Dynamic Predictions of Postoperative Complications from Explainable, Uncertainty-Aware, and Multi-Task Deep Neural Networks
Published in Healthcare & Nursing
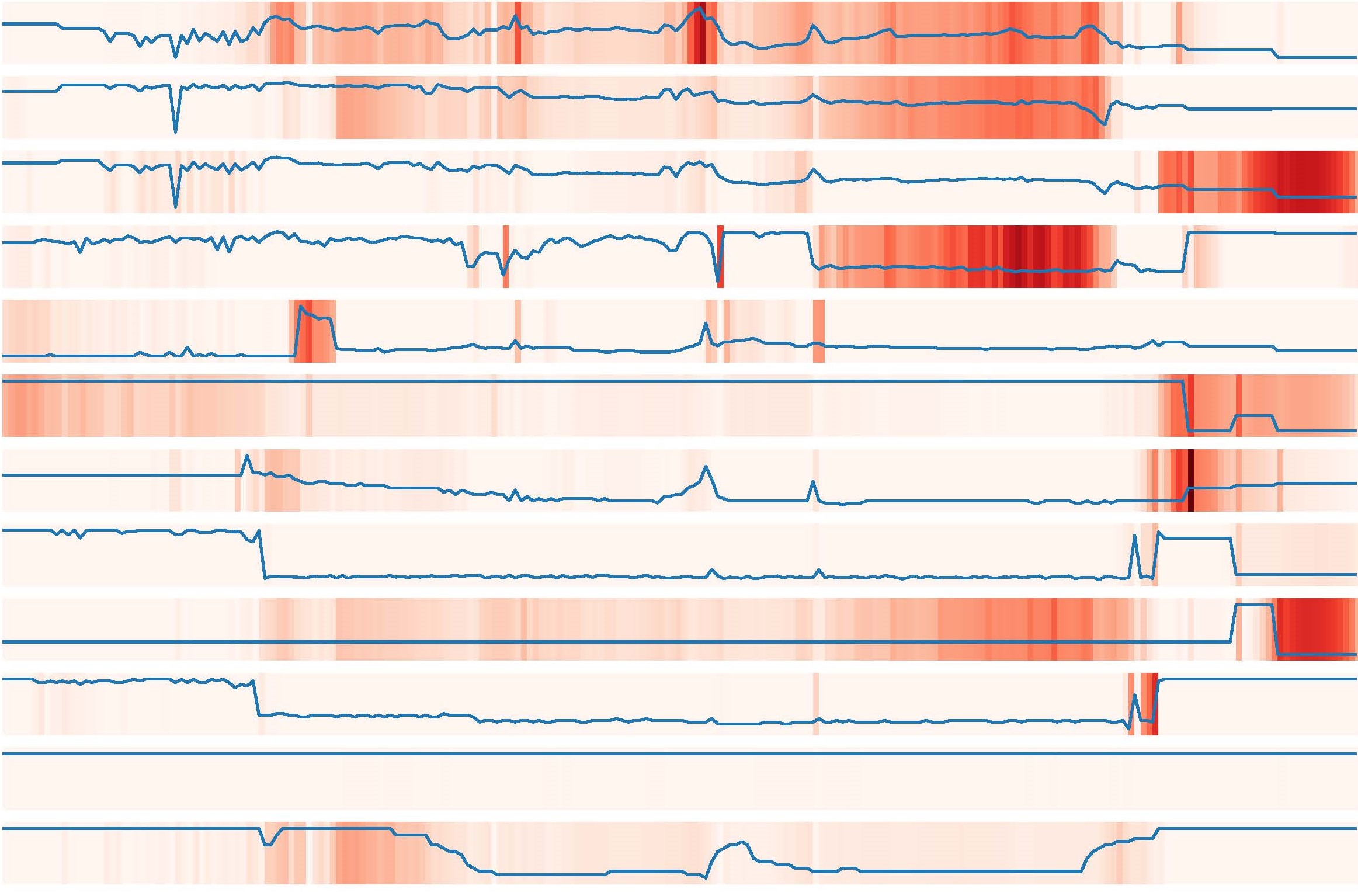

Over 15 million major inpatient surgeries are performed annually in the United States. Of these surgeries, 32% present complications that can decrease patient quality of life and increase healthcare costs.1, 2, 3 Through machine-learning decision support, predictions of postoperative complications could provide doctors and patients additional insight into matters such as the decision to perform surgery, actions to take before surgery (e.g., smoking cessation), and how to administer postoperative care (e.g., ICU or general ward).
