Introducing EUBUCCO - Towards a harmonized European building stock dataset for high-resolution sustainability research
Published in Sustainability

TL;DR:
- We present EUBUCCO, a new dataset containing more than 90% of all buildings in the European Union. Individual buildings can be located and few important characteristics such as their use type is provided.
- This dataset is of relevance for an array of urban sustainability and climate change questions; it permits to develop models both for localized, comparative and aggregated analyses.
- As existing datasets at the EU scale such as OpenStreetMap had important limitations for sustainability use cases, we compiled and harmonized 50 open government datasets that offered the best available data for their regions.
- The process of creating EUBUCCO involved unexpected challenges to identify, understand and harmonize the data, which we documented to help assess the current open data ecosystem and future similar exercises.
- EUBUCCO is aimed to be a common good that keeps on integrating open datasets and enhances them e.g. by filling data gaps with machine learning.
- To ensure our ability to provide high-quality and well-maintained data on the long term, we welcome new contributors and partners.
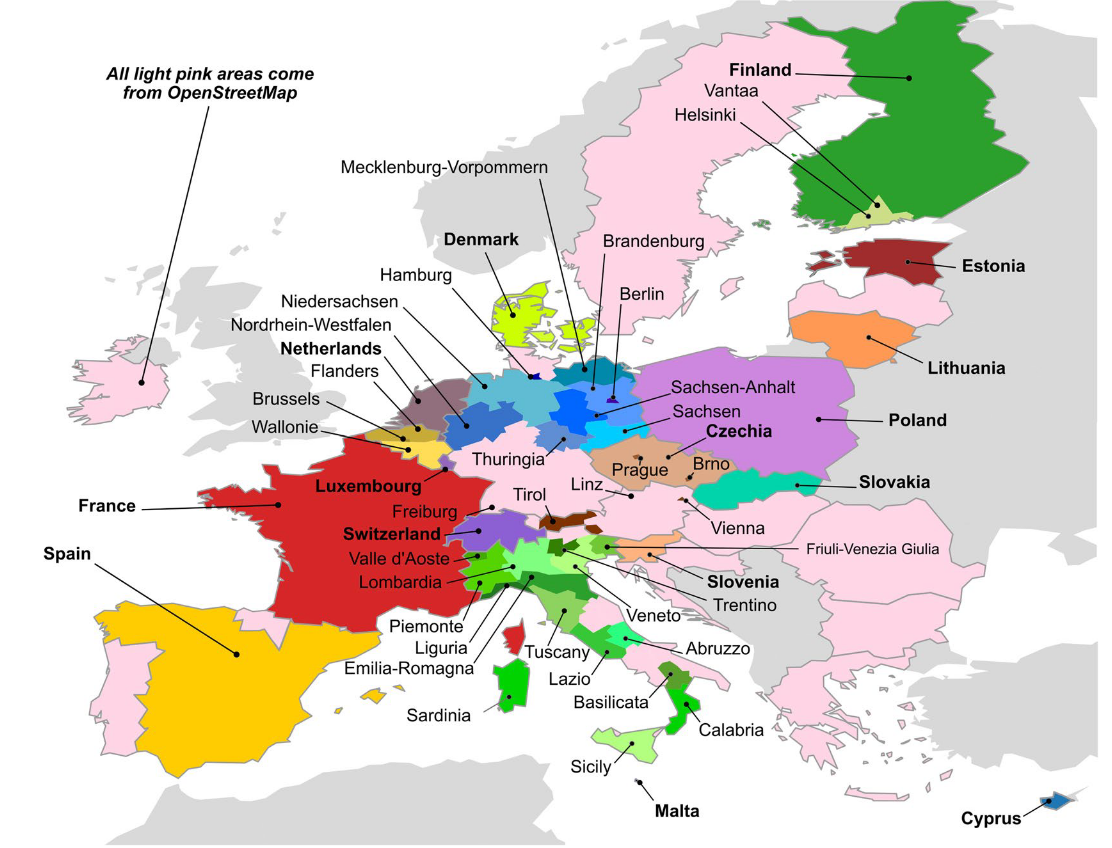
In a recent Data Descriptor published in Scientific Data, we describe the results of a few years of work during which we collected information on more than 200 million individual buildings in the European Union (EU), harmonizing 50 different datasets into a new dataset named EUBUCCO.
