy concerns, many multicenter studies currently conduct analyses by combining shareable summary statistics through meta-analysis15–17. While relatively simple to use, meta-analysis has been shown to result in biased or imprecise estimation in the context of rare outcomes, as well as with smaller sample sizes18. Other than meta-analysis, several distributed algorithms have been developed and considered in studies with multi-site data. In these distributed algorithms, a model estimation process is decomposed into smaller computational tasks that are distributed to each site. After parallel computation, intermediate results are transferred back to the coordinating center for final synthesis. Under this framework, there is no need to share patient-level data across sites. For example, GLORE (Grid Binary LOgistic Regression) was developed for conducting distributed logistic regressions19, and WebDISCO (a Web service for distributed Cox model learning) was developed to fit the Cox proportional hazard model distributively and iteratively20. Both algorithms have been successfully deployed to the pSCANNER consortium21. Through iterative communication of aggregated information across the sites, these two algorithms provide accurate and lossless results, which are equivalent to fitting a model on the pooled data from all sites. However, in practice these methods can be time-consuming and communication-intensive due to the need for iteratively transferring data. To overcome this limitation, non-iterative privacy-preserving distributed algorithms (specifically, one-shot algorithms, which only require one round of communications across sites) for logistic regression (termed as ODAL) and Cox model (termed as ODAC) through the construction of a surrogate likelihood have been proposed18,22,23.
What do we know about the COVID-19 mortality across various hospitals?
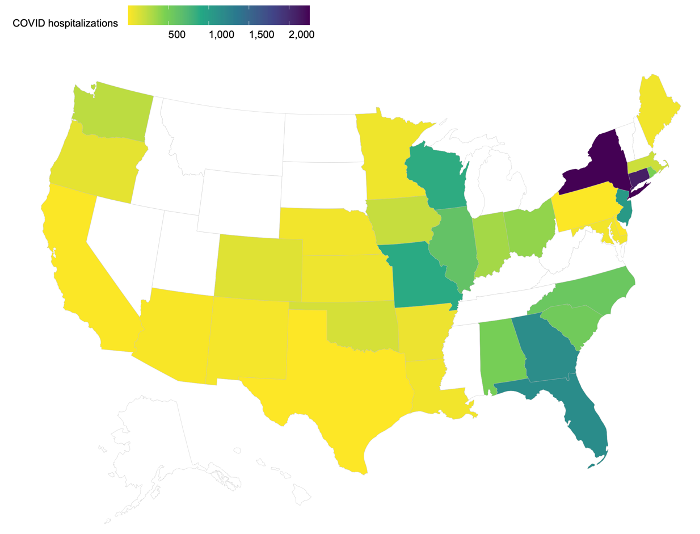
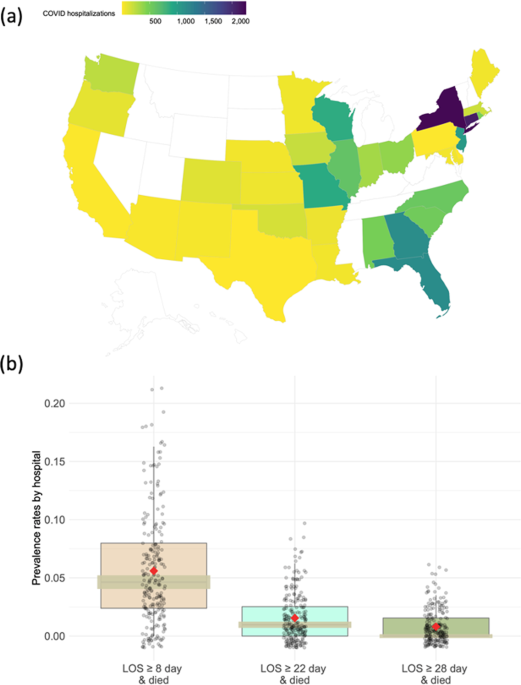
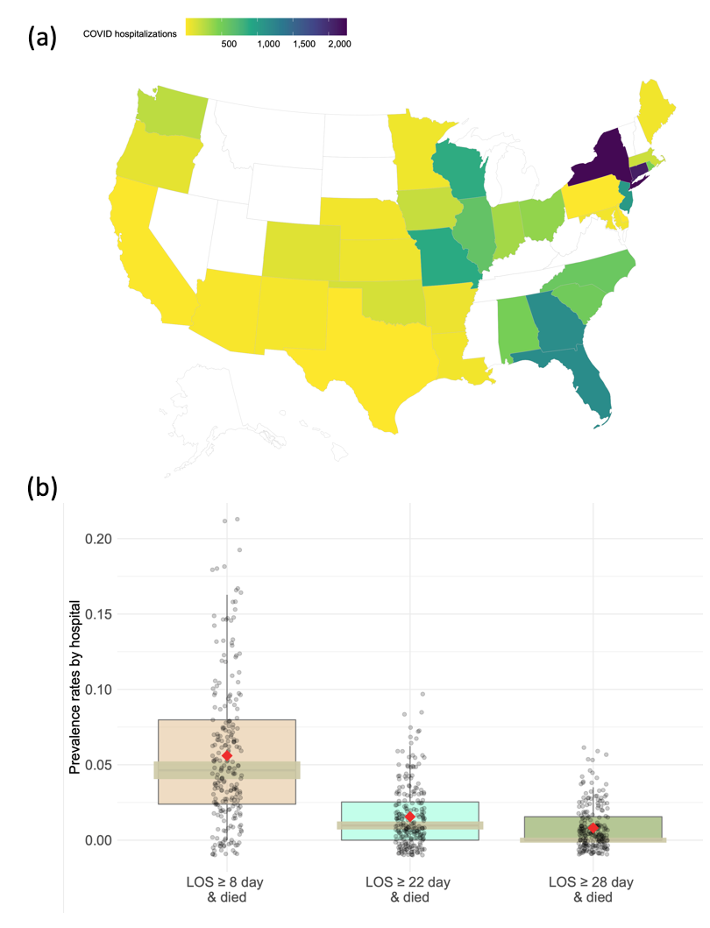
