How can AI modernize Veterinary Care?
Published in Healthcare & Nursing

Large-scale electronic health records (EHR) can be a powerful resource for patient care and research. In comparison to human EHR, there has been little machine learning work on veterinary EHR, which faces several unique challenges. While it is standard practice for clinicians to enter standardized diagnosis and billing codes for human EHR, veterinary clinical notes are almost entirely uncoded. The lack of standard diagnosis coding on veterinary records is a major bottleneck for public health monitoring and cross-species translational studies. Moreover, due to the lack of infrastructure and third-party payer system, veterinary notes have different styles and vocabulary, and clinical notes from different clinics can differ substantially in its writing style, making automated coding a challenging task.
We developed VetTag, a machine learning algorithm that takes as input veterinary notes and automatically predicts the relevant diagnosis codes. In previous works, algorithms are only trained on coded notes collected from a handful of training hospitals. This new work differs from previous works as we augment supervised training with a form of unsupervised learning --- large-scale language modeling to read through millions of unlabeled notes. Such unsupervised training is a promising new approach to boost the power of many natural language processing methods. By leveraging a massive amount of unlabeled clinical notes, we demonstrate that this type of unsupervised learning is crucial in improving the performance and robustness of the diagnosis coding model. We obtain substantially better performance when algorithms are applied to notes from a diverse set of clinics across the country.
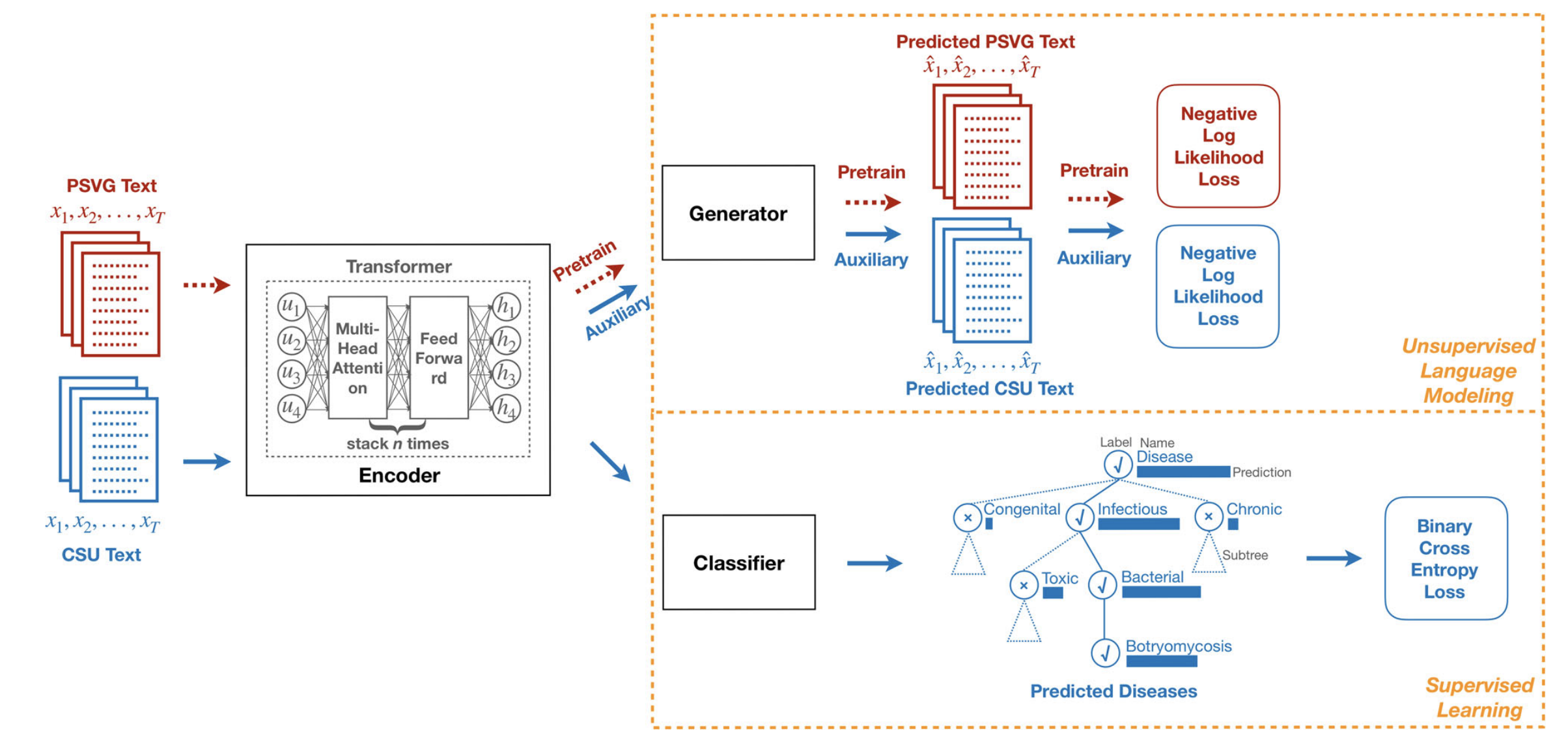
Clinical note coders are instructed to apply lower-level, more specific codes as much as they can. Many labeled codes correspond to very specific diagnoses, and simply predicting top-level diagnosis is not sufficient in practice. As specificity and depth increase, the number of potential diagnoses also increases and the number of relevant training cases decreases. Instead of adopting the standard multi-label prediction scheme, we propose the hierarchical training method to tackle data imbalances. We leverage the hierarchy amongst the diagnosis codes so that the model only predicts the child diagnosis when all of its parents are present. We demonstrate that this hierarchical training is significantly better, especially for more specific diagnosis categories which previously suffered from low recall.
In order to better understand how our model predicts diagnosis codes from clinical notes, we implement a simple saliency-based interpretation method. The saliency of each word quantifies how much that word influences the model's predictions, and it is computed as the gradient of the predicted probability with respect to the input word. The most salient words for our model agree well with the clinically meaningful terms. Moreover, we observe our saliency map identifies words such as acronyms and combinations beyond what the standard MetaMap medical vocabulary. Highlighting such salient in clinical notes can help human curators to label documents more quickly and provide rationalization over the model's decision process.


Our work addresses an important application in healthcare and our experiments add insights into the power of unsupervised learning for clinical natural language processing. As we make meaningful progress toward a more robust automated coding system for veterinary medicine, we note that there is still a significant drop in performance when applied to text from a different hospital. We can partially mitigate this effect by adjusting the decision threshold of the binary classifier, but further research needs to be conducted on learning both over-represented diagnoses and under-represented diagnoses in this setting.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027
Impact of Agentic AI on Care Delivery
Publishing Model: Open Access
Deadline: Jul 12, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in