Rankings, they all look the same to me
Published in Social Sciences
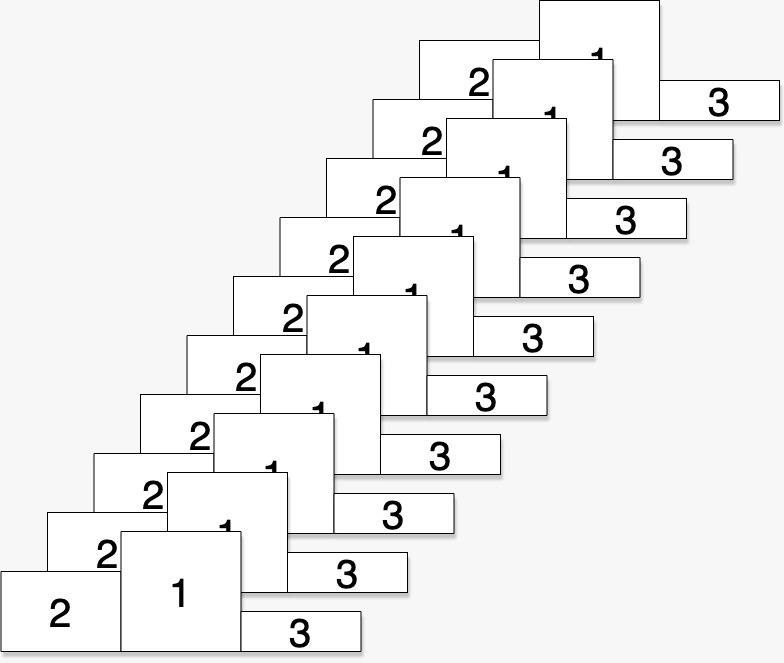

Have you ever wondered why rankings behave so similarly across the board? Why people, institutions, and cities, once they make it to the top, seem to stay there for a long time? Maybe it’s the Williams sisters achieving Grand Slams non-stop. Or Apple and Walmart grabbing Fortune 500 prime spots for years in a row. Harvard has been Harvard for a while now. And we won’t stop using the English word ‘the’ anytime soon.
But as we go down the ranking, things become more hectic; Fads come and go, bringing their somewhat popular hashtags in and out of Twitter’s trending topics. Some of last year’s most innovative startups don’t make headlines today, and the race for the world’s 357th best chess player is somewhat less predictable than for the 1st. The stability of a thing’s position within a ranking depends on how close it is to the top, whether that thing is a person, a web page, or a country. Why?
I’ve always been fascinated by the central limit theorem. The idea that, if you take many (uncorrelated) random variables, their sum will always be distributed like a Gaussian, as long as their variance is finite, and crucially, regardless of how each one is distributed. It suggests that aggregate phenomena in the real world can have similar statistical properties, even when their microscopic dynamics are different. Physicists love these things. Examples are the critical exponents characterizing phase transitions in entire universality classes of physical systems, the similarly broad-tailed distributions of socio-technical and biological networks, and the power-law decay of a property (say, the size of a city) with rank, otherwise known as Zipf’s law.
Sometimes simple models, even those driven by random processes, are enough to capture the large-scale structure of seemingly complicated phenomena across disciplines. Is this also the case for the temporal stability of rankings?
So we rolled up our sleeves and went around looking for data on ordered things. Many ordered things. Some rankings were centuries long, like the yearly written frequency of hundreds of thousands of words in 6 languages since the 1600s, or really granular in time, like the number of commuters in 636 entrances to the London Tube every 15m during a week. Some had little to do with humans, like the ranking of regions in Japan by monthly number of quakes, or the social hierarchy of hundreds of hyenas during 23 years. We got rankings of natural, social, economic, and infrastructural systems, with data on people, animals, languages, regions, institutions, transports, websites, and sports.
We then measured temporal stability as the probability that an element will change rank between two observations in the data. Turns out rank change is low at the top of a ranking, steadily increasing as we go down the list. But alas! At the bottom things get funky. If there’s lots of elements going in and out of the system (think commenters on a website), rank change will keep increasing, yet if this flux is low, the bottom will be as stable as the top. Coders’ least favorite repo on Github is anyone’s guess, but predicting the smallest city in the UK is as sure a bet as saying London will still be huge next year. The stability of a ranking somehow depends on how open or closed that system is. And this holds whether we rank tennis players, hyenas, or millionaires. Cool, right?
Still, we’re physicists! Not only data analysts! We knew we needed a model. So we put our Occam’s fan caps on and looked for something really simple. Something based on random mechanisms. A sort of null model, if you will, to test the hypothesis that nothing really system-specific is going on.
In our model, elements get displaced to any other rank, or get replaced by a new element, both uniformly at random and at a constant rate. Math happens and we end up with a diffusion-ish equation for the way things move across the ranking, which looks remarkably like the Wright-Fisher equation of random genetic drift (is it just me, or that’s just plain curious?). After fitting the model to data and smartly rescaling parameters, datasets collapse onto a power law. Real-world rankings, it turns out, lie somewhere in a spectrum characterized by inversely proportional quantities of element displacement and replacement, regardless of the system’s details.
Of course, rankings are not exactly the same, not really. For most datasets the flux of elements into the list is remarkably constant in time, but for word rankings it goes down, probably due to variations in data sampling and cultural shifts on the scale of centuries. And financial crises briefly decrease the overall stability of the Fortune 500 list and the ranking of countries by economic complexity, even at the top.
What’s surprising to me is that they’re this similar, that despite obvious differences in the mechanisms driving academic excellence and tectonic activity, once we jump into rank space and care only about lists of ordered things, common patterns of temporal stability do appear. Given how intertwined rankings are to the way we allocate resources in modern society (jobs, grants, procurements, and so on), maybe it’s worth noticing that their dynamics can be captured simply by random rank change. Maybe choosing rankings, with their naturally stable tops, as go-to signals of excellence, is not the best way to push against systematic inequality and the entrenchment of elites.
So what’s next? Well, models can always be refined. Explicitly considering the often networked dynamics driving a ranking might explain deviations from the model’s predictions. And the link between element turnover and ranking stability could help us figure out why resources tend to be unevenly distributed in competitive environments, a useful insight if we want better algorithmic rating tools. A bit down speculation road, if open systems have a stable core of essential elements (providing robustness), and a bunch of changeable but less crucial components (giving adaptivity), then maybe complex systems need little to be evolvable beyond random variation and heterogeneous timescales.
Thinking about it, if rankings do indeed have this particular flavor of predictability, maybe I should finally give fantasy football a go.
I'm associate professor in complex systems at the Faculty of Information Technology and Communication Sciences of Tampere University. I'm also visiting professor at the Department of Network and Data Science of Central European University (Austria), the Department of Computer Science of Aalto University (Finland), and at the Center of Complexity Science of UNAM (Mexico). On the industry side, I'm CEO & co-founder at Predify (Mexico).
I'm also Associate Editor in Complex Networks and Review Editor in Complex Physical Systems at Frontiers, and member of the European Humane AI Net project.
The researcher in me likes complex systems, networks, computational social science, and data science. I also write fiction (sci-fi, fantasy, and weirder) and co-develop videogames on the side Find out more on my website at: www.gerardoiniguez.com
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026
Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in