
“There is an increasingly overwhelming amount of single-cell data becoming available, with expansions in both the variety of biological samples being analyzed and the number of single-cell bioanalytical methods (scRNA-seq, scATAC-seq, etc). In the course of developing a generalized encoder tool/algo to manage data integration and removing batch effects from X and Y data that we named SCALEX, we spotted an exciting opportunity to achieve the integration of new (i.e., ongoing, incoming) data new data into an established cell atlas without the need for model retraining.”
Disentangling biological and batch-related variations using an asymmetric autoencoder
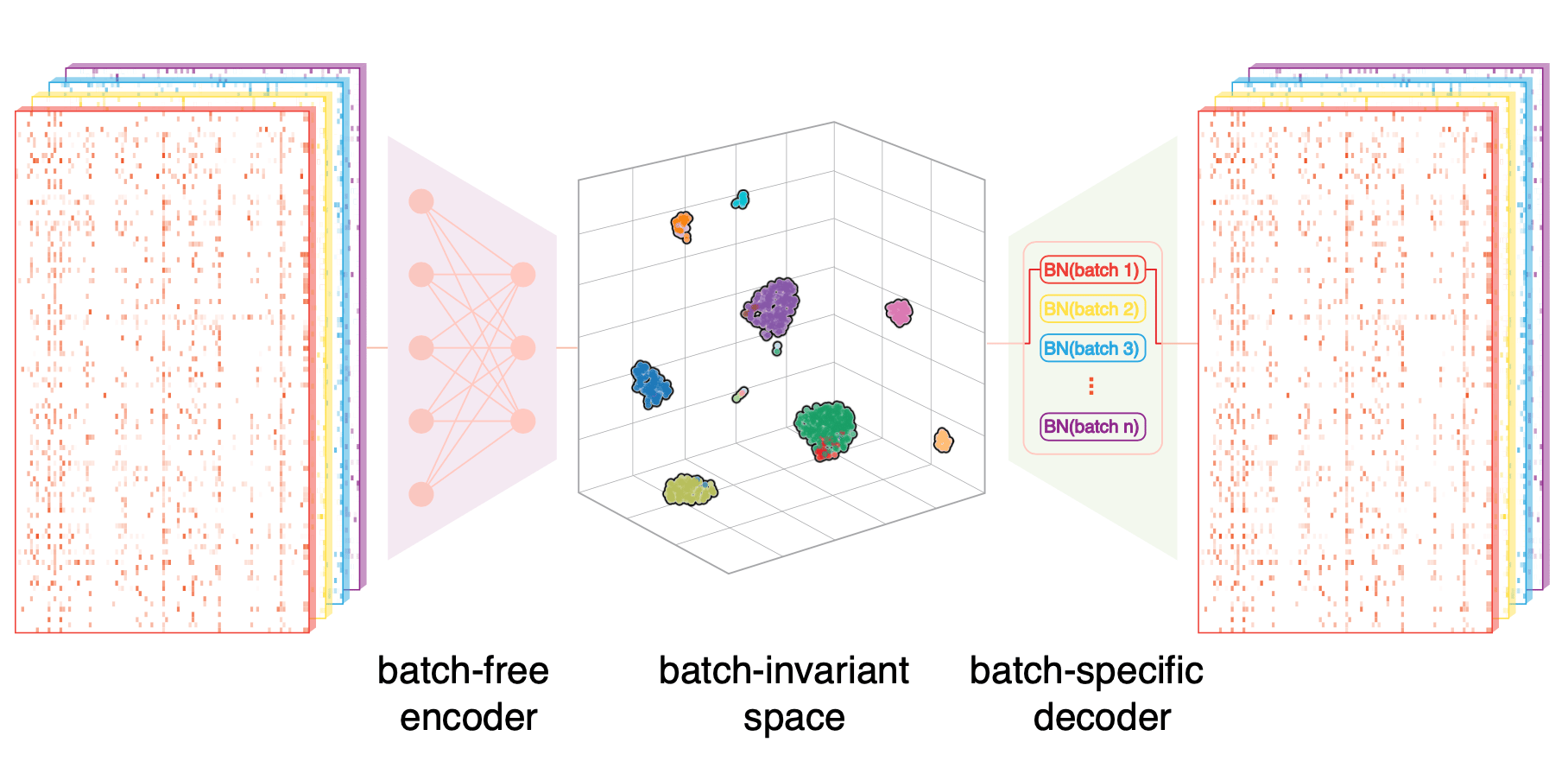
SCALEX was designed to learn a generalized encoder that is immune to various batch-effects: this design was based on our basic hypothesis that only biological variations would be universal to all kinds of batch-effects. When thinking about suitable strategies for learning this hypothetical generalized encoder, we were inspired by our experience during our previous development of a tool we named “SCALE”. Briefly, we had noted that that the batch-related features captured by SCALE1 are disentangled, so we thought: why not disentangle these batch-related features and let them learned by the decoder. After a lot of tinkering around, we ultimately developed the current asymmetric autoencoder framework at the heart of SCALEX2, wherein the encoder is batch-free, while the decoder is batch-specific Fig 1.
