Helformer: an attention-based deep learning model for cryptocurrency price forecasting
Published in Mathematical & Computational Engineering Applications, Statistics, and Business & Management
🔍 Behind the Scenes: Methodology & Innovation
1. The Helformer Architecture
Helformer integrates three key components to outperform existing models:
-
Series Decomposition: Using Holt-Winters smoothing, we break price data into level, trend, and seasonality components (Fig. 1). This step isolates patterns that traditional Transformers might miss.
-
Multi-Head Attention: Unlike sequential models (e.g., LSTM), Helformer processes all time steps simultaneously, capturing long-range dependencies efficiently.
-
LSTM-Enhanced Encoder: Replacing the standard Feed-Forward Network with an LSTM layer improves temporal feature extraction.
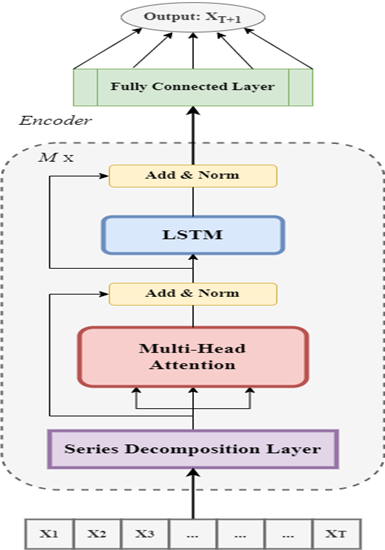
Fig. 1: Helformer architecture.
2. Data & Hyperparameter Tuning
We trained Helformer on Bitcoin (BTC) daily closing prices (2017–2024) and tested its generalization on 15 other cryptocurrencies (e.g., ETH, SOL). To optimize performance, we used Bayesian optimization via Optuna, automating hyperparameter selection (e.g., learning rate, dropout) and pruning underperforming trials early.
3. Evaluation Metrics
Helformer was benchmarked against RNN, LSTM, GRU, and vanilla Transformer models using:
-
Similarity metrics: R², Kling-Gupta Efficiency (KGE), EVS
-
Error metrics: RMSE, MAPE, MAE
-
Trading metrics: Sharpe Ratio, Maximum Drawdown, Volatility, Cumulative returns
💡 Key Findings & Practical Impact
1. Superior Predictive Accuracy
Helformer achieved near-perfect R² (1.0) and MAPE (0.0148%) on BTC test data, outperforming all baseline models (Table 1). Its decomposition step reduced errors by 98% compared to vanilla Transformers.
Table 1: Model Performance Comparison
|
Model |
RMSE |
MAPE |
MAE |
R² |
EVS |
KGE |
|
RNN |
1153.1877 |
1.9122% |
765.7482 |
0.9950 |
0.9951 |
0.9905 |
|
LSTM |
1171.6701 |
1.7681% |
737.1088 |
0.9948 |
0.9949 |
0.9815 |
|
BiLSTM |
1140.4627 |
1.9514% |
766.7234 |
0.9951 |
0.9952 |
0.9901 |
|
GRU |
1151.1653 |
1.7500% |
724.5279 |
0.9950 |
0.9950 |
0.9878 |
|
Transformer |
1218.5600 |
1.9631% |
799.6003 |
0.9944 |
0.9946 |
0.9902 |
|
Helformer |
7.7534 |
0.0148% |
5.9252 |
1 |
1 |
0.9998 |
2. Profitable Trading Strategies
In backtests, a Helformer-based trading strategy yielded 925% excess returns for BTC—tripling the Buy & Hold strategy’s returns (277%)—with lower volatility (Sharpe Ratio: 18.06 vs. 1.85), as shown in Fig. 2.
