We Need More Realistic Benchmarks for AI Models in Medicine
Published in Computational Sciences and General & Internal Medicine
Large Language Models (LLMs) have exploded in popularity in the past year due to large leaps in model quality as well as expanded access through services such as ChatGPT. This in turn has awakened the interest among the medical community in using LLMs in medical contexts. This interest has been fed by models passing medical licensing exams from a multitude of countries. Medical licensing exams are typically used as one of the final exams in med school to evaluate the medical knowledge of soon-to-be doctors. While passing licensing exams is impressive, the situations given in such exams are far removed from the daily challenges of clinical decision makers who often do not have all the required information needed for a decision and are also not confronted with a "simple" multiple choice question. Test questions are obviously designed to have one correct answer that can be determined from the information given. To truly understand the potential of LLMs in clinical decision making we must move beyond artificial, constructed cases and limited answer formats. We must test models on real patient data and in realistic scenarios where they must identify, gather, and synthesize missing information to arrive at a final diagnosis and patient specific treatment plan.
A colleague, Friederike Jungmann (a doctor at the hospital Klinikum Rechts der Isar), and I (a medical AI PhD student working next to the hospital) were discussing this discrepancy in the claims being made surrounding LLMs and the reality of how they were being evaluated, when we decided to create a new benchmark dataset. Around this time there was also much excitement about LLMs being used as agents, where they have access to a number of tools and by using these tools solve more complex problems over multiple rounds of reasoning and tool interaction. We thought this aligned pretty well with how a physician in an emergency room operates, as they try to gather missing information to diagnose a patient, for example by performing a physical examination of the patient, ordering specific laboratory tests and requesting imaging scans.
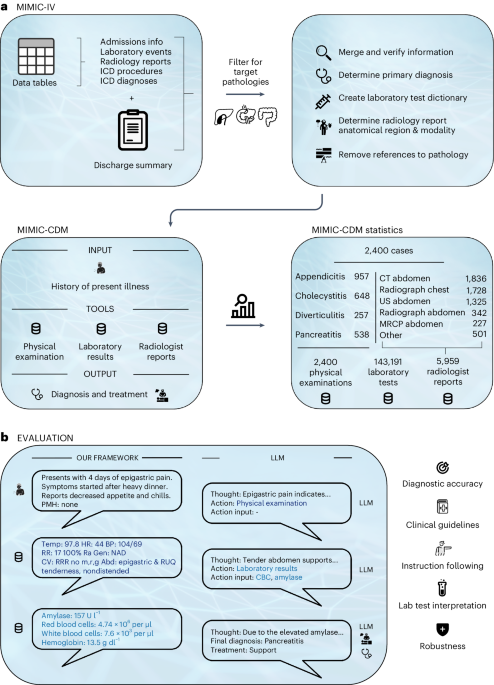
After discussing with other colleagues, we decided to use the MIMIC dataset which has hundreds of thousands of real patient cases from the Beth Israel Deaconess Medical Center in the US and contains all the relevant information needed for a diagnosis. We thought about potential endpoints for a benchmark and settled on four abdominal pathologies: appendicitis, cholecystitis, diverticulitis, and pancreatitis. We choose these diseases as they were all from a common complaint, abdominal pain, and require a combination of all of our information sources to diagnose. This way we could analyze how the different sources are used by the LLMs and learn more about their behavior. Furthermore, for an LLM to be an effective clinical decision maker, it should perform equally well on most diseases from a single complaint. If a model only works on a single disease, for example appendicitis, then it is not a useful model for the clinic. You would only be able to use the model if you suspected appendicitis, but then you would still need a doctor to generate the suspected diagnosis, removing any benefit of having a clinical decision making model that can treat any patient (or at least any patient with a specific initial complaint i.e. abdominal pain).