Our motivating example is the claims data derived from the insurance claims of 14,215 patients who were diagnosed with COVID-19 prior to June 29, 2020. Containing demographic, diagnosis, and procedural codes, the claims data are collected from 230 sites documented in the UnitedHealth Group Clinical Research Database. There is a substantial difference in clinical practices across these sites due to such factors as geographical variability in disease patterns, variations in patients’ characteristics, and regional differences in practice patterns. Specifically, large variation in the COVID-19 hospitalization distribution exists across 47 states in the U.S. (Figure 1 (a), created by open-source R package usmap24). The rate of the interested outcome, defined by combining both hospitalizations (days) and the status of patients being expired, ranges from <1% to 6% across the 230 sites as shown in Figure 1 (b). Therefore, developing distributed methods to account for the heterogeneity in the data is especially needed when analyzing multi-site data within the networks.
What does our study add to the understanding the heterogeneous multi-site data on COVID-19 mortality?
All the aforementioned distributed algorithms rely on the assumption that data across clinical sites are homogeneous. This assumption is often not reflecting the reality in biomedical studies because often there are intrinsic differences across clinical sites in terms of population characteristics, types of interventions, data collection procedures, and so on. Ignoring heterogeneity across clinical sites can induce biases in estimating associations between the exposures of interest and outcomes10,25.
Therefore, we develop a distributed conditional logistic regression (dCLR) algorithm to integrate heterogeneous RWD from multiple clinical sites without sharing patient-level data. This algorithm accounts for between-site heterogeneity by a construction of pairwise likelihood, and facilitates data integration by efficient communication (i.e., only requires one round of communication of aggregated information from collaborative sites). This distributed algorithm is based on models that allow site-specific effects, without the need for specification of the distribution of the site-specific effects, which brings robustness to statistical inference.
