Storing data in molecules - High data storage capacity by dual-sequence-definition
Published in Chemistry
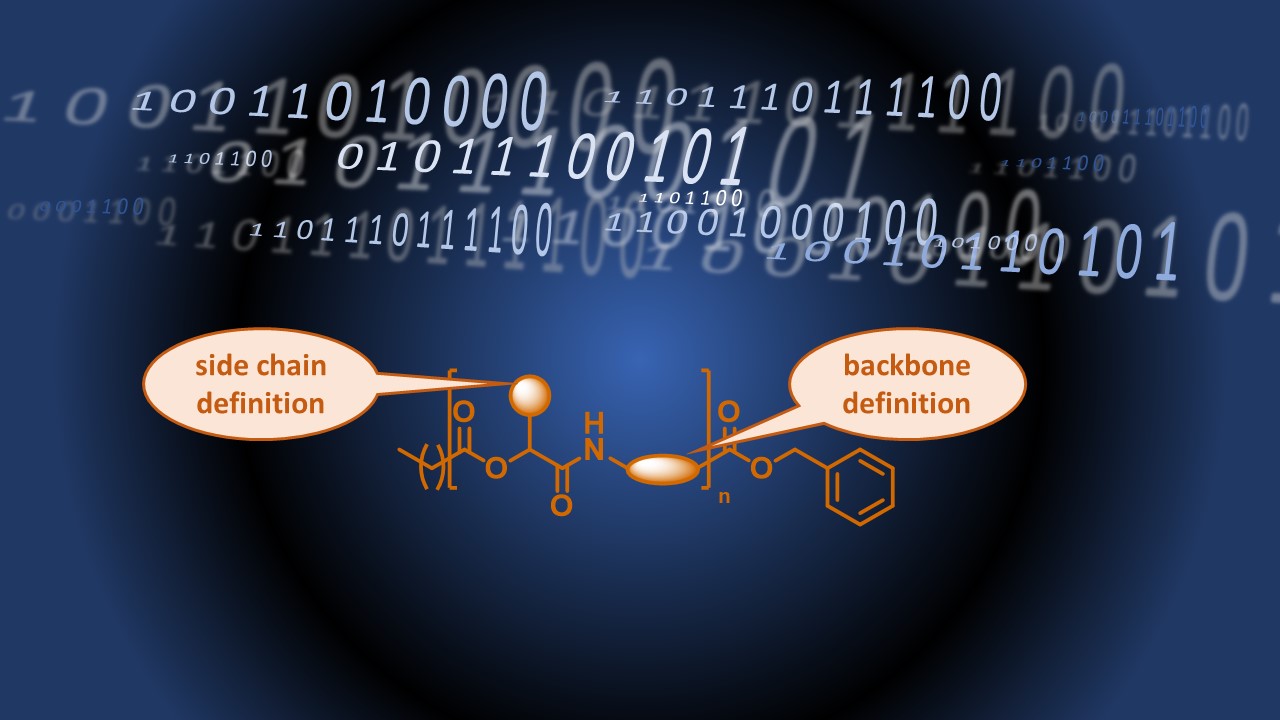
Sequence-defined macromolecules represent a relatively young section in the field of polymer chemistry. These macromolecules of uniform size and constitution are particularly interesting, as they resemble the unprecedented precision of some natural macromolecules, such as DNA or peptides. Thus, they bear great potential for many new applications, ranging from enzyme mimicking over anti-counterfeiting tags to data storage. After many innovative approaches towards sequence-defined macromolecules have been developed from research groups all over the world, the focus of research is starting to shift towards finding an application for this new type of macromolecules. Especially an application in the field of data storage seems promising. In this context, the number of permutations is an important benchmark to compare the data storage capacity of different systems. This number indicates the chemical diversity in terms of possibly achievable structures and thus the data storage capacity of a certain system. DNA represents a natural example and can be considered as a prototype for artificial data storage systems, as it carries the genetic code. In case of DNA, four nucleobases are arranged in long sequences in a certain order which defines genetic information.
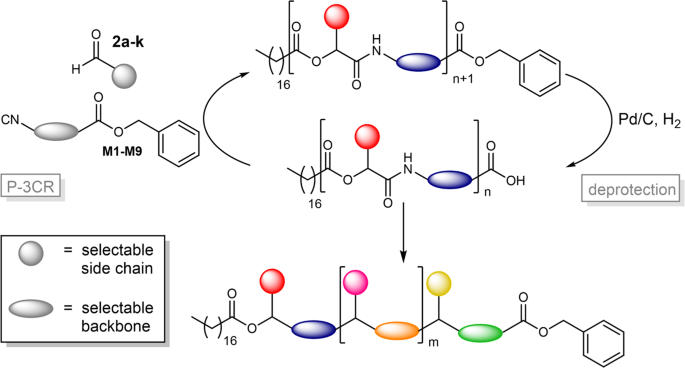
Very long sequences are synthetically demanding and so far, sequence-defined macromolecules have only been achieved with lengths in the range of oligomers. In this work, we decided to focus on increasing the degree of definition per repeat unit and thus the data storage capacity achieved per synthesis step, rather than aiming for longer sequences. In order to do so, we chose a very powerful and, in our group, well-established tool: the Passerini three-component reaction (P-3CR). By using a certain monomer containing a protected acid and an isocyanide group, sequence-defined oligomers can be formed stepwise via a two-step iterative cycle consisting of the P-3CR and a subsequent deprotection step. It is well-known that sequence-defined macromolecules with defined side chains can be prepared by applying this concept. However, in this work, we did not only define the side chain by varying the aldehyde component, but additionally established a set of nine different monomers, which allowed to define the backbone of the prepared macromolecules. Thus, we were able to vary the side chain and the backbone independently, increasing the structural variety and thus the data storage capacity drastically. Of course, the read-out of the sequences was the important second part of our work – one can only claim data storage if a read-out is demonstrated unambiguously. Having the oligomers in hand, we performed fragmentation experiments via tandem mass spectrometry to read the sequences. Interestingly, we found two characteristic fragmentation patterns, simplifying the analysis of complex sequences and providing possibilities for error-correction. Finally, we compared oligomers with different degree of definition (side chain, backbone, or both) with DNA as natural prototype and with the commonly used binary system. This comparison clearly shows the advantages of our system, as it achieves a significantly increased data storage capacity (i.e. 33 bits for a pentamer) compared to the so far known systems.
If you want to learn more about our work, please check out or paper: https://www.nature.com/article...
Follow the Topic
-
Communications Chemistry
An open access journal from Nature Portfolio publishing high-quality research, reviews and commentary in all areas of the chemical sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Chemical modification of proteins
Publishing Model: Open Access
Deadline: Sep 30, 2026
Sustainable waste management through polymer upcycling
Publishing Model: Open Access
Deadline: Aug 31, 2026
Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in