Despite the potential of machine-learning models, current perioperative predictive tools to support clinical decision-making are hindered by suboptimal performance, lack of available intraoperative data, and the time need to enter patient data manually.4, 5 Deep learning tools may mitigate these issues, but their performance when using all available data to predict postoperative complications has not been studied and reported, perhaps because of skepticism over the use of machine-learning tools in clinical decision-making support. This skepticism could stem from mistrust in the predictions of the machine learning models and difficulty in understanding how the model arrived at a prediction; therefore, uncertainty-awareness mechanisms (i.e., identifying a prediction’s degree of uncertainty) as well as model interpretability (i.e., understanding how a model arrives at a prediction) could help facilitate the use of deep learning models in a clinical setting.
The goal of our study was to determine the efficacy of deep learning tools that predict postoperative complications and support medical decision-making by testing three models:
- Preoperative model—only uses data from 1 year prior to surgery until the day of surgery
- Intraoperative model—only uses data from the beginning of surgery until the end of surgery
- Postoperative model—uses both preoperative and intraoperative data (from 1 year prior to surgery until the end of surgery)
Additionally, we implemented uncertainty-awareness mechanisms (Monte Carlo dropout method) for each of our deep learning models, and we implemented model interpretability (integrated gradients) for our postoperative model.
How did we do it?
EHR data was pulled from a longitudinal cohort of over 5,500 patients who had 67,481 inpatient surgeries at UF Health between 2014 and 2020. Our deep learning predictive models were compared to random forest and XGBoost models through preoperative and intraoperative physiological time series data. A single deep learning model was trained on nine postoperative complications simultaneously to improve model efficiency, integrated gradients to improve interpretability, and uncertainty metrics that represent population variance. The data pipeline and network arrangement to predict the nine complications is displayed in Figure 1. We compared the predictions of this multi-task model to models that were trained to predict only a single postoperative complication.
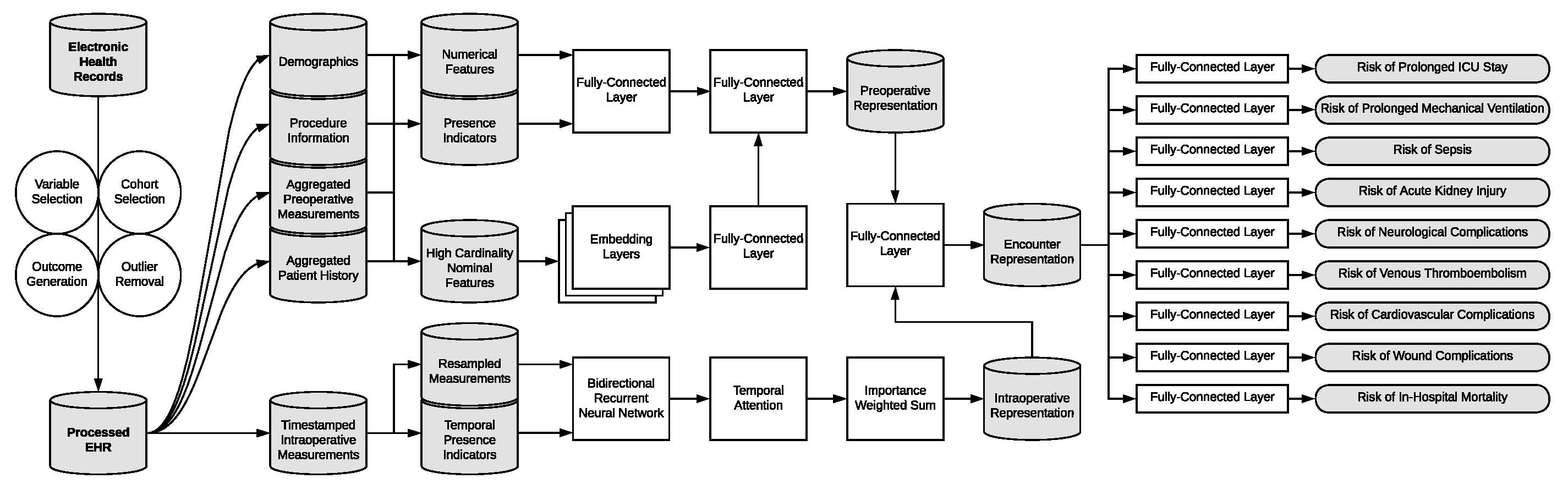
What were the results?