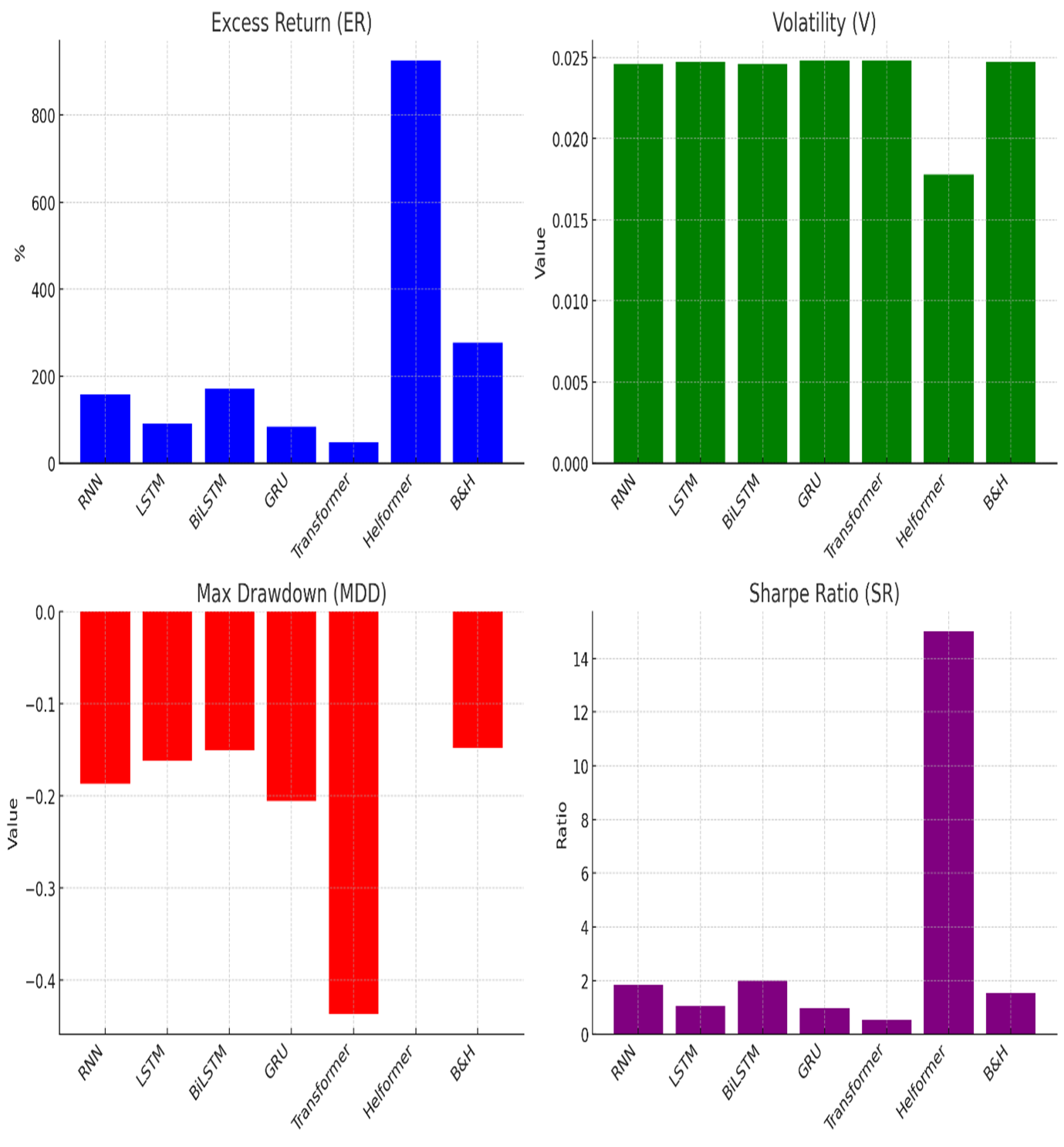 Fig. 2: Trading results.
Fig. 2: Trading results.
3. Cross-Currency Generalization
Helformer’s pre-trained BTC weights transferred seamlessly to other cryptocurrencies, achieving R² > 0.99 for XRP and TRX. This suggests broad applicability without retraining—a boon for investors managing diverse portfolios.