Figure 2 shows the comparisons between the pooled analysis, meta-analysis method, iterative distributed algorithms, and the proposed method from various aspects. The proposed method, which is based on the surrogate pairwise likelihood approach, can retain high accuracy in estimated model parameters, protect patient privacy, handle heterogeneity, while being communication efficient.
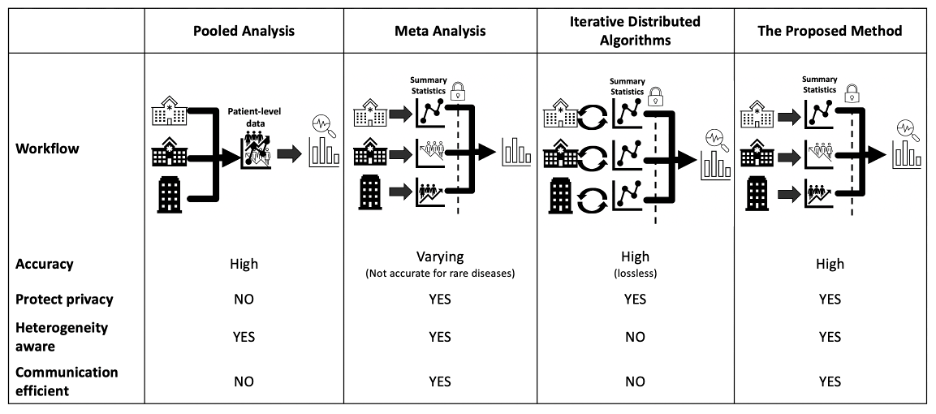
Figure 2: Existing methods comparison. Accuracy is evaluated through mean squared error (MSE) and bias to the true value: the smaller the MSE or bias is, the better the accuracy is. Privacy is evaluated based on if the method is an aggregated data-based approach without sharing patient-level information. Heterogeneity refers to the different disease prevalence values or baseline risks, which can be evaluated by calculating the variance or the range of the intercepts of the model26. The evaluation of communication is through the number of rounds of transferring aggregated data across sites and the number of digits to be communicated within each round.
With the administrative claims data for 14,215 hospitalized patients from 230 sites, we primarily focus on estimating and comparing parameter estimates by the proposed method and the meta-analysis method. We stress that the parameter estimates need to be interpreted with caution since the effects’ magnitudes or directions might be misleading without adjusting for potential confounders in the model. Figure 3 illustrates the results obtained by the pairwise likelihood method (i.e., gold standard method with pooled patients’ patient-level data), the proposed method, and meta-analysis. As the prevalence rate decreases (i.e., in rare events), the proposed method outperforms meta-analysis in terms of estimating parameters. Specifically, the odds ratio (OR) of the proposed method remains closer to that of the gold standard approach, compared with the OR of meta-analysis. The proposed estimates have a relative bias <9% when the event rate is <1%, whereas the meta-analysis estimates have a relative bias at least 10% higher than that of the proposed method. With the bootstrap method with 100 replications, the differences with respect to the gold standard method (black, top) between the proposed algorithm (middle, blue) and the meta-analysis method (bottom, red) are all statistically significant with the p-values smaller than 0.001 across all settings for all covariates.
