Improving the repeatability of deep learning models with Monte Carlo dropout
Published in Healthcare & Nursing

Imagine you have an appointment with your dermatologist, whom you trust, and they tell you that a mole on your arm looks malignant and needs to be removed. When you return the next day to have the mole removed, they have another look and say that the mole looks fine. Nothing needs to be done at this time. After such an experience, you would probably start looking for a new dermatologist because you lost trust in their expertise. What was tested in this scenario is a property called test-retest repeatability.
As humans, we know that physiological factors like hunger or distraction can influence our performance and reliability (1). For this reason, it may not sound unreasonable that even experts can change their professional assessment. But what if we had swapped the human dermatologist for an AI algorithm in the scenario above? Diagnostic algorithms are often perceived and advertised as a more reliable and objective alternative to humans. However, even supposedly objective deep learning algorithms can get confused, although by other factors than humans. Empirically, minor changes in an image, like changes in illumination or contrast, can lead to vastly different predictions by deep learning models. Consequently, deep learning models have substantial issues with their test-retest repeatability (2,3). Surprisingly, the repeatability of deep learning models is rarely evaluated.
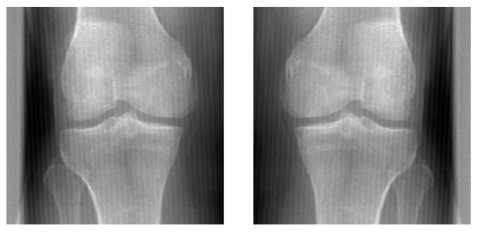
.png "Repeatability of knee osteoarthritis prediction for a selected example")
In Figure 1, we show an example with a low repeatability performance. We used the same deep learning algorithm to predict the severity of knee osteoarthritis (OA) from two X-rays of the same knee. The only difference between the images is that the X-ray on the right is a horizontal flip of the image on the left. The algorithm has been trained to predict the severity of OA on X-rays of left and right knees from the Multicenter Osteoarthritis Study, so we expect this flip not to affect the disease severity. However, the predictions are substantially different – returning, with high confidence, a value of 2 (mild OA) for the left and 0 (normal) for the flipped version of the image. At the same time, an expert labeled the image as a 1 (doubtful). A reliable model should have produced the same prediction with little or no variability between the two images. Consequently, low test-retest repeatability of medical AI algorithms can lead to dangerous medical errors in clinical practice.
Given the importance of developing reliable deep-learning algorithms for medicine, we developed strategies to improve their repeatability. We trained four deep learning algorithms, binary, multi-class, ordinal classification, and regression, with and without Monte Carlo dropout, to classify the severity of knee OA (and three other ordinal classification problems). In Monte Carlo dropout, an approximation to Bayesian neural networks, full activation maps are randomly dropped out during training and test time. Therefore, repeated predictions using the same input correspond to sampling from the approximate posterior. MC dropout is a straightforward approach to prevent models from making over-confident predictions (4).
Through extensive experimental validation, we demonstrated that using Monte Carlo dropout leads to significantly higher repeatability without decreasing and, in some cases, even improving classification performance. We also found that because the severity classes are ordinal, most variability occurred for cases close to the decision boundary between two classes. When we used Monte Carlo dropout to re-train the same architecture, which had resulted in very different predictions for the example in Figure 1, the differences in the predictions between the two images dropped—from 2.01 to 0.09. Additionally, the classification of the MC model agreed with the ground truth label.
The quantitative difference between the predictions for two images from the same patient (e.g., an image and its horizontal flip as above) can be measured using Bland-Altman plots (5). The smaller the interval, within which 95% of all the differences fall, the higher the agreement is between the predictions for test and re-test, i.e., the higher the repeatability of the algorithm. In Figure 2, we show the Bland-Altman plots for eight deep learning algorithms using either conventional training (1st row) or MC dropout (2nd row) trained on the knee X-ray dataset. Moving from the left to the right, each model showed improved repeatability, represented by the lower distance between limits of agreement (the position of the dashed blue lines). Comparing the models between the 1st and 2nd row, the use of Monte Carlo dropout led to a substantial improvement in the repeatability of the predictions.

Figure 2 - Bland Altman plots for different model types. The y-axis of each graph represents the maximum difference in model prediction for images of the same patient, while the x-axis refers to the mean of the predictions. Each dot represents the difference in predictions for one test-retest pair. The further to the left a dot is, the more normal the knee x-ray looks; the further to the right, the worse the signs of knee osteoarthritis present in the image. The 95% limits of agreement are presented with dashed blue lines. Repeatable models are associated with limits of agreement closer to zero, which indicates a smaller difference between test and retest. MC: Monte Carlo.
In our experiments with four medical datasets, repeatability increased significantly for binary, multi-class, and ordinal models when we used Monte Carlo dropout. The improved repeatability was reflected in an average reduction of the 95% limits of agreement by 16%. Furthermore, the classification accuracy improved in most settings along with the repeatability.
In summary, we demonstrated that using Monte Carlo dropout significantly improves the test-retest repeatability of deep learning algorithms. This represents an easy-to-implement solution to the development of robust models that deserve the trust of healthcare professionals and patients.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in