🌍 Relevance to the Community
-
For Researchers: Helformer’s architecture opens avenues for hybrid time-series models in finance, healthcare, and climate forecasting.
-
For Practitioners: The model’s interpretable components (decomposition + attention) make it adaptable to volatile markets beyond crypto.
-
For Policymakers: Reliable price forecasts could inform regulations to stabilize crypto markets and protect investors.
🤝 Acknowledgments & Open Questions
This work wouldn’t have been possible without my brilliant co-authors Oluyinka Adedokun, Joseph Akpan, Morenikeji Kareem, Hammed Akano, and Oludolapo Olanrewaju, or the support of The Hong Kong Polytechnic University.
We’d love to hear your thoughts!
-
How might Helformer adapt to non-financial time-series data?
-
Could integrating sentiment analysis further improve accuracy?
-
What ethical considerations arise with AI-driven trading?
🔗 Access the full paper: SpringerLink | ReadCube
I am Dr. Temitope Kehinde, a dedicated researcher, educator, and consultant with a solid background in Industrial & Systems Engineering. Currently, I serve as a Postdoctoral Fellow at The Hong Kong Polytechnic University, where I am working under the Hong Kong Government ITF project grant titled "Increasing First-dye Accuracy of Dyeing Processing by Artificial Intelligence" (Project account code K-45-35-ZWEF). This multimillion-dollar grant, fully funded by the Innovation and Technology Fund (ITF), is a testament to my expertise and contribution to the field. I am fortunate to work under the supervision of Prof. Sai-Ho Chung, conducting cutting-edge research aimed at improving dyeing processing accuracy using artificial intelligence.
My academic journey began at the University of Ibadan, Nigeria, where I earned a Bachelor’s degree in Industrial & Production Engineering with First Class Honours. This academic excellence was further complemented by my Master’s degree in Industrial & Production Engineering (Engineering Management option), which I completed with Distinction. My educational background laid a strong foundation for my current research, which integrates advanced technologies such as machine learning, data envelopment analysis (DEA), and multi-criteria decision-making (MCDM) techniques for real-world applications like smart production systems, smart manufacturing, financial modeling, and portfolio optimization.
In 2021, I began my Ph.D. in Industrial & Systems Engineering at The Hong Kong Polytechnic University, where I developed my research expertise in areas such as smart manufacturing, data-driven scheduling, and forecasting. My role as a Research and Teaching Assistant enabled me to contribute to both academia and industry, helping shape the next generation of engineers. In recognition of my dedication to teaching, I was honored with the Best Teaching Assistant Award in 2022.
In addition to my academic pursuits, I have gained valuable professional experience. I served as a Graduate Assistant at Zenith Bank Plc in Nigeria, gaining hands-on experience in financial services, including treasury management and asset management. I also work as a consultant for Pathway Education Holdings Limited, where I assist in recruiting African students for international study programs, bridging educational services and global opportunities.
I have presented my research at several international conferences, including the Computing Conference in London, the International Conference on Smart Mobility and Vehicle Electrification in Detroit, and the PolyU RS Conference in Hong Kong. My work focuses on leveraging machine learning and deep learning to enhance forecasting accuracy, particularly in volatile markets like cryptocurrency and stock trading.
I have been fortunate to receive several accolades, including the Hong Kong PhD Fellowship Scheme and my involvement in community-focused initiatives such as Smile4Me Initiative, where I serve as the founder and chairman. My work in both academia and the industry is driven by a passion for using data-driven solutions to solve complex, real-world problems.
As I continue to work on the Hong Kong Government ITF project and collaborate with industry partners, my goal is to further develop smart manufacturing solutions and contribute to the academic and professional communities. My future aspirations include advancing research in the intersection of sustainability, technology, and economic resilience, ultimately benefiting both business operations and societal well-being.
Follow the Topic

Related Collections
With Collections, you can get published faster and increase your visibility.