However, the simple fact of having an asymmetric autoencoder does not guarantee that the model will behave in the way as we planned. Always keeping it in mind to learn a generalized encoder, we try to keep the encoder stay in an batch-free environment. At the same time, we adopted the DSBN3, which is effective in the domain adaptation field, in the decoder to make it function like different channels manipulating the batch-related variations.
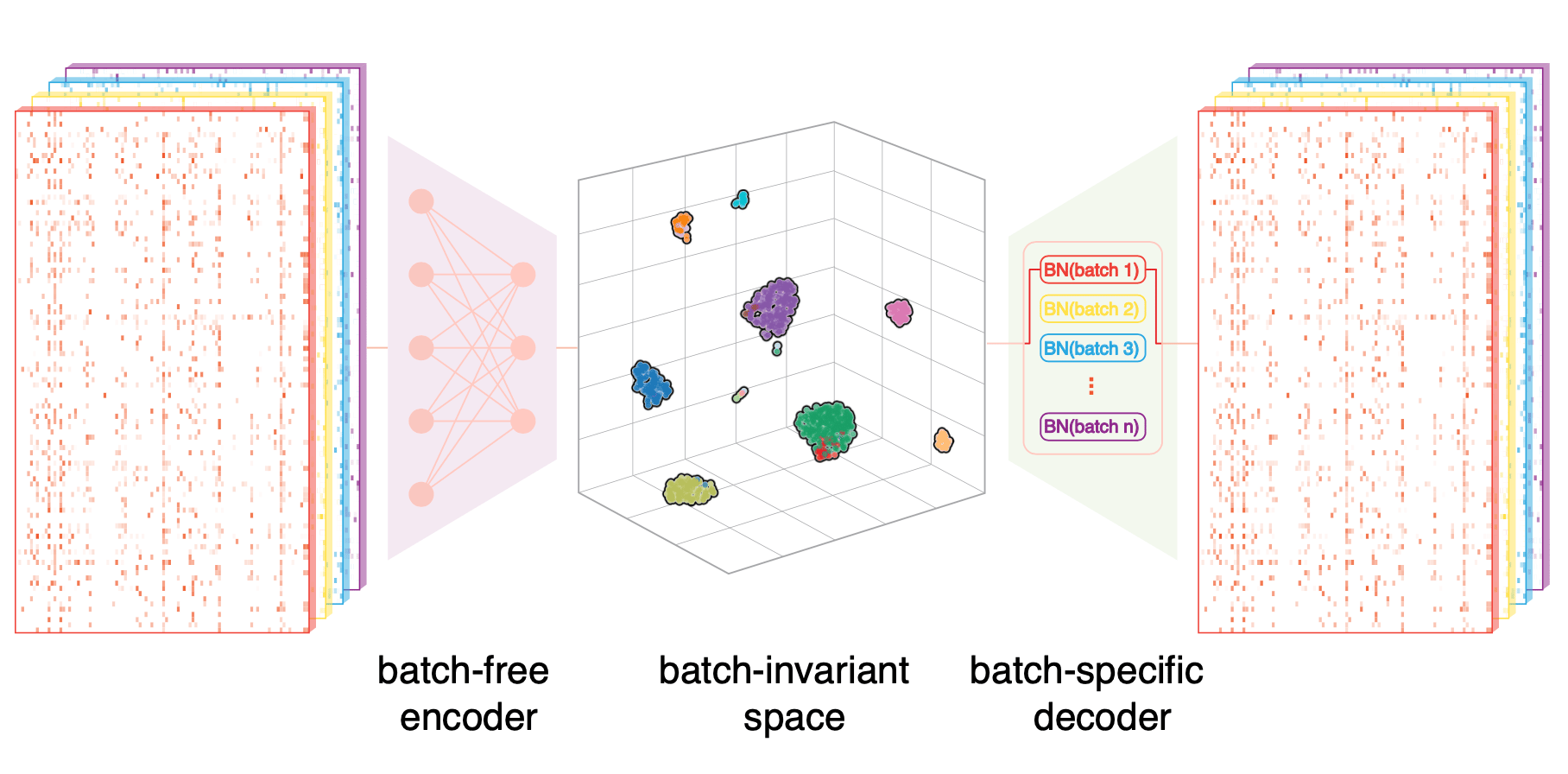
Fig 1. The design of SCALEX. A generalized encoder projects heterogeneous sources of data onto the “biology-preserved” cell embedding space, while a batch-specific decoder is responsible for batch-related variations in variational autoencoder4 framework.
We didn’t come to realize that batch-normalization is a “special sauce” that helps remove the batch effects until we came across two interesting accidents. For the first of these, we found that the performance dropped a lot in an updated implementation and we could not reproduce integration effect perfectly; we therefore checked the problem out for several weeks and in the end found that this was due to accidentally removing the batch-normalization in the encoder. The second accident is that we found the prototype SCALEX ran much worse on evaluation than on training. The only difference between training and evaluation is that the data is shuffled during training processing but not during evaluation. Later we found that for each dataset the samples are sorted by cell-types, which introduced variances (albeit extremely small ones) among the same batch, thus causing the batch-normalization process to collapse. In a sense, all of this taught us to be grateful when meeting vexing trouble, because exploring these problems led us towards the core factors that really “move the needle” with these tools.
Indeed, these troubles forced us to start thinking about precisely how the model works. The most plausible explanation we came up with is that there is a biological distribution that must informatively represent the latent ground truth. By minimizing the KL divergence loss to reduce the “distances” among distributions of different batch effects, every batch-size of data sampled from the mixed distribution of different batches is going to align towards the ground truth distribution in the optimization process. In a sense, the batch-normalization thus serves as a scissor, smoothing out the uneven distribution reflecting batch variations. And the reconstruction loss function uses the latent representations to capture variations; that is, the biological variations from the raw data distributions.
Online integration enables in silico cell atlas building
An ability for online data integration, which enables a trained model to be directly applied to new datasets without retraining, is an attractive aspect of deep generative models. As noted in the framing content in the beginning, the number of new incoming single-cell datasets is currently expanding very rapidly. We were interested in how we could incorporate these into existing datasets and in how we might be able to harness prior knowledge obtained from existing datasets to new data? Approaching this, we decide to use a cell atlas as a reference. Since we already trained a generalized encoder, we started to think about using the generalized encoder to incorporate new data (Nota Bene: without retraining) to build in silico cell atlases.
