Self-supervised video processing with self-calibration on an analogue computing platform based on a selector-less memristor array
Published in Electrical & Electronic Engineering
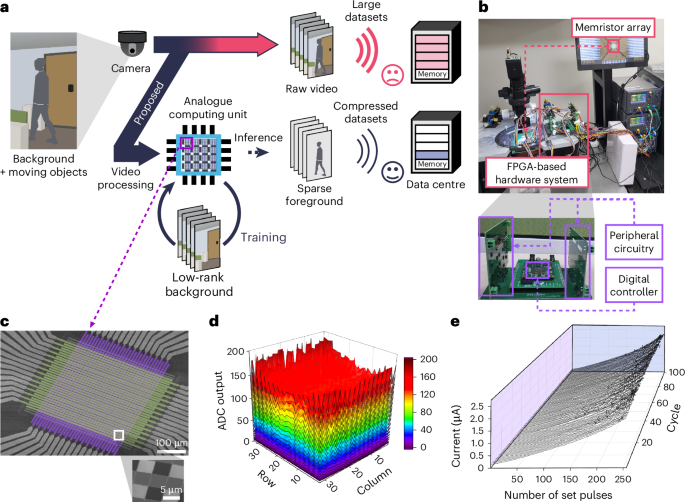
Conventional computers are characterized by a separation between memory and processing units, necessitating continuous data transfer between these resources. This architecture often leads to high energy consumption due to frequent data movement. Memristor-based analog computing hardware is an emerging approach that enables simultaneous data storage and processing, significantly reducing energy requirements while maintaining computational efficiency. Utilizing the inherent analog resistance characteristics and simple two-terminal structure of memristors, multiply-accumulate (MAC) operations can be performed directly in the analog domain. This computing paradigm not only minimizes energy overhead but also improves processing speed, making it a promising solution for implementing AI on edge devices. Research on memristor-based hardware has spanned various areas, including device development, peripheral circuits, energy-efficient architectures, and algorithm implementation. At the same time, however, it was clear that the performance of the available memristor-based devices at the moment was not sufficient to serve as a computing platform for real-time applications. Our team believed that an interdisciplinary study tightly connecting physical devices and applications would be mandatory to fully unlock the potential of memristor-based devices.

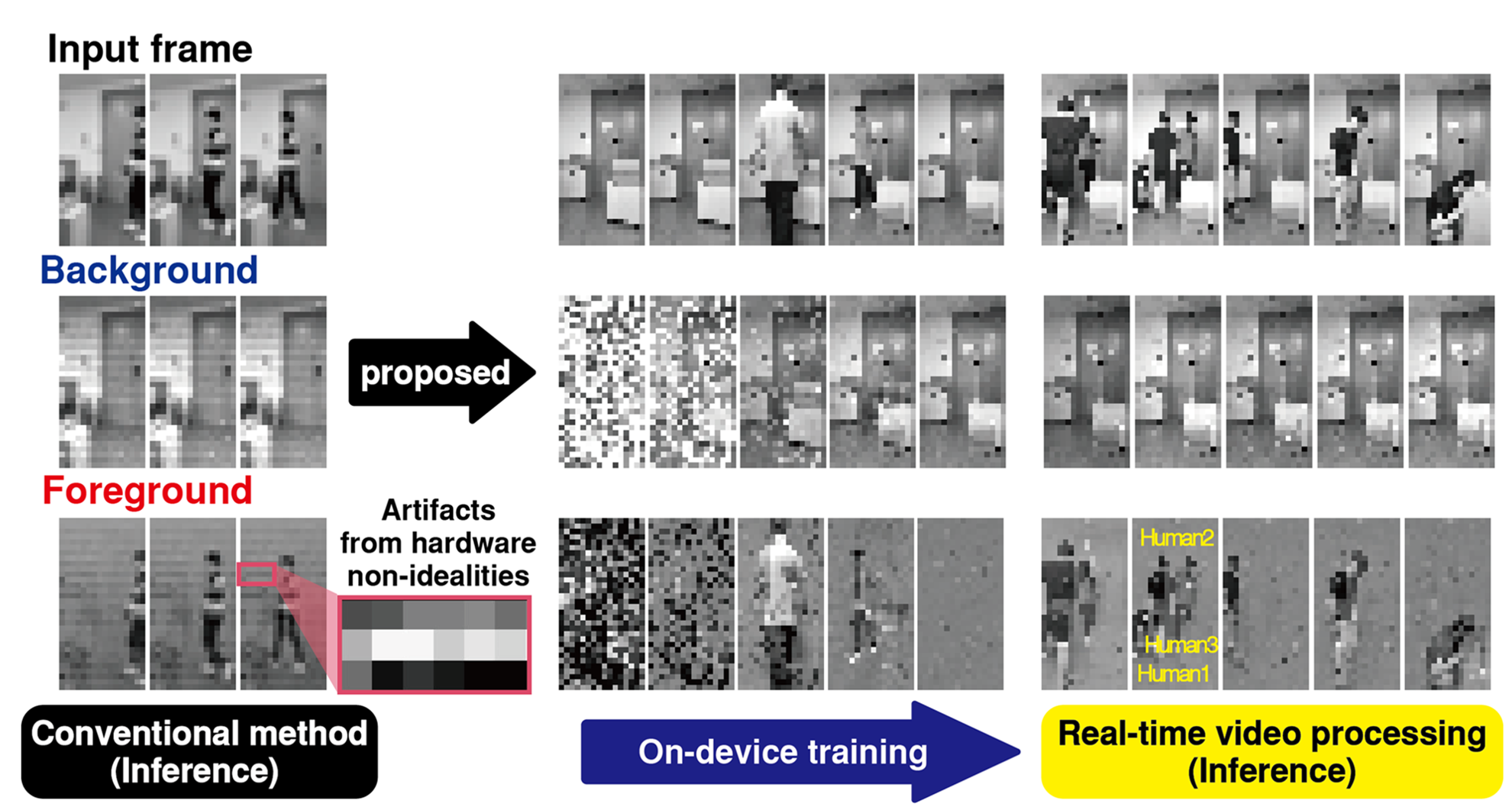
Figure 1. Video separation using analog computing hardware platform. (a) Result of video processing based on pre-trained weight. (b) Result of real-time demonstration with on-device training (left) and inference (right).
Unfortunately, our initial attempts to merge the hardware platform and algorithms revealed the complexities of interdisciplinary research. We recall the anticipation and anxiety of testing our system for video processing, only to witness repeated failures: the screen displayed nothing but white or black outputs, despite repeated tuning efforts. A thorough review was conducted to identify any overlooked issues, but both the hardware and software components were confirmed to operate correctly on their own. Through extensive discussions and careful deliberations, we came to realize that translating AI algorithms to physical hardware posed unique challenges, particularly due to discrepancies between software and hardware. For example, the weights in our memristor-based hardware are fixed and constrained within the device's resistive switching behavior, whereas its ideal software counterpart utilizes 32-bit floating-point weights initialized from a standard normal distribution.