What could motivate us to do that?
Our motivation was not the data itself, but the prospect of using it to develop new models that could advance research and policy.
Coming from a climate change mitigation and urban sustainability perspective, we believe that there is a need for new tools that bridge an important gap: breaking down global scenarios from the Intergovernmental Panel on Climate Change community into localized insights that can help policy makers implement the necessary changes; and vice versa, by scaling up local analyses.
Aggregated estimates at a country or continental scale provide important guiding information for global climate change mitigation. But in order to take action on buildings, such as retrofitting policies, detailed maps are needed to take stock of the current situation and identify which buildings, neighborhoods and regions are a priority.
Already at the scale of a city, there are thousands to hundreds of thousands of buildings; EU countries have millions of buildings – hard to know where to start.
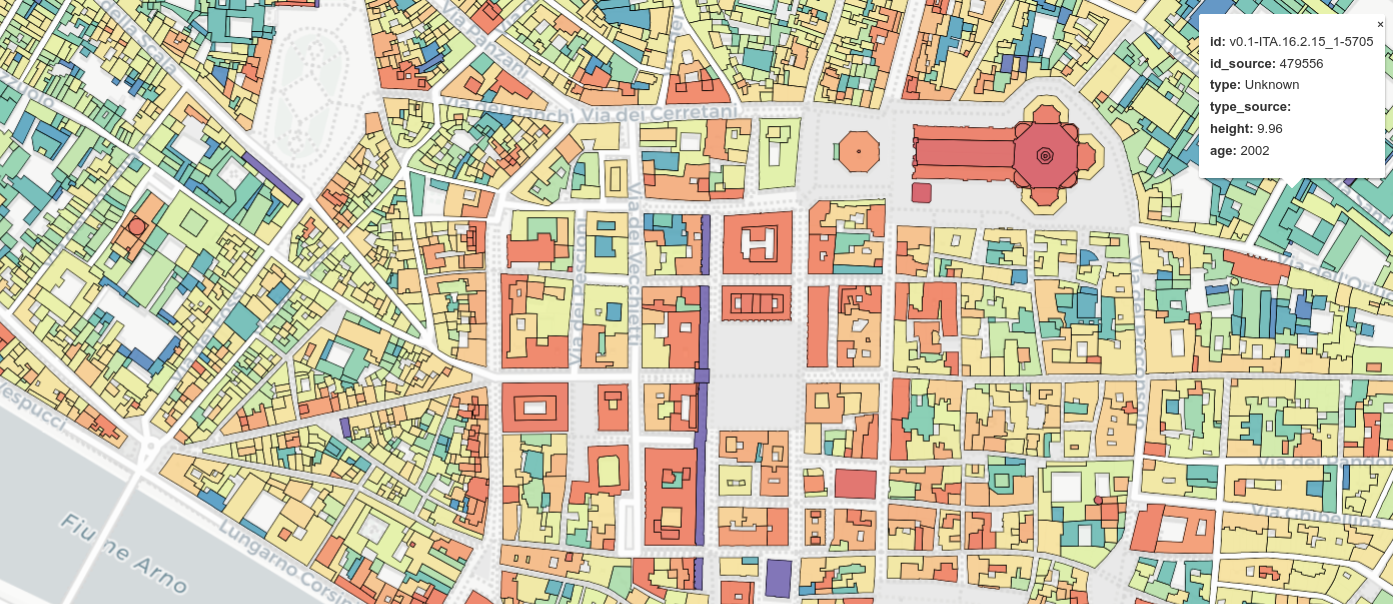
Unlocking the potential of open government data
The advent of large-scale open geospatial data on buildings like OpenStreetMap made us excited that we could now build such new tools.