We reasoned that to fulfill the online integration task, the model should have two abilities: it should align the overlapped cells accurately in the new datasets and should also be able to increase the scope of the existing cell space by projecting the non-overlapped cells in a reasonable location in the cell space of the atlas. Pursuing this, we first validated the alignment performance using the pancreas datasets, and then collected three new pancreas datasets obtained using different bioanalytical protocols as test datasets (that is, beyond the five well-studied pancreas datasets that we trained SCALEX with/on).
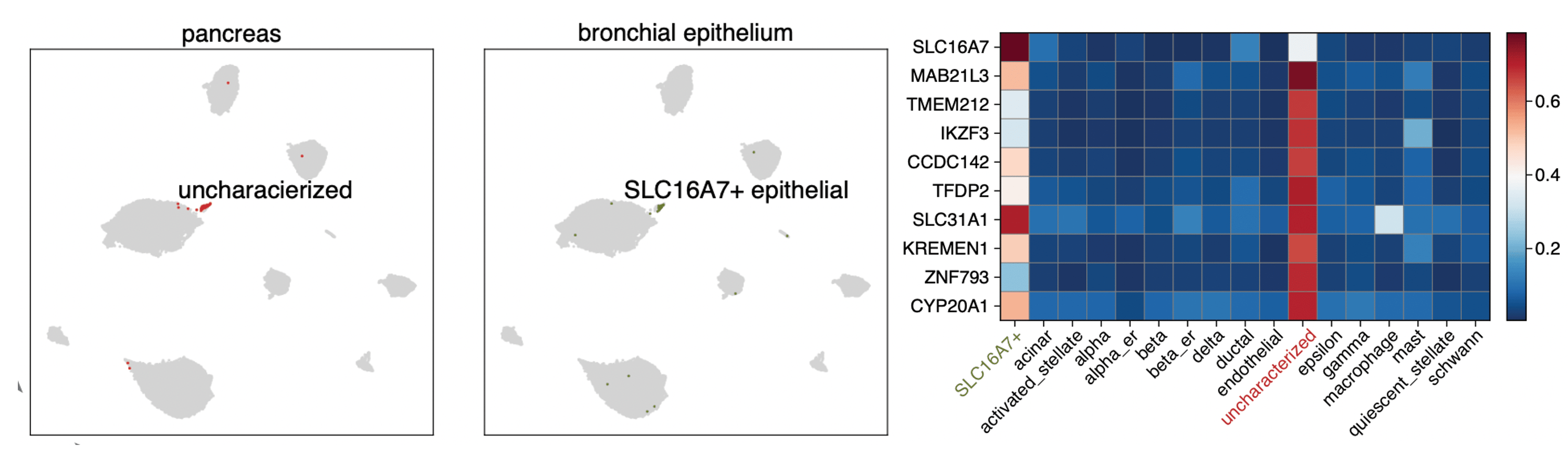
Fig 2. Left and middle, UMAP embedding/projection of uncharacterized cells in pancreas and SLC16A7+ epithelial (epithelial cells expressing gene SLC16A7 specifically and high level) under SCALEX online integration. Right, Top 10 differential expressed genes of the uncharacterized cells.
Upon using the generalized encoder to project/whatever the new datasets, it was exciting when we found a new cluster of cells in pancreas datasets displaying the high expression levels of known epithelial cells. We then assembled a collection of epithelial cells and project them to the pancreas cell space. found the found SLC16A7+ epithelial cells from bronchial epithelium, a very different datasets from pancreas, also expressed the similar gene expression. Strikingly, we found these epithelial cells consistently mapped with the new identified clusters Fig 2. We anticipate that in the future there will be many such discoveries of shared rare cell types among diverse sample types enabled through SCALEX-based online integration to bridging heterogeneous datasets.
