A novel bimodal dataset for inner speech recognition
Published in Research Data
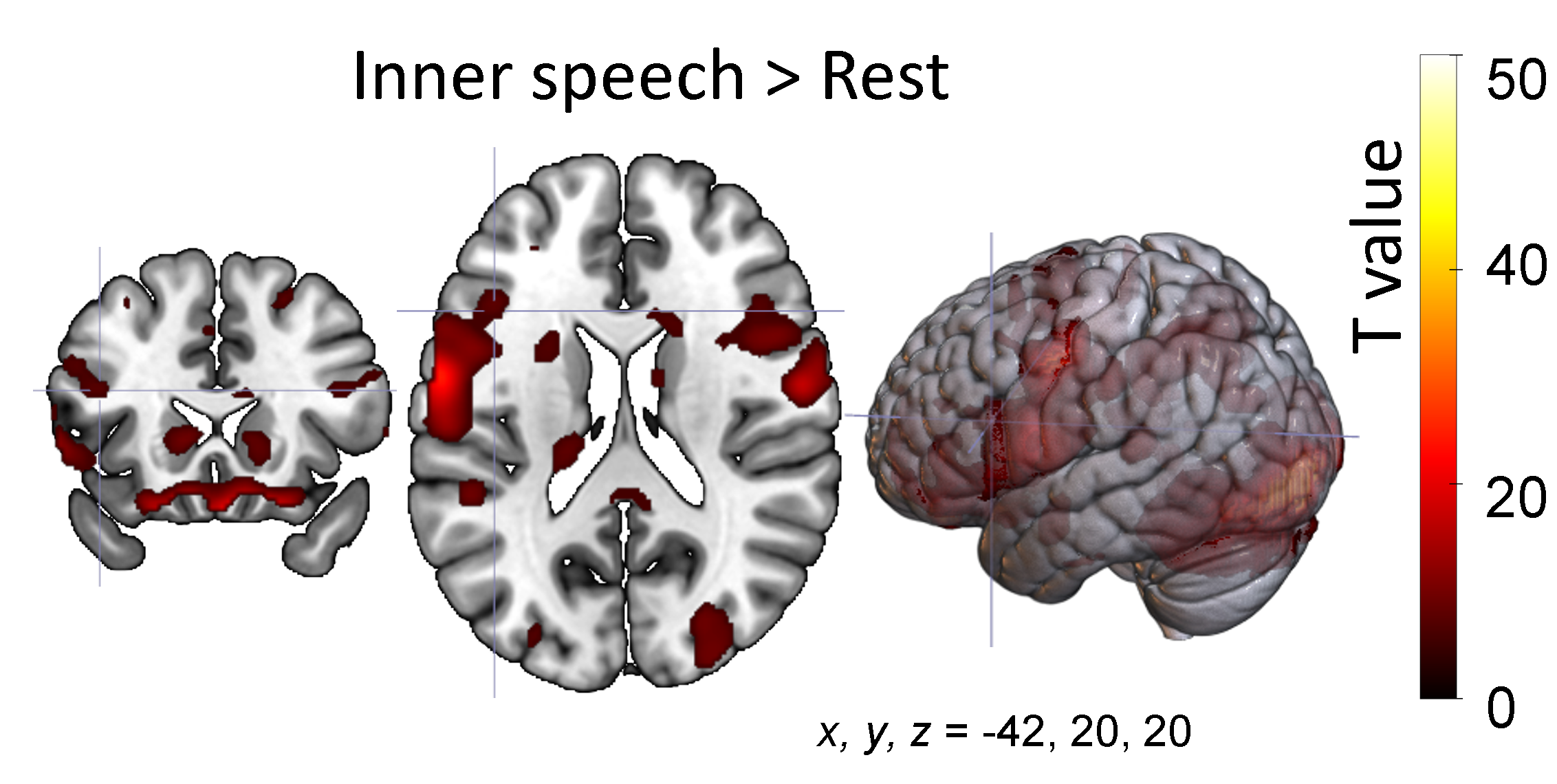

Inner speech recognition is a challenging research area where the state of the art is currently limited to recognition of close word vocabularies and can assist humans that have no ability to communicate with their friends and family, e.g., people in Locked-In-Syndrome.
Our recent article in scientific data presents the first publicly available bimodal dataset containing EEG and fMRI data acquired non simultaneously during inner-speech production. The novel idea behind is the combination of two modalities with complementary features in order to achieve a better performance in inner speech recognition. EEG is known for high temporal resolution, while fMRI has a high spatial resolution. Therefore, the combination of these two modalities is beneficial for inner speech recognition compared to using these two modalities alone.
To support the previous claim, we contacted a supplementary study, where we applied machine learning methods on our bimodal dataset and provide baseline classification results. Our study reports for the binary classification, a mean accuracy of 71.72% when combining the two modalities (EEG and fMRI), compared to 62.81% and 56.17% when using EEG, resp. fMRI alone. The same improvement in performance for word classification (8 classes) can be observed (30.29% with combination, 22.19% and 17.50% without). The classification results demonstrate that combining EEG with fMRI is a promising direction for inner speech decoding.
The research was funded by the Grants for Excellent Research Projects Proposals of SRT.ai 2022, Sweden. The bimodal dataset was acquired at the Stockholm University Brain Imaging Centre (SUBIC) .
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Genomes of endangered species
Publishing Model: Open Access
Deadline: Jul 01, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in