Indeed, OpenStreetMap contains in one single dataset easily and openly accessible the geolocalized footprint of millions of buildings and a myriad of possible other characteristics. This seemed like the perfect input for modeling building stock across scales, from cities to countries, and even to the continental level, which was demonstrated since then in several publications [1,2].
But we soon figured out that OpenStreetMap was not a sufficient source of information for our use case, retrofit policies, because many buildings were still missing from the map in various regions of the EU, and because crucial information like their height or age was available for only a tiny fraction of them.
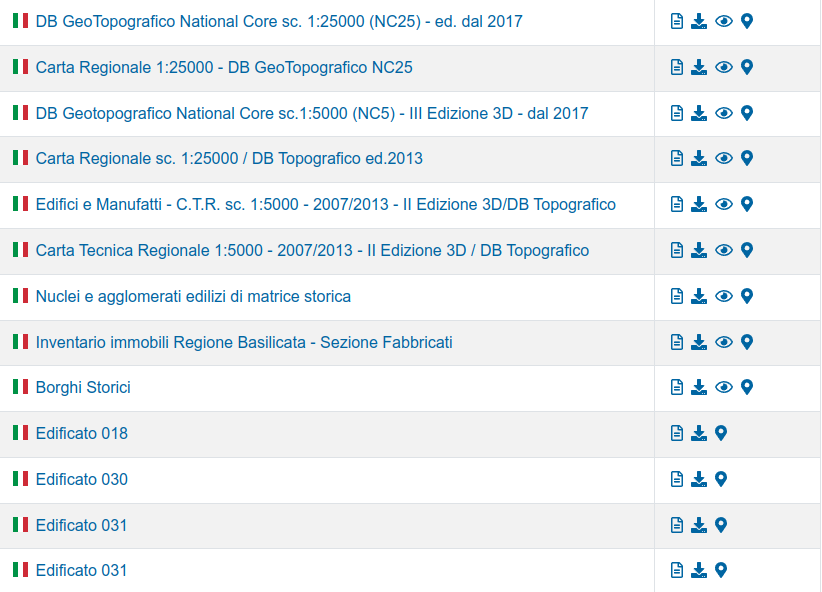
We dug deeper, looking at various resources, such as the INSPIRE geoportal, and realized that there was a wealth of data available in the EU that seemed to have been under-utilized for sustainability research. Summing up all these datasets together, we could get close to a complete coverage of the EU building stock with much more information than OpenStreetMap.
Most of these datasets originated from local governments, sometimes countries, regions or even individual cities. Despite existing frameworks for harmonizing such data, each actor generated and published their own data, and the formats could differ dramatically.
At this point, we realized that the data gathering work involved was not just a step of a modeling paper, but that we needed to build a new dataset first.
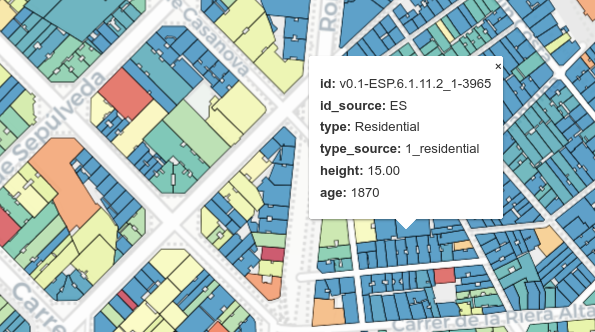
The winding road to a harmonized dataset
Building this dataset still appeared to be a relatively straightforward task: first compiling available data sources, then downloading, parsing, harmonizing, and releasing the data – easy? One year of tedious data engineering work later, we realized that creating a database is far more challenging than expected.
