Seismic data compression: Methods, challenges and future directions
Published in Earth & Environment, Electrical & Electronic Engineering, and Computational Sciences

Compression is crucial for seismic data, which is usually voluminous, to make storage, transmission, processing, and interpretation easier, faster, and more efficient. Our survey paper provides a comprehensive reference with a holistic overview of concepts, datasets, techniques, challenges, and future directions related to seismic data compression over the last five decades. Only some findings and conclusions are presented in this blog post. Details are provided in the full-text access paper.
Context and application fields
In the exploration of petroleum and gas, Seismic Data (SD) play a crucial role in extracting pertinent geological information required for identifying hydrocarbon deposits and reservoirs, as well as optimizing operational efficiency post-production. To mitigate the substantial expenses associated with exploration drilling, which can reach hundreds of millions of euros, the oil and gas sector dedicates significant efforts to sustain and advance the seismic data domain. This encompasses activities ranging from seismic wave propagation and acquisition to the processing and interpretation of resultant data. The applications of seismic exploitation extend beyond the mentioned fields, influencing various multidisciplinary fields, particularly those related to geoscience such as sedimentology and paleontology.
Despite their significance, seismic data are notably voluminous, and this volume is becoming increasingly important as these data are increasingly perceived as precise representations of subsurface physics. This is particularly evident in higher-dimensional seismic trace cubes, which pose challenges in terms of storage, transmission, interpretation, and exploitation due to their considerable size. To address this issue, numerous compression methods have been proposed to reduce the size of seismic data while preserving their spatial representation and physical properties of the subsurface. These properties are exploited by geologists, geophysicists, and reservoir engineers for structural and stratigraphic interpretation, i.e., the spatial arrangement of rocks, as well as lithological interpretation, i.e., the nature of rocks.
Sesimic data features
SD include spatial representation of subsurface physical properties, and discontinuities that are sensitive visual information. These data can manifest in four potential dimensions, corresponding to the manner in which the collected data are obtained. Initially, 1D SD consist of seismic traces exploring subsurface properties, such as resistivity and velocity, beneath a specific location while going far from the Earth's surface. The limitations of 1D seismic traces become apparent with the advent of 2D surveys, widely employed in the petroleum industry since the 1920s. These surveys entail multiple measurement points recorded simultaneously along a profile. However, the provided seismic information remains static, rendering time-dependent tasks, like reservoir surveillance, unfeasible due to the absence of measurements acquired at different times to capture subsurface changes. With the increasing density of geophones in seismic acquisition, 1D traces are consolidated to create 2D seismic gathers, as illustrated in the following figure, exploiting the strong correlation between data from adjacent sensors. Seismic gathers represent adjacent displays of seismic 1D traces originating from the same or different sensors that share certain acquisition parameters. The traces and time sample indices are considered as 2D spatial coordinates. Although acquiring the time-dependent subsurface features, in-depth acquisitions are still not possible with 2D seismic gathers. This is, though, possible with 3D SD that were pioneered in petroleum industry in 1970s. 3D SD can be represented as seismic cubes, with dimensions related to the geometry of the seismic acquisition. These dimensions are commonly denoted as "inline" in the acquisition direction and "crossline" in the perpendicular one. Depending on the domain in which the data are represented, the third dimension corresponds to depth Z or time t of the source-refector-receiver path. As shown in the next figure, 3D SD can also be presented in 2D format by extracting slices from the 3D cube. These latter can be reassembled in the format of a video. Thereafter, 4D SD have emerged, also known as 3D-Time Lapse seismic surveys, involving 3D seismic data acquired at different times over the same area.

From left to right: 2D seismic gather, 3D seismic cube, and 2D slices extraction from 3D seismic volume
2D, 3D and 4D SD are multidimensional signals that have a number of unique features differentiating them from conventional texture images:
- High resolution and very large size, i.e., millions of pixels in one dimension and gigabyte to terabyte scale of data.
- High Dynamic Range (HDR) with high bit-depth of 32 bits for floating point values.
- No many textural structures as conventional images.
- Low motion characteristics and highly oscillatory nature.
- High degree of anisotropy with important amounts of noise.