To address this, we developed comprehensive simulation software that supports video processing and accurately emulates hardware behavior, incorporating factors such as memristor characteristics, quantization, and inherent nonidealities. This simulator allowed us to systematically identify optimal training configurations, including initialization, learning rate, momentum, within a virtual environment. Following extensive validation, we determined a robust training configuration that worked seamlessly on hardware. It was an unforgettable moment when the hardware finally produced distinguishable background and foreground outputs – albeit with artifacts – using the optimized training setup (Fig. 1a).
These artifacts spurred a deeper exploration: could the hardware itself become part of the training loop? By extending our self-supervised AI algorithm, we integrated the memristor array directly into the computational graph, enabling end-to-end optimization. This approach treated hardware-induced nonidealities and artifacts as part of the graph, naturally driving the optimization process to suppress these imperfections. The integration not only improved the system’s overall performance but also demonstrated the potential of tightly coupling hardware and AI algorithms for robust and efficient solutions (Fig. 1b). By overcoming a critical barrier in adapting AI systems to physical hardware, this innovation marks a significant step forward in advancing memristor-based computing and its applications.
Addressing the challenges encountered while bridging different fields required numerous discussions and information sharing, which allowed us to take a step closer to each other's expertise. This collaborative process served as a foundation for implementing on-device learning. Through this effort, we demonstrated the capability of memristor-based analog computing hardware, traditionally focused on inference-heavy workloads for edge applications, to also handle training-specific algorithms. Recent studies have further emphasized the operational flexibility of analog hardware, reinforcing its potential for diverse applications.
Lastly, we would like to extend our sincere gratitude to the editor and reviewers for their constructive and insightful feedback. They recommended, for example, that we focus on areas for additional hardware improvement, the usability and efficiency of hardware system utilization, and comprehensive explanations of device and system operations. We believe that these suggestions were instrumental in demonstrating our team's capabilities and refining the manuscript.
Follow the Topic
-
Nature Electronics
This journal publishes both fundamental and applied research across all areas of electronics, from the study of novel phenomena and devices, to the design, construction and wider application of electronic circuits.






Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in