An Advanced Method to Predict Personality Traits by Combining Different Types of Information
Published in Computational Sciences and Behavioural Sciences & Psychology
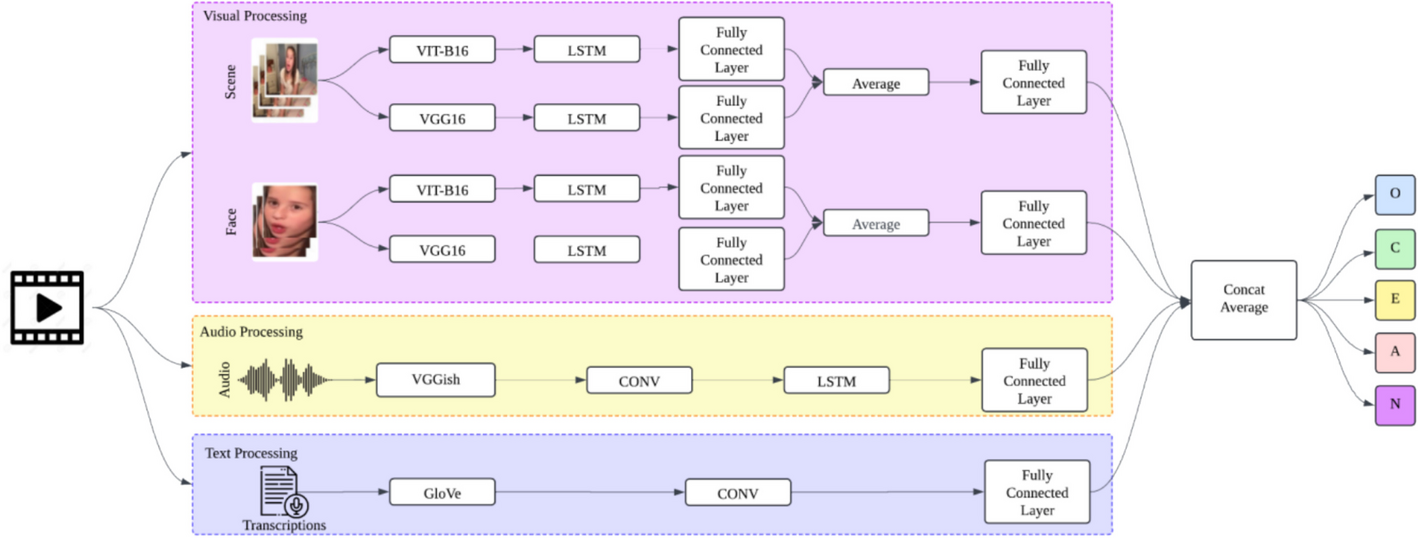

Our approach is designed to take personality prediction to the next level by using not just one but three different types of data: visual, audio, and text! Each of these "modalities" helps paint a more complete picture of a person's personality traits.
We use the latest computer vision techniques to capture visual information from videos. Two powerful models, Vision Transformer (ViT-B16) and VGG16, help us detect scenes and facial expressions. This lets us read important visual cues, like whether someone is smiling or looking serious.
We listen too! Audio helps us understand personality. By analysing how someone speaks, we gain insight into their personality traits. And of course, words matter! Using advanced natural language processing (NLP) techniques, we analyze the text, such as the transcript of what someone says in a video, to capture their linguistic patterns. So, how does it all come together? Imagine we have a video of someone. From that single video, we pull features from three places: the entire scene (what’s going on around the person), the person’s face (the main focus), and their voice. These features can also be extracted from text. They are then trained and combined.