After confirming that bona fide new cell types are projected to locations in the existing cell space, we built a variety of in silico cell atlases. It was quite tedious to unify the various annotations from multiple atlas datasets, but in the end we successfully built a mouse atlas, a human atlas, and a COVID-19 atlas Fig 3 for which we continuously incorporated the then-newest datasets. We invite the the single-cell research community to start contributing this type of continuously updated atlas-level reference resources by using SCALEX’s online integration ability.
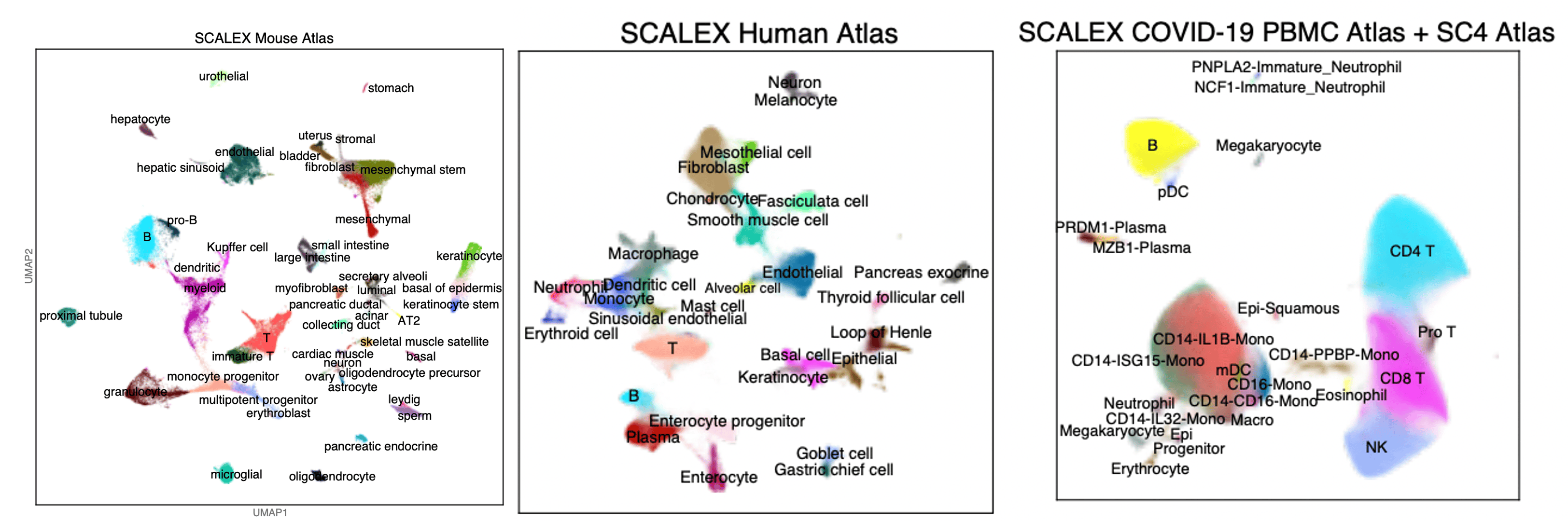
Fig 3. UMAP embedding/projection of a Mouse Atlas, a Human Atlas, and a COVID-19 Atlas built using SCALEX.
1 Xiong, L. et al. SCALE method for single-cell ATAC-seq analysis via latent feature extraction. Nat Commun 10, 4576 (2019). https://doi.org:10.1038/s41467-019-12630-7
2 Xiong, L. et al. Online single-cell data integration through projecting heterogeneous datasets into a common cell-embedding space. Nature Communications 13, 6118 (2022). https://doi.org:10.1038/s41467-022-33758-z
3 Chang, W.-G., You, T., Seo, S., Kwak, S. & Han, B. Domain-Specific Batch Normalization for Unsupervised Domain Adaptation. arXiv:1906.03950 (2019).
4 Kingma, D. P. & Welling, M. Auto-Encoding Variational Bayes. arXiv:1312.6114 (2013).
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in