Benchmark datasets
The following figure shows a list of the most common benchmark seismic datasets used in the literature with respect to their acquisition, i.e., marine and land, migration, i.e., prestack and poststack, dimensions, i.e., 1D, 2D, 3D and 4D, and size. SD stacks refer to a collection of multiple seismic gathers that have been stacked or summed together to reduce noise and create a clearer image of the subsurface geology. If the common seismic operations, such as inversion, are carried out before the stacking, the migration is referred as prestacked where SD is raw. Otherwise, it is poststack where redundancies in SD folds are reduced. It depends on the compression method need, either processed or less processed data.

Samples of benchmark seismic datasets
Seismic data compression methods
Various methods have proposed in the literature for SD compression. We categorize techniques used by these methods as designed and learned transforms. The common point of both classes is the transformation for data decorrelation in the transform domain or latent space. In the designed transform based methods, SD are converted from spatial domain to a new one using fixed predefined transforms. The class of learned transform based methods extracts the main informative features of SD via machine learning algorithms and deep layers, that learn the transforms from training data in a latent space. Some compression techniques, such as Compressive Sensing or Sampling, Functional Quantization, and Tucker representation, are used in the literature to obtain more compact versions of a seismic signal. While these techniques are not transforms in the traditional sense, they are usually used in conjunction with transforms. So, they will be categorized in one of our two classes, designed or learned transform based methods, according to the nature of the transform they are combined with.
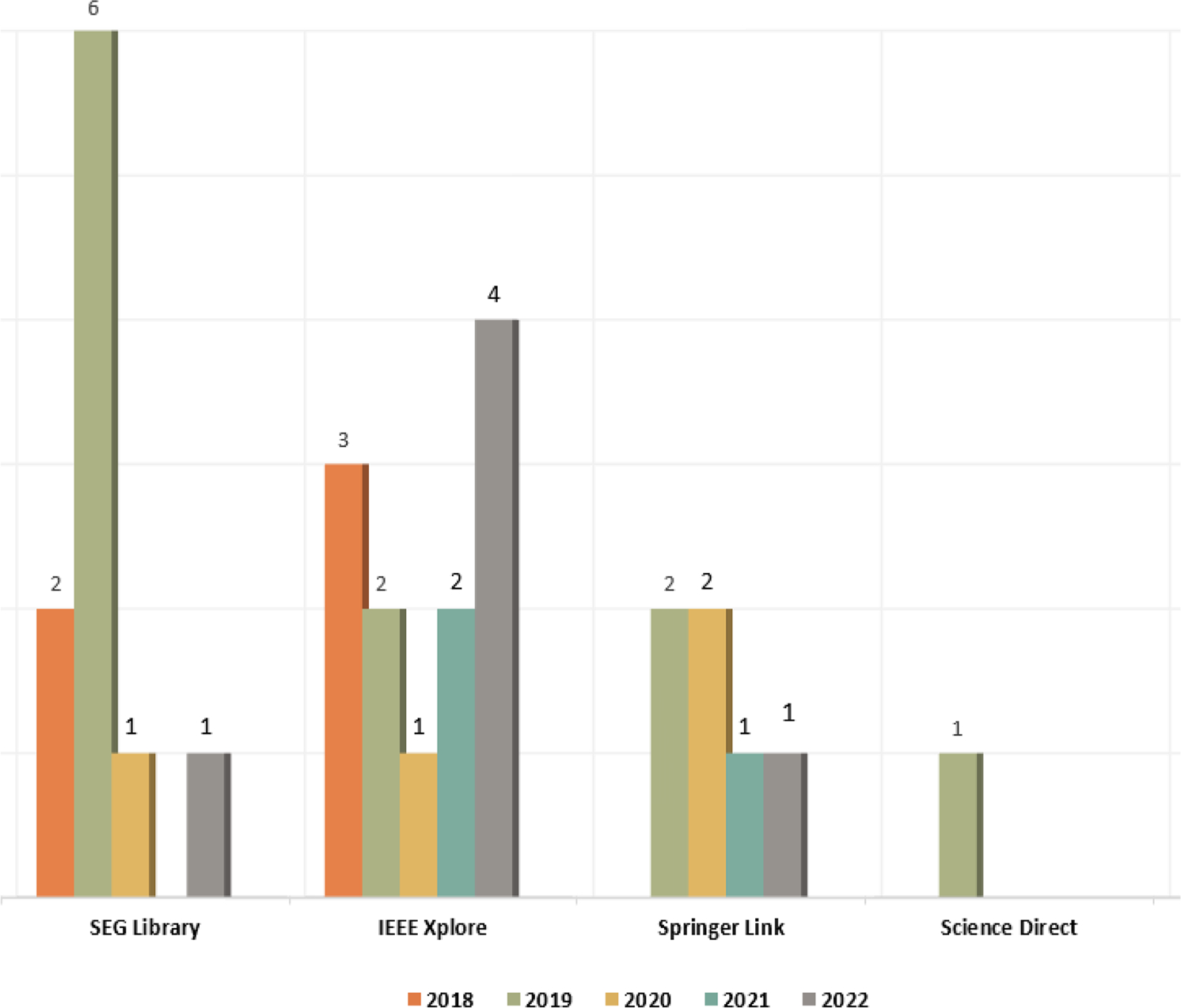
As part of this work, we review more than 70 research papers related to SD compression over the past five decades, establishing a comprehensive list of these latter.