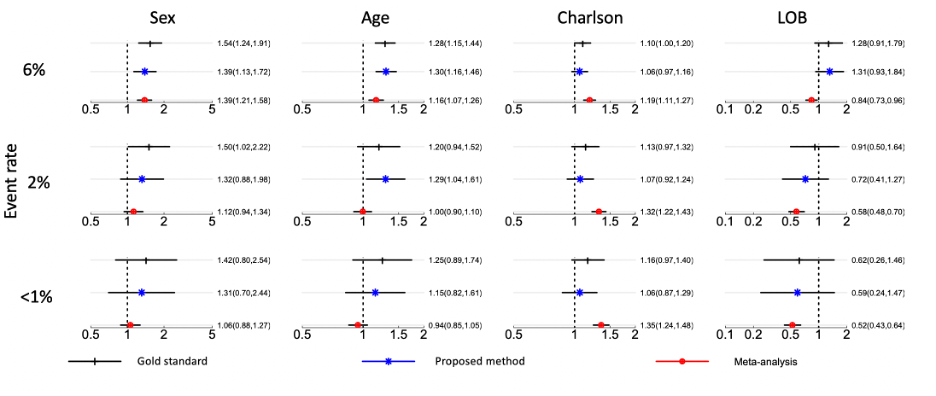
What are the broader impacts of our study?
In the last decade, the increasing adoption of electronic health data and an increasing number of distributed research networks such as PCORnet including PEDSnet, OneFlorida, The Stakeholder, Technology, and Research (STAR) network, and the Observational Health Data Sciences and Informatics (OHDSI), have led to a great opportunity for multi-site studies. The barrier of sharing data is one of the major challenges in multi-site studies. Centralizing the patient-level data does not maintain patient privacy and raises the issue of data autonomy where the original data owner does not have control over the data. To tackle the data sharing barrier, we developed the distributed algorithm that preserves the patient-level information by only requiring task-specific aggregated data. In particular, the proposed dCLR (distributed conditional logistic regression model) algorithm accounts for the heterogeneity in analyzing the multi-site real-world data (RWD). We believe that dCLR is a significant contribute to advance research using data from distributed research networks. As a powerful tool in modeling the risk factors of binary outcomes, the dCLR algorithm facilitates the collaborative environment and advances scientific research on real-world evidence (RWE).
A solution to next generation data sharing for collaborative modeling
Our dCLR algorithm is an important step forward in facilitating secure data sharing and collaborative across different sites. An appealing feature of this algorithm is its flexibility in accounting for heterogeneity in baseline characteristics of subjects at different sites. Our dCLR is part of our general framework of distributed learning (also known as collaborative learning) methods, which we term as “PDA: Privacy-preserving Distributed Algorithms”. Our algorithms are communication-efficient, accurate, privacy-preserving, and heterogeneity-aware.
Here are the related materials for PDA:
- dCLR Github page: https://github.com/Penncil/dCLR
- PDA website: https://pdamethods.org/
- Introduction Video of PDA: https://youtu.be/dvX0h5pFtIk
- PDA-OTA platform: https://pda-ota.pdamethods.org/
- PDA-OTA stands for PDA Over the Air, which is an online secure communication tools for aggregated data sharing and collaborative project management.
- Introduction Video of PDA-OTA: https://youtu.be/ajix3Qi1leg
REFERENCES
- Sherman, R. E. et al. Real-world evidence—what is it and what can it tell us. N. Engl. J. Med. 375, 2293–2297 (2016).
- Fda, U. S., Food, Administration, D. & Others. Framework for FDA’s Real-World Evidence Program. (2018).
- Bowens, F. M., Frye, P. A. & Jones, W. A. Health information technology: integration of clinical workflow into meaningful use of electronic health records. Perspect. Health Inf. Manag. 7, 1d (2010).
- Friedman, C. P., Wong, A. K. & Blumenthal, D. Achieving a nationwide learning health system. Sci. Transl. Med. 2, 57cm29 (2010).
- Weng, C. et al. Using EHRs to integrate research with patient care: promises and challenges. J. Am. Med. Inform. Assoc. 19, 684–687 (2012).
- Greene, S. M., Reid, R. J. & Larson, E. B. Implementing the learning health system: from concept to action. Ann. Intern. Med. 157, 207–210 (2012).
- Smoyer, W. E., Embi, P. J. & Moffatt-Bruce, S. Creating Local Learning Health Systems: Think Globally, Act Locally. JAMA 316, 2481–2482 (2016).
