Reinforcement learning with memristor-based hybrid analog-digital computing platform
Published in Electrical & Electronic Engineering

The unprecedented progressing of artificial intelligence (AI) might be reflected by the games that computers could master. In 2013, the deep-Q reinforcement learning surpassed human professionals in Atari 2600 games. Since 2015, AlphaGo, trained by supervised learning from human expert moves and reinforcement learning from self-play, beat several champions of the 2500-year-old Go game. AlphaGo Zero, trained solely by reinforcement learning, defeated AlphaGo 100 times in 100 games in 2017. Very recently, AlphaStar, empowered by a multi-agent reinforcement learning environment, defeated human top players on extremely complicated strategic game StarCraft. Not only games, the power of the reinforcement learning opens the way to future machines that can assist and may even replace human beings in most daily works.
A more powerful AI cannot live without a more powerful computer. In this data-centric era, the traditional digital computers are extensively challenged because the processing unit and the main memory are physically apart. This is like a person playing the Go game with a manual. Because he cannot remember everything of the manual, he must check it and update it regularly which consumes both time and energy. A natural solution to this challenge is to perform learning at where the data are stored. Fortunately, this has recently been enabled by memristors.
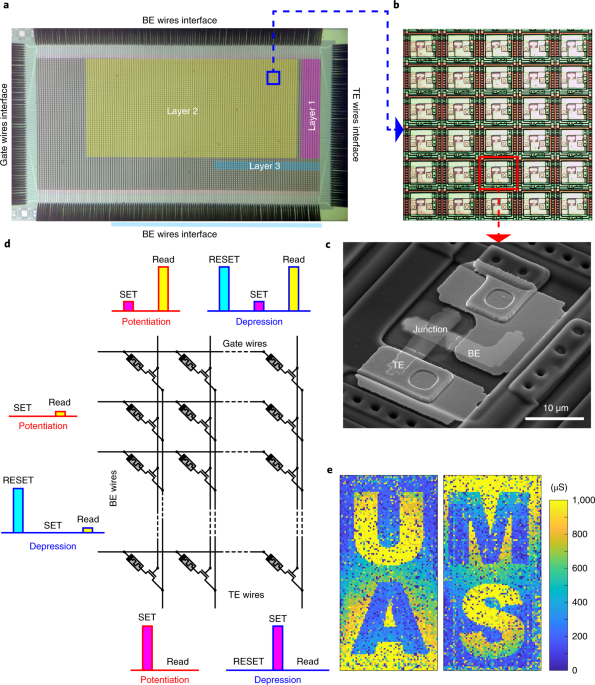
In our work, we report the experimental demonstration of deep-Q reinforcement learning with the neural network physically built on more than 5000 memristors. Since memristors are essentially variable resistors, they could “memorize” or store the weights of the neural network. On the other hand, Ohm’s law and Kirchhoff’s current law make the crossbar capable to perform linear transformations of the neural network at where the weights are stored, unlike moving data between the DRAM and the caches of processing units back and forth in a digital computer.
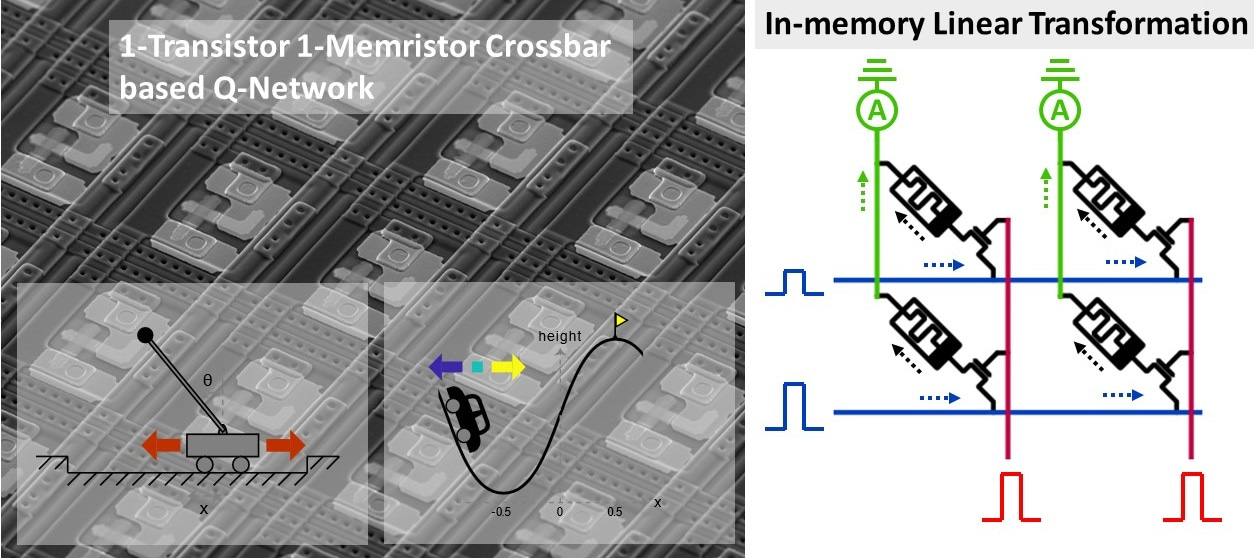
Robust in situ deep-Q reinforcement learning has been observed on our hybrid analog-digital computing platform with transistor-based neurons, showing fast and accurate memristor programming. We also reveal such memristor-based reinforcement learning provides a general platform which can solve classical control problems like cart-pole and mountain car. The potential boost of the speed-energy efficiency, together with the decent scalability and stack-ability of memristors, makes our reinforcement learning system attractive to the development of the future intelligent systems that demands both performance and portability.
Our work is published on Nature Electronics, at the link https://www.nature.com/articles/s41928-019-0221-6
Follow the Topic
-
Nature Electronics
This journal publishes both fundamental and applied research across all areas of electronics, from the study of novel phenomena and devices, to the design, construction and wider application of electronic circuits.


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in