Comparing the efficiency of individual and multi-task outcome-specific models trained on preoperative or intraoperative time series data showed that deep multi-task models were not significantly different in their predictions. Training the postoperative deep learning model on all the available preoperative and intraoperative data led to a mixture of higher and lower area under the receiver operatic characteristic (AUROC) for the different complications, but the differences in AUROC were not statistically significant. From these tests, we determined that a multi-task approach for a deep learning-based postoperative model would be the best choice for the following reasons:
- Marginally stronger performance
- Decreased computational requirements (i.e., one model predicting nine complications instead of nine models predicting nine complications)
- Decreased training times
Deep multi-task models trained on perioperative descriptions, intraoperative time series data, and all available postoperative data had significantly higher AUROC than random forest and XGBoost models for almost all outcomes. The prolonged ICU stay complication had an equivalent AUROC for both the deep intraoperative multi-task model versus random forest model and the deep postoperative multi-task model versus XGBoost. The deep postoperative multi-task model produced a higher AUROC for prolonged mechanical ventilation than the random forest model, but it was not statistically significant. More detailed AUROC comparisons can be viewed in Figure 2.
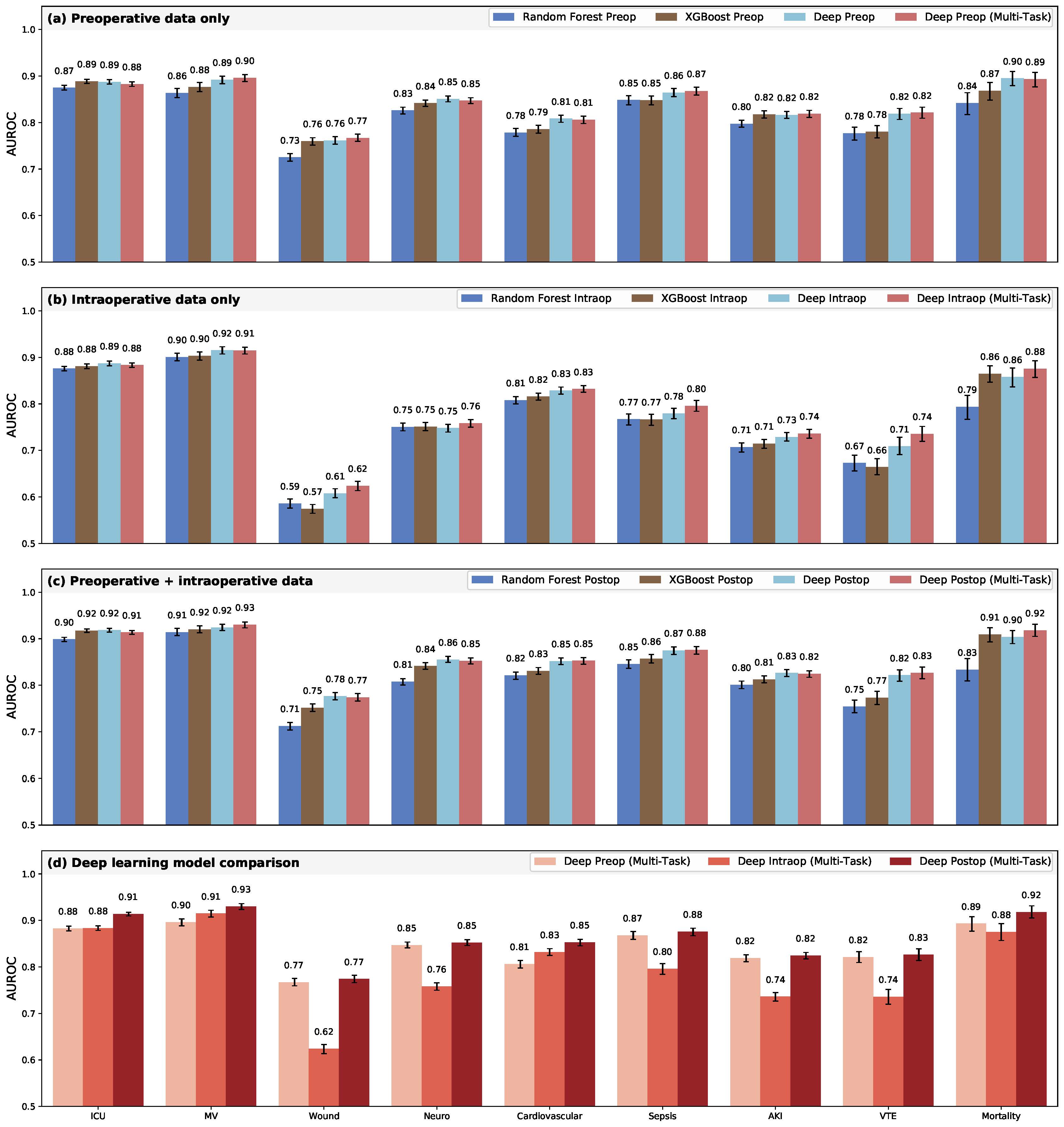
Deep postoperative models had a significant improvement in AUROC compared to preoperative models for the complications of prolonged ICU stay, prolonged medical ventilation, and cardiovascular complications. In terms of correctly reclassifying patient outcomes, deep postoperative multi-task models made significant overall reclassification improvements (0.3%-4.8%) when compared to the preoperative predictions. Although the deep postoperative models improved the overall reclassification of three complications, the models for wound complications and cardiovascular complications had better net reclassification indices.