Intelligent Data Engineering for FAIR and Reusable Earth & Space Science and Applications
We invite researchers, practitioners, and industry experts to submit original contributions to this special issue/track focused on AI‑driven data engineering for Earth and Space Sciences. This collection addresses the rising need for intelligent techniques that support scalable, interoperable, and FAIR (Findable, Accessible, Interoperable, Reusable) data ecosystems across environmental, geospatial, planetary, and space science domains.
Scope and Themes
This track welcomes submissions that integrate Artificial Intelligence, data engineering, and scientific workflows to tackle challenges in managing, harmonizing, analyzing, and reusing complex Earth and Space Science data.
Topics of interest include, but are not limited to:
AI‑enabled data pipelines for Earth observation, satellite systems, and space mission data. Semantic, ontology‑driven, and knowledge‑based frameworks for metadata enrichment and interoperability. Intelligent workflow orchestration, hybrid AI systems, and agent‑based automation. Representation learning, self‑supervised learning, and foundation models for geospatial and environmental data. FAIR principles, reproducible workflows, Open Science frameworks, and transparent data governance. Scientific applications in climate analytics, disaster prediction, planetary exploration, environmental sustainability, and more.
Key Focus Areas
The special issue/track also highlights emerging AI‑driven paradigms for next‑generation scientific data engineering, including:
Foundation models and self‑supervised learning for Earth observation.
Knowledge graphs, semantic mapping, and retrieval‑augmented generation (RAG).
Agentic workflow orchestration and enhanced digital twin accessibility.
AI‑based multimodal data fusion, explainability, and domain adaptation.
Synthetic data generation and quality assessment.
Multivariate time‑series modeling and forecasting for environmental and planetary monitoring.
Why Submit?
This track aims to showcase innovations, architectures, frameworks, and real‑world case studies that demonstrate how AI‑driven data engineering accelerates scientific discovery, strengthens data interoperability, and supports sustainability across Earth and Space Science disciplines. Contributions that advance FAIR and Open Science principles are especially encouraged.
Work building upon discussions or early results presented at the DARES’25 ECAI Workshop is also welcome.
Publishing Model: Open Access
Deadline: Sep 05, 2026
LLM-Augmented Multimodal Data Fusion for Large-Scale Data Analysis
The rapid growth of multimodal data—such as text, images, sensor streams, graphs, and structured records—has made cross-modal integration critical for modern large-scale data analysis. However, the heterogeneous nature of multimodal sources and the limitations of conventional fusion techniques hinder effective semantic alignment, representation learning, and scalable analytics.
Although large language models (LLMs) offer strong capabilities in reasoning, abstraction, and cross-domain understanding, current data pipelines still lack efficient mechanisms to incorporate LLM-driven semantics into multimodal fusion workflows. This thematic series aims to bridge this gap by exploring innovative approaches that leverage LLMs to enhance multimodal data fusion and enable more powerful, comprehensive data-driven insights.
This collection focuses on advancing LLM-Augmented Multimodal Data Fusion for Large-Scale Data Analysis, encouraging research on:
LLM-enhanced representation learning Semantic alignment across heterogeneous modalities Generative or retrieval-assisted fusion strategies Scalable system designs for real-world applications The goal is to promote new analytical paradigms where LLM-driven intelligence reshapes multimodal integration and utilization in complex scientific and industrial ecosystems.The topics include, but are not limited to:
LLM-augmented cross-modal semantic alignment for large-scale analytics
Generative and retrieval-assisted fusion for multimodal data integration
Representation learning for heterogeneous and multi-source data fusion
Knowledge grounding and reasoning across diverse data modalities
Scalable fusion architectures for large-volume multimodal datasets
Foundation-model-assisted modality completion and data annotation
Graph–text–sensor fusion for scientific and engineering data analysis
Temporal–spatial multimodal fusion for real-world big data applications
Self-supervised learning for multimodal representation and alignment
Benchmarking, datasets, and evaluation protocols for multimodal fusion
Efficient fusion mechanisms for high-dimensional industrial and IoT data
Domain-specific multimodal fusion applications for data-driven intelligence
Publishing Model: Open Access
Deadline: Aug 31, 2026