Each step of our workflow incorporated unexpected challenges:
The first step – finding datasets – turned out to be very difficult due to language barriers and non-harmonized naming conventions. On top, data were often hidden behind confusing paywalls (that sometimes requested a fortune even for research purposes) and varied arbitrarily between countries or states.
The downloading step was equally challenging, as every authority that publishes data decides about how one can access it. Consequently, we encountered everything from easy-to-use platforms, where one click downloads all data, to complex APIs or tiling windows in interactive map viewers, where only few samples could be downloaded at once – we had not signed up for a PhD in web scraping! Similarly, user support ranged from very competent (such as in Poland), to cases where little help could be provided (e.g. if the service had not been developed in-house).
Once we had collected all the data, the harmonization began. We were surprised by how much computing it required to process the data. We could only manage this thanks to the high-performance computing infrastructure of our partner, the Potsdam Institute for Climate Impact Research.
Finally, we had to overcome a last challenge: finding, understanding, and assessing the license compatibility of our data sources, and defining a licensing strategy to release them together. Although ultimately most datasets had been released with liberal licenses, we often felt we were looking for a needle in a haystack.
All these challenges for users definitely impede a broader usage of the data. We do not want to sound too critical though: it is already great that there has been so many efforts to make data available to anyone. With EUBUCCO, we are hoping to enable more people to know about these data and access them easily; however, it would certainly be beneficial that further harmonization processes, e.g. of metadata or download procedures, happens upstream, possibly orchestrated by regional actors like the EU.
Next challenges towards an improved and perennial EUBUCCO
EUBUCCO’s journey does not stop with its publication and there are many next steps that we could think of.
The first logical one is the wish to see use cases realizing the final potential of the dataset. We are currently working on a couple of papers going in this direction. We are also hoping to see other scientists utilize EUBUCCO to conduct high-resolution urban sustainability studies on a continental, comparative, or local scale.
Some use cases however may require improvements of the dataset. Indeed, the current version of EUBUCCO has multiple limitations including a substantial share of footprints or attributes lacking in certain regions, which could be added via new data ingestions or inferred with machine learning [3]. Further analysis and cleaning of the data would also be beneficial. While there are identified solutions for most of these problems, they each require months of work.
Thus, as we are hoping to make EUBUCCO a perennial common good for academics and further users interested in the European building stock, we are welcoming new partners and contributors to increase our capacity to maintain and improve the dataset. This would increase our common ability to ensure that EUBUCCO can be an increasingly useful and easy-to-use resource that remains maintained on the long run.
EUBUCCO was developed as an integrator and we are hopeful that many new resources will soon be released that can improve EUBUCCO. For example, the Microsoft GlobalMLBuildingFootprints dataset that was released recently now enables to get close to 100% coverage of footprints. The new Implementing Act on High-Value Datasets of the EU Open Data Directive mandates member countries to publish their building data free of charge under open licenses, make them available through APIs and when relevant bulk download. This initiative should increase the availability attributes such as number of floors and the type of use in the coming years.
All the work that went into making this database will be amplified by each reuse, so please explore the data, use it and reach out to us if you want to chat about it!
References
[1] Haberl, Helmut, et al. "High-resolution maps of material stocks in buildings and infrastructures in Austria and Germany." Environmental science & technology 55.5 (2021): 3368-3379.
[2] Moran, Daniel, et al. "Estimating CO2 emissions for 108 000 European cities." Earth System Science Data 14.2 (2022): 845-864.
[3] Milojevic-Dupont, Nikola, et al. "Learning from urban form to predict building heights." PLOS One 15.12 (2020): e0242010.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

What are SDG Topics?
An introduction to Sustainable Development Goals (SDGs) Topics and their role in highlighting sustainable development research.
Continue reading announcementRelated Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Wearable and Computer Vision Data for Health and Behaviour Research
Publishing Model: Open Access
Deadline: Aug 08, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in