To assuage concerns about the interpretability and certainty of the model predictions, we derived measures of prediction uncertainty with the Monte Carlo dropout method, applied integrated gradients to the model, and ascertained the important features of each postoperative complication from the gradients. When using models with the least uncertain training scheme for each outcome and prediction phase, postoperative predictions were less uncertain than preoperative predictions for four complications—prolonged mechanical ventilation, wound complications, cardiovascular complications, and in-hospital mortality.
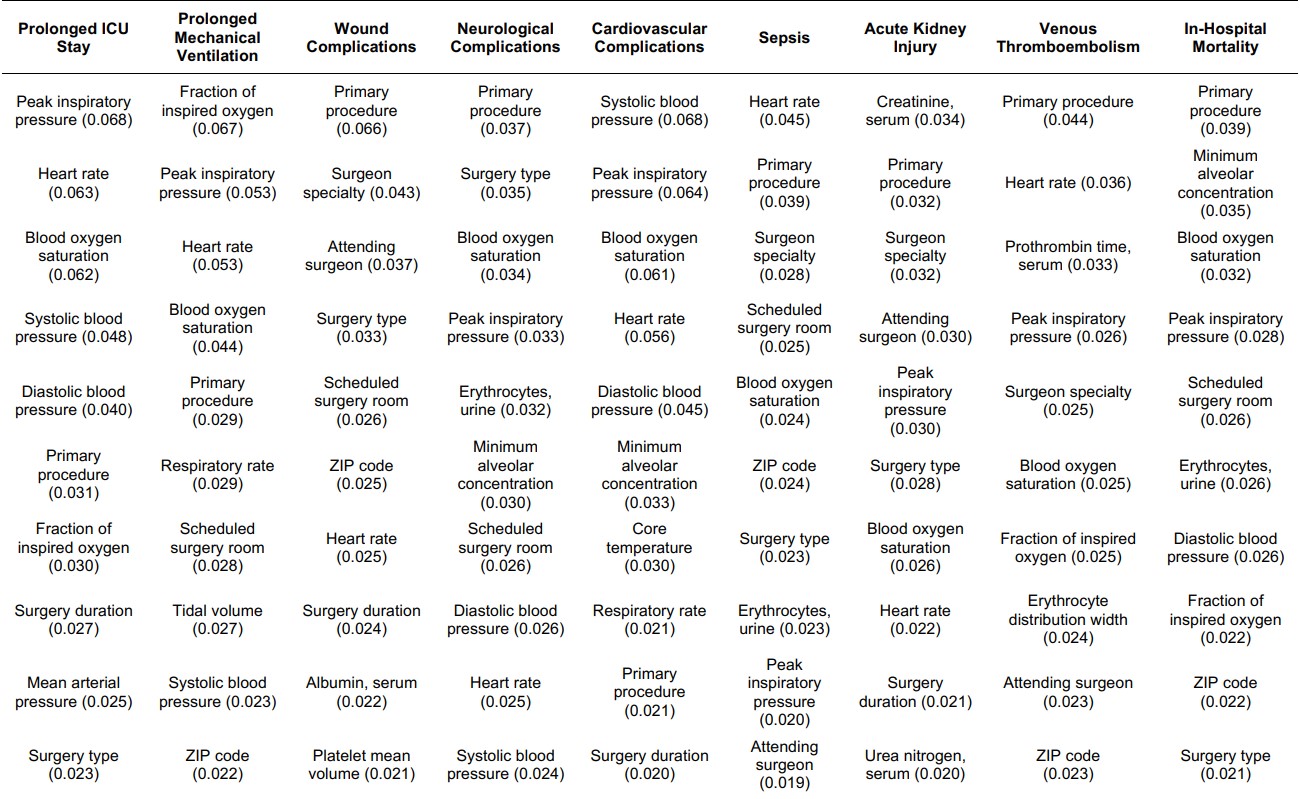
The top ten important features for each complication, as derived from integrated gradients, are listed in the table below (Table 1). Since the important features are consistent with current medical knowledge, experience, and evidence, clinicians and patients may be more likely to the trust the predictions produced by the deep postoperative multi-task model.6
What comes next?
Deep neural networks outperformed the random forest and XGBoost models for predicting postoperative complications, with the strongest performance occurring when all EHR data (both preoperative and intraoperative) was used. The results derived from uncertainty metrics and importance patterns align with medical decision-making being aligned with preoperative variables and the current knowledge base of postoperative complications. While the multi-task learning approach did not adversely affect overall performance, it was not wholly advantageous in predictive performance; however, the interpretability and certainty of the postoperative complication predictions produced from these models provide support to decisions made by clinicians and patients.