Statistics on the SD compression methods. From left to right: Designed vs. Learned transforms, 1D vs. 2D vs. 3D SD, Lossy vs. Lossless, and Prestack vs. Poststack migration
The conclusions that can be drawn are summarized in these main points:
- Representing 31% of the total existing work, methods that rely on learned transforms to compress SD are a lot fewer than designed transform based methods. This can be explained by the youth of the learning-based compression field. Dealt by the ad hoc JPEG AI group, it is still in its early steps and has a short history requiring more extensions and research compared to conventional codecs. In fact, first efforts in learned and designed transform based SD compression methods respectively date from 2012 and 1974.
- Compression methods, both based on designed and learned transforms, for 3D seismic data are far less numerous than the efforts for 1D and 2D. They only represent 18% compared with 35% for 1D and 47% for 2D. It is judicious to focus on 3D seismic cubes as they represent richer subsurface features and more voluminous data than seismic 1D traces and 2D images. Further, redundancies between the subsurface layers are more efficiently captured for SD of higher dimensions.
- Although lossless and near-lossless compression methods preserve much better the details of the subsurface properties than lossy methods, they are sparse not exceeding the 15% of the whole SD compression methods. This can be explained by the noisy nature of seismic data which makes the lossless compression inefficient as they will preserve, inter alia, the noise.
- At the time of writing the paper, no work has been yet proposed to 4D seismic data compression, even though they present a very rich source of information for geologists, geophysicists and reservoir engineers.
- Being the best noise reduction process for SD, stacking is a crucial step that sorts out noise in order to preferentially stack the high-signal content. 63% is the percentage of methods that target the poststack SD compression as processed SD handling is less costly in terms of computation. The percentage of prestack SD compression is to be increased in the future thanks to the massive and powerful computation resources available these days. This would make the common seismic operations at the prestack level affordable and easy.
Overview of progress in recent years
There is an increasing interest in developing SD compression methods based on machine and deep learning algorithms. Except autoencoders based methods that achieve reasonably good Rate/Distortion balance, many of the learning-based methods, such as those based on machine learning algorithms, restricted Boltzmann machines, and Deep Neural Networks, achieve narrower compression rate range than designed transform based ones. Even for these relatively low compression rates, the quality of reconstructed data is not as good as for designed transforms.
The primary distinction between designed and learned transform based compression methods is their respective approaches to optimization. Rather than relying on manual fine-tuning, learned image compression models are capable of being automatically optimized based on differentiable metrics such as PSNR and SSIM, which are calculated using neural networks. Additionally, while designed coding framework generally enhances individual components, learning-based methods enable all modules to be trainable, allowing for the joint optimization of all parameters and components. Through joint optimization, the entire model can focus directly on meeting the Rate/Distortion constraint, unlike designed schemes that rely on a separate rate-control component, which may not provide an optimal approximation. Nonetheless, achieving excellent performance in learned compression is challenging due to optimization difficulties. These methods do not always reach the target bitrate, given the set of hyperparameters.
Further, existing learned transform based SD compression methods are fixed-rate which requires, from a practical point of view, the training of multiple models to accommodate various Rate/Distortion tradeoffs. The retraining for each compression rate requires a multiplied training time, and so a very high cost in terms of processing and memory resources to train and store models. In addition, learned transform based methods are capable of processing images at their full resolution, whereas designed transform based ones typically process images as partitioned blocks. Processing images at full resolution provides advantages for entropy modeling by incorporating more context and avoiding the blocking artifacts that arise from partitioning. However, full-resolution processing is accompanied by increased complexity.
