Predicting motivation and pleasure with smartphone keyboard typing
Published in Healthcare & Nursing, Public Health, and Behavioural Sciences & Psychology

Explore the Research
Smartphone keyboard dynamics predict affect in suicidal ideation - npj Digital Medicine
npj Digital Medicine - Smartphone keyboard dynamics predict affect in suicidal ideation
My supervisor, Prof Alex Leow, is an avid amateur pianist. One day, whilst she was playing the piano, she realised something: On days where she felt particularly good, her piano play was a lot better. Conversely, if she had had a bad day, her play would be considerably worse. She kept thinking. Being a psychiatrist, she knew how little one visit could tell about her patients’ day-to-day wellbeing. Going to a psychiatrist can be a nerve-racking experience, and it can be quite hard to think of all the ways you have felt over the past few weeks, let alone convey that during the conversation. Not to mention the costs! Wouldn’t it be great if we could somehow use these piano keyboard dynamics to gauge someone’s mental wellbeing?

This is how the iOS app BiAffect was born. Not being a piano, a phone is much easier to carry around and has many sensors that make it suitable for collecting information about someone’s behaviour. BiAffect replaces the standard iOS keyboard and collects information like typing speed, autocorrect rate, and phone movement while typing. Important to note is that it only collects how you type, not what you type.
Still, it's surprising how much information we can extract from just your typing dynamics. We’ve found that, on average, people have the slowest typing speeds in the morning and the evening, when they are probably groggy or tired. In the afternoon, on the other hand, we see a considerable speed-up! On top of that, phone movement and autocorrect rates have been shown to predict depression and mania ratings. It seems then that measuring someone’s behaviour through digital devices is very promising for supporting healthcare, and there are now many different apps (Beiwe, mindLAMP, Behapp, etc.) that try to do the same. We call the collection and analysis of these measurements digital phenotyping.

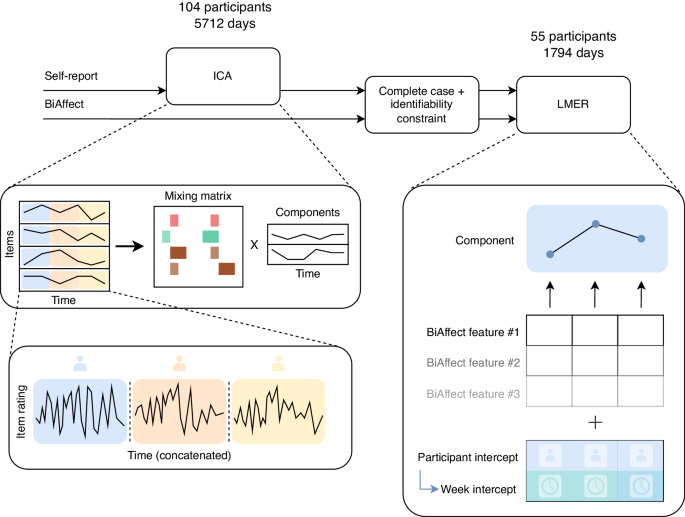
However, although the collection of all these kinds of data from your phone sounds great, in practice it can be quite difficult. Take a look at Figure 1. It shows the measurements we took for three different data types: The accelerometer sensor, the BiAffect keyboard, and some questionnaire items that the study participants responded to in their own time (hence the name ‘self-report’). It is clear that the measurements for one data type are much denser than for the others and that they don’t necessarily align. In addition, for every questionnaire measurement, we could be asking many different questions. We refer to the number of questionnaire items as the dimensionality of the self-report data type. If we’d like to predict the questionnaire answers from the BiAffect data, then unaligned measures and high dimensionality (i.e., many questions) can make the predictions very hard.
We have chosen the following approach to tackle these issues: 1) we reduce the dimensionality of the questionnaire data through something called an independent component analysis, 2) we average all measures within a data type to the same time unit (for instance, one day), and 3) we use statistical models to predict one data type from the other. We have tested our approach using data from the CLEAR-3 study.
The CLEAR-3 study is a clinical trial that tests a hormonal treatment for diminishing suicidal thoughts in women*, as some women experience an increase in suicidality surrounding their menstruation. Before treatment started, however, the participants were already using BiAffect and answering over a hundred questionnaire items on a daily basis. These items ranged from “I thought it would be better if I was not alive” to “I felt hopeless” and “I felt happy”. We used a subset of 34 items from this pre-treatment period.

It is this 34-item subset we will be feeding to the independent component analysis. Consider this analysis as some sort of image JPEG compression, in which we try to reduce the image data size whilst retaining as much of the original information as possible. The more aggressive the compression, the more information we lose but also the smaller the file size. With independent component analysis, we can instead pick a number of components such that fewer components means more information loss. We have decided to go with five components for our study but have also repeated our analyses with ten and twenty components. These five components can be characterised by how much they contribute to the original 34 items, which is shown in Figure 2.
There is a lot to unpack here, but I’ll walk you through. The y-axis contains shorthands for the 34 items the participants have rated. Their bars are coloured according to the clinical questionnaire from which they originated, which you can find on the right-hand side. The x-axis specifies the loading of every item on the components, which is the degree to which a component contributes to the original item measure. The higher the absolute loading, the more opaque the bar colour. Every column gives the loadings for that independent component (IC). The components that are the most striking are IC 1, with strong loadings for FeltConnected, FeltCapable, and FeltHappy, and IC 2, which has strong loadings for LackingInterest, Anhedonia (inability to experience pleasure), and Unmotivated. We’ve called IC 1 the well-being component, and IC 2 the anhedonia component.
Finally, after the independent component analysis, we were ready to link the questionnaire data type (the components) to the BiAffect data type. To our excitement, we found that phone movement strongly predicted IC 2, the anhedonia component, in that more phone movement predicted less anhedonia! A possible explanation for this finding would be that when you’re feeling energetic you will be doing more things and moving around more, even when you’re typing on your phone. Other explanations might also be possible, but personally I think this is the most plausible.
In conclusion, our method was successful in linking all the unaligned data types. Although we were very happy with the results we found with the CLEAR-3 data, it is important to note that our method is set up to be general enough to also apply to data from other studies, possibly involving different apps. We hope that it will contribute to better digital support apps for mental healthcare and in the long term improve the lives of those people that struggle with mental health issues on a daily basis.
* When I say women, I actually mean people that were assigned the female sex at birth. After all, not everyone that was born as a woman still identifies as one. The most important requirement for the CLEAR-3 study, however, is that the participants menstruate.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in