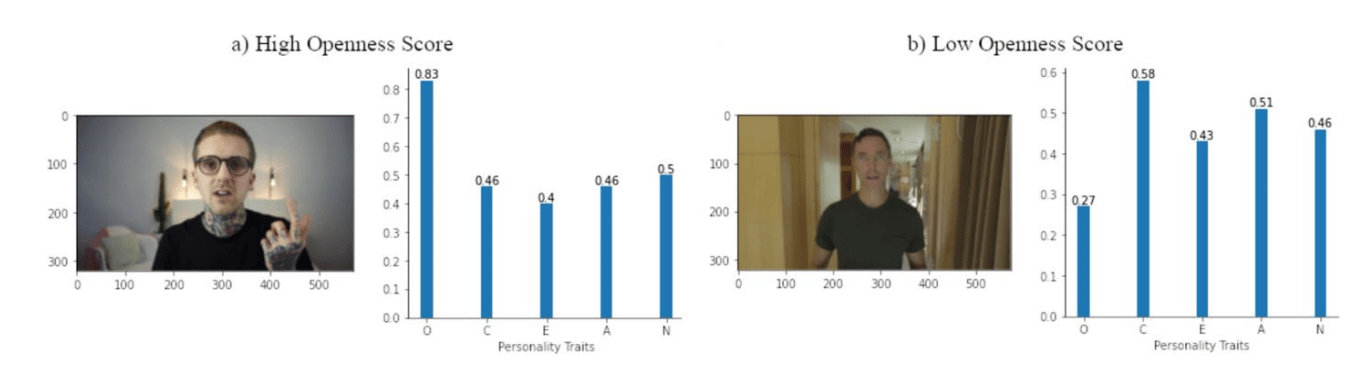
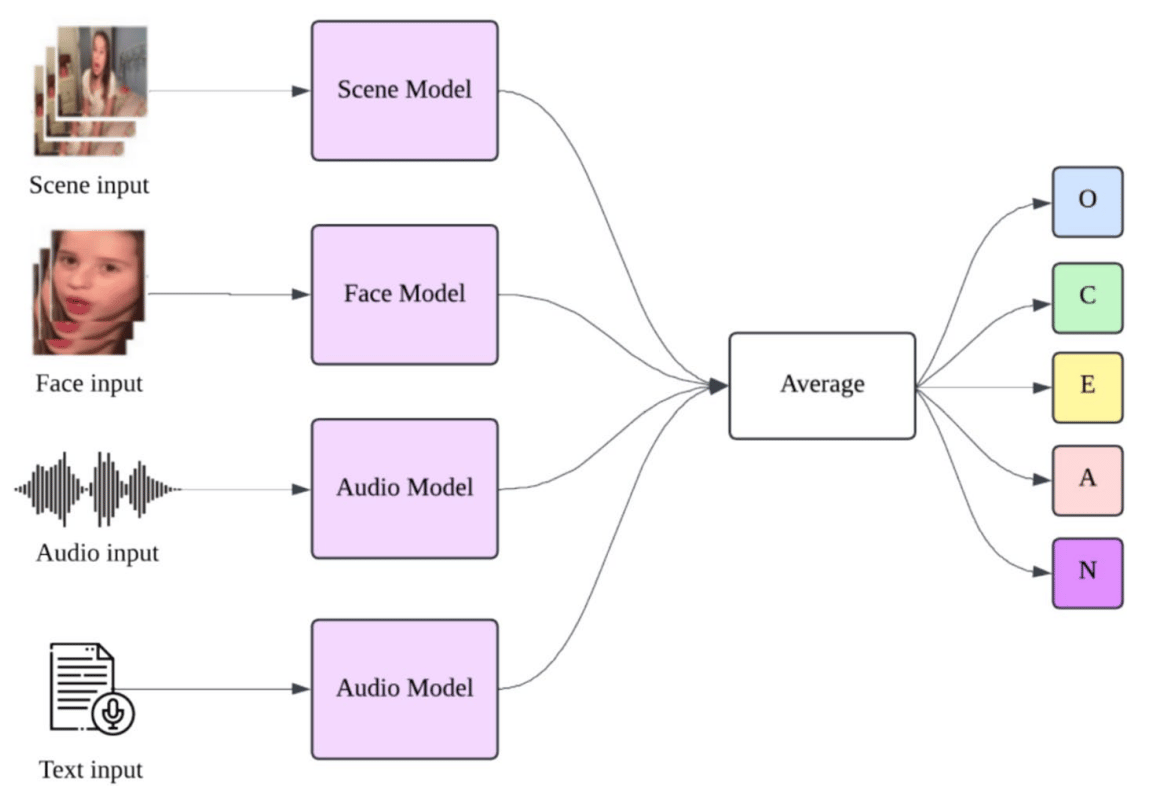
We use four models to analyse data. They help us understand personality and what makes people unique.
Follow the Topic
-
Multimedia Tools and Applications
This journal publishes original research articles on multimedia development and system support tools, and case studies of multimedia applications.





Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in