Comparing compression methods for seismic data compression is not straightforward since methods in both classes have different strengths and weaknesses depending on several, sometimes contradictory, compression requirements. Both designed and learned transform based methods have been proven competitive for seismic data compression, apart from some basic approaches for the two classes that have been surpassed. The choice between the two depends on several factors, namely:
- The specific characteristics of the seismic data, e.g., nonstationarity, correlation and noise levels, seismic data variability, data from a single or different formations, subsurface geology, dimensions, measurements coverage, ...
- The specific requirements of the target application, e.g., real-time, high, moderate or low compression requirements, production lead time, ...
- The availability of computational, storage and communication capacities, e.g., onsite or offsite compression, wireless or wired seismic sensors, ...
The potential of designed and learned transform based methods for the successful compression of seismic data depends on their awareness of all the aforesaid elements. In essence, careful consideration of these factors is necessary when selecting a compression method for seismic data; and we hope that the comparative analysis we have provided in our paper will be helpful for this. The different types of seismic data compression approaches are schematized, with their essential strengths and weaknesses, in the following visual map.

Open challenges and future directions
Either based on designed or learned transforms, compression methods contribute to the reduction of seismic data size, and then accelerate their manipulation, storage, and transmission. Nevertheless, these methods represent some important bottlenecks, some of which are being currently addressed by recent efforts. Others remain open research questions to be handled in the very near future:
- Requirements for large seismic datasets: much more SD acquisitions are needed to figure out subsurface physical properties and discontinuities. Further, SD have a high degree of anisotropy, which requires large training datasets in order to capture the different subsurface properties in different directions.
- Towards in-field seismic data compression: SD acquisition has witnessed successive progress, ranging from prewired geophones to wireless ones. These latter face serious challenges because of SD size that can achieve tens of terabytes per day. This makes the transmission of data from geophones to onsite data collection centers, via Low Power Wide Area Networks such as LoRaWAN and 5G, greatly constraining. An in-field compression is then required.
- Edge computing tailored seismic data compression: Beyond its assets, in-field SD compression requires some hardware and software designs to be considered. More reflective deep architectures should be designed to make SD compression more affordable on real-world and real-time use cases at edge computing devices such as geophones.
- Rethinking compression models with federated learning attention: As moving to the edge is crucial for oil and gas companies to make better use of data, it is judicious to move towards the federated learning where several seismic edge computing devices collaborate together to learn a model under the orchestration of a server.
- Reconstruction-aware seismic data compression: It is important to acquire densely sampled seismic data in order to not badly impact subsequent seismic processing, such as reverse time migration and amplitude variation with offset analysis. Although advantageous for geophysical end-use applications, dense SD acquirement is not always possible because of in-field obstacles like economic factors and construction conditions in seismic survey environments. And if we succeed to acquire such data, it would be highly voluminous. Trying to find the right compromise between density and voluminosity of SD, many efforts have opted for compressive sensing to yield sparse data according to a desired sampling rate. Geophones are thus active devices combining compression to acquisition. Missing data persists, though. Thus, a SD reconstruction step would follow the compressive sensing-based SD compression methods to make them more successful.
- Simultaneous seismic data compression and denoising: In addition to the pure geological or geophysical information, SD commonly include noise stemmed from several sources, such as weather, drilling at the field, ship traffic, and other seismic vessels nearby. Plenty of methods have been proposed to extract relevant seismic information by reducing or eliminating noise, especially where the signal is weak and the non-repeatability has to be tackled. However, denoising is performed separately from the compression. It is nevertheless better and smarter to perform the SD denoising and compression by one single method; mainly that compression generally provides a concentration of seismic information and reduces its dynamic range which, in some way, excludes redundancy and incoherent noise in the seismic data.
- Time-lapse seismic data compression: Time-lapse, also known as 4D, seismic data are 3D seismic surveys of the same areas captured at different moments in order to assess and monitor dynamic properties of hydrocarbon reservoirs like fluid movement and saturation, temperature and pressure. Although of valuable insights, 4D SD are not fully explored because of different challenges that have resulted in no work being proposed for 4D SD compression at the time of writing the paper.






Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in