Our study was conducted at a single institution, and our models were not tested with prospective, real-time data. Future research should aim to analyze prospective data across multiple institutions to validate these findings. The accurate, interpretable, uncertainty-aware predictions that we presented in this article need further investigation in order to determine their potential to augment perioperative decision-making.
References
- Elixhauser, A. & Andrews, R. M. Profile of inpatient operating room procedures in US hospitals in 2007. Arch Surg 145, 1201-1208 (2010). https://doi.org:10.1001/archsurg.2010.269
- Dimick, J. B. et al. Hospital costs associated with surgical complications: a report from the private-sector National Surgical Quality Improvement Program. J Am Coll Surg 199, 531-537 (2004). https://doi.org:10.1016/j.jamcollsurg.2004.05.276
- Healey, M. A., Shackford, S. R., Osler, T. M., Rogers, F. B. & Burns, E. Complications in surgical patients. Arch Surg 137, 611-617; discussion 617-618 (2002).
- Cohen, M. E., Liu, Y., Ko, C. Y. & Hall, B. L. An Examination of American College of Surgeons NSQIP Surgical Risk Calculator Accuracy. J Am Coll Surg 224, 787-795.e781 (2017). https://doi.org:10.1016/j.jamcollsurg.2016.12.057
- Bilimoria, K. Y. et al. Development and evaluation of the universal ACS NSQIP surgical risk calculator: a decision aid and informed consent tool for patients and surgeons. J Am Coll Surg 217, 833-842.e831-833 (2013). https://doi.org:10.1016/j.jamcollsurg.2013.07.385
- Murdoch, W. J., Singh, C., Kumbier, K., Abbasi-Asl, R. & Yu, B. Definitions, methods, and applications in interpretable machine learning. Proceedings of the National Academy of Sciences 116, 22071-22080 (2019)
Follow the Topic
-
Scientific Reports
An open access journal publishing original research from across all areas of the natural sciences, psychology, medicine and engineering.

Related Collections
With Collections, you can get published faster and increase your visibility.
Infectious disease diagnostics
Publishing Model: Open Access
Deadline: Sep 23, 2026
Healthy Aging
Publishing Model: Open Access
Deadline: Dec 31, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in