- Maro, J. C. et al. Design of a national distributed health data network. Ann. Intern. Med. 151, 341–344 (2009).
- Brown, J. S. et al. Distributed health data networks: a practical and preferred approach to multi-institutional evaluations of comparative effectiveness, safety, and quality of care. Med. Care 48, S45-51 (2010).
- Wu, H.-D. I. Effect of Ignoring Heterogeneity in Hazards Regression. in Parametric and Semiparametric Models with Applications to Reliability, Survival Analysis, and Quality of Life (eds. Balakrishnan, N., Nikulin, M. S., Mesbah, M. & Limnios, N.) 239–250 (Birkhäuser Boston, 2004). doi:10.1007/978-0-8176-8206-4_16.
- Arellano, A. M., Dai, W., Wang, S., Jiang, X. & Ohno-Machado, L. Privacy Policy and Technology in Biomedical Data Science. Annu Rev Biomed Data Sci 1, 115–129 (2018).
- Loukides, G., Denny, J. C. & Malin, B. The disclosure of diagnosis codes can breach research participants’ privacy. J. Am. Med. Inform. Assoc. 17, 322–327 (2010).
- Benitez, K. & Malin, B. Evaluating re-identification risks with respect to the HIPAA privacy rule. J. Am. Med. Inform. Assoc. 17, 169–177 (2010).
- McGraw, D. Building public trust in uses of Health Insurance Portability and Accountability Act de-identified data. J. Am. Med. Inform. Assoc. 20, 29–34 (2013).
- Vashisht, R. et al. Association of Hemoglobin A1c Levels With Use of Sulfonylureas, Dipeptidyl Peptidase 4 Inhibitors, and Thiazolidinediones in Patients With Type 2 Diabetes Treated With Metformin. JAMA Network Open vol. 1 e181755 (2018).
- Boland, M. R. et al. Uncovering exposures responsible for birth season--disease effects: a global study. J. Am. Med. Inform. Assoc. 25, 275–288 (2018).
- Hripcsak, G. et al. Characterizing treatment pathways at scale using the OHDSI network. Proc. Natl. Acad. Sci. U. S. A. 113, 7329–7336 (2016).
- Duan, R. et al. Learning from local to global-an efficient distributed algorithm for modeling time-to-event data. Journal of the American Medical Informatics Association 27, 1028–1036 (2020).
- Wu, Y., Jiang, X., Kim, J. & Ohno-Machado, L. Grid Binary LOgistic REgression (GLORE): building shared models without sharing data. J. Am. Med. Inform. Assoc. 19, 758–764 (2012).
- Lu, C.-L. et al. WebDISCO: a web service for distributed cox model learning without patient-level data sharing. J. Am. Med. Inform. Assoc. 22, 1212–1219 (2015).
- Ohno-Machado, L. et al. pSCANNER: patient-centered Scalable National Network for Effectiveness Research. J. Am. Med. Inform. Assoc. 21, 621–626 (2014).
- Duan, R., Boland, M. R., Moore, J. H. & Chen, Y. ODAL: A one-shot distributed algorithm to perform logistic regressions on electronic health records data from multiple clinical sites. Pac. Symp. Biocomput. 24, 30–41 (2019).
- Duan, R. et al. Learning from electronic health records across multiple sites: A communication-efficient and privacy-preserving distributed algorithm. Journal of the American Medical Informatics Association 27, 376–385 (2020).
- CRAN - Package usmap. https://cran.r-project.org/web/packages/usmap/index.html.
- Liang, K. Y. Extended Mantel-Haenszel estimating procedure for multivariate logistic regression models. Biometrics 43, 289–299 (1987).
- Tong, J. et al. An augmented estimation procedure for EHR-based association studies accounting for differential misclassification. Journal of the American Medical Informatics Association 27, 244–253 (2020).
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in