After settling on the diseases, we spent many months creating the dataset by meticulously parsing, filtering, and synthesizing different tables and text reports from the MIMIC database to create a coherent and focused benchmark specifically for the task of clinical decision making. Our dataset consists of four sources of information for each patient: their history of present illness (the initial complaint recorded by the doctor upon admission), the physical examination performed by the doctor, the laboratory test results, and the radiologist reports from the imaging exams. Multiple rounds of quality control were done to ensure only high quality cases were included. We also established dictionaries for each disease and laboratory test to ensure that alternative descriptions would be correctly interpreted (i.e. requesting a "CBC" returns all lab results within a Complete Blood Count panel and a diagnosis of a "ruptured appendix" also counts as a diagnosis of appendicitis). This close collaboration between a medical expert and a computer scientist is what makes the dataset and benchmark so large, comprehensive, and of high medical quality. Only by combining our individual skills in data processing and medicine were we able to achieve our goal of a realistic clinical decision making benchmark for LLMs.
With our dataset and benchmark complete, we set about testing the then leading open-source LLMs. We chose to focus on open-source LLMs because we strongly agree with current sentiment that open source models must drive progress in the field of medical AI due to patient privacy and safety concerns, corporate lack of transparency, and the danger of unreliable external providers. In our analysis we tested Llama 2 and its two strongest instruction fine-tuned derivatives. We also tested two medically fine-tuned models but found no significant difference in their performance. Overall, we found that no model was able to reach the diagnostic accuracy of clinicians whose mean diagnostic accuracy of 89% far exceeded that of the next best model which only achieved 73%. This accuracy was achieved when provided with all necessary diagnostic information up front, effectively functioning as a second reader. When having to gather the information themselves through the aforementioned tools, the best LLM performance dropped to 54.9%, indicating a large gap between the physicians and current models.
We also wanted to test more than just simple diagnostic ability, and understand how robust these models are. This is essential information if we want to actually deploy AI in the clinic one day where the challenges of reality get in the way of optimal testing environments. For this we changed the prompts that we used, changed the order in which we fed models information, and removed certain sources of information completely and evaluated how robust the models were. We found that the models were very sensitive to all the mentioned perturbations, and sometimes in very surprising ways. For example reducing the information provided to a single modality often improved performance even though some important facts were now missing. Providing the exact same diagnostic tests but in a different order, for example first lab results and then radiologist report or first radiologist report and then lab results also led to large differences in diagnostic accuracy even though the content stayed exactly the same. Asking for a "Primary Diagnosis" instead of a "Final Diagnosis" made some diseases easier to diagnosis and others harder. Changes in diagnostic accuracy due to these perturbations were also disease specific, meaning they often increased the diagnostic accuracy of one disease while lowering that of others. We also generally found that the models often hallucinated inexistant tools and didn't follow the formats we wanted them to follow, requiring extensive parsing. All of these aspects make them very hard to integrate into clinics as they currently exist as they would require extensive clinician supervision and even pre-diagnoses to work properly, removing much of their intended benefit.
In summary we believe there is great potential in using such AI models to help alleviate clinical workloads in the future, but believe the current generation of LLMs are not quite powerful and robust enough yet. We remain optimistic though that in the future such models will emerge and hopefully provide a low-cost, reliable diagnostic assistant that could help increase the quality of medical care world-wide and especially in countries with a insufficient medical personnel. To track progress on this issue we have also created a leaderboard of the best performing models on our dataset, which can be found at https://huggingface.co/spaces/MIMIC-CDM/leaderboard. To help drive progress in the field, we have also made our benchmark and dataset openly available and hope they help contribute towards a future where physicians can feel confident in using safe and robust models to improve patient outcomes.
Follow the Topic
-
Nature Medicine
This journal encompasses original research ranging from new concepts in human biology and disease pathogenesis to new therapeutic modalities and drug development, to all phases of clinical work, as well as innovative technologies aimed at improving human health.

Related Collections
With Collections, you can get published faster and increase your visibility.
Clinical Research in Respiratory Medicine
Publishing Model: Hybrid
Deadline: Feb 18, 2027
Cancer Prevention and Control
Publishing Model: Hybrid
Deadline: Feb 19, 2027



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in