
This study aims to introduce a new way to synthetically generate chemical reactions using a deep learning technique. In layman’s terms, we are teaching an artificial brain how to think and speak in chemical reactions. We then ask the artificial brain to come up with new, unique thoughts and recite the thoughts in the form of new chemical reactions. The brain in this system is based on a Variational Autoencoder (VAE), a specialized type of deep learning algorithm that has been extensively employed for speech recognition. The task of the VAE used in this study is to synthetically generate continuous datasets. This network has been termed Autonomous Generation of Reactions and Species-VAE (AGoRaS). The approach involves sampling the latent space to generate new chemical reactions. This is where this method outperforms other methods. The developed technique was demonstrated by generating over 7,000,000 new reactions from a training dataset containing only 7,000 reactions. The real application of this method is the generation of synthetic datasets, which can ultimately be used to train new more robust artificial intelligence models. Often, training of these AI models requires larges datasets that are unbiased. This technique finds its real application in generating these synthetic datasets without inherited bias originating from the training data. The application of this technique is quite broad, with applicability to almost any AI dealing with chemistry, but this method is most useful for new chemicals, materials, and pharmaceutical discoveries.
What is a Variational Auto-encoder and why should I use it?
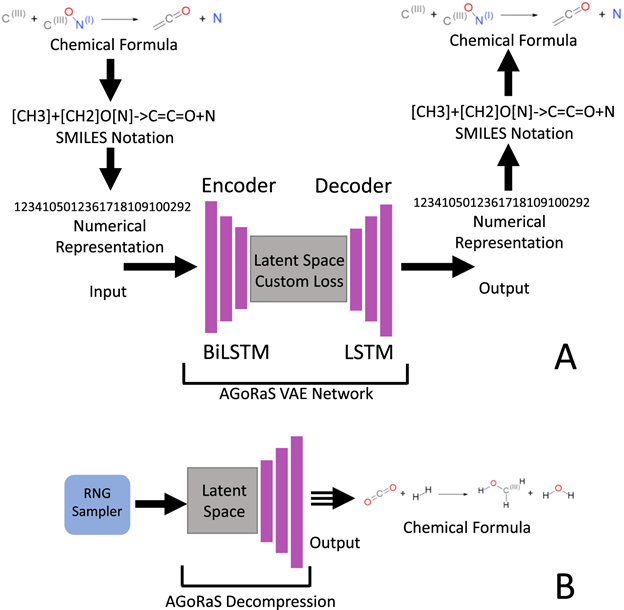
A VAE is an autoencoder style of network, where instead of the encoding having a single value for each input node, the distribution is regularized during the training processes. This allows for each input node to have a probability of values in the encoded space rather than a discrete value. This then allows the sampling of the generated latent space to generate new outputs as seen in figure 1. The only information given to AGoRaS-VAE is the encoded SMILES string of the training sets chemical reactions and the only output is an encoded SMILES string, in which hydrogen atoms are implicit.
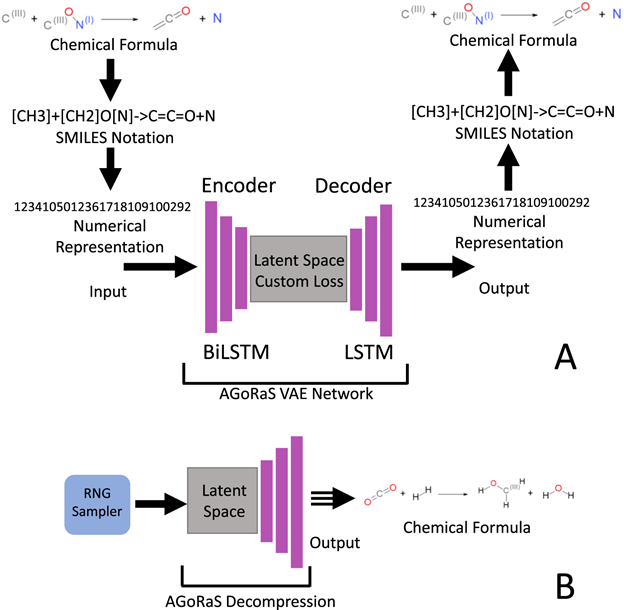
Figure 1: As illustrated in (A), the chemical database information is compressed and decompressed to form a high-dimensional latent space. B illustrates the workflow of how the trained latent space is sampled to generate new chemical equations
Why this method is important?
- This method represents a new way to think about the interface between chemistry and Artificial Intelligence. The VAE approach can be thought of as a custom compression technique for these chemical reactions.
- The latent space can be thought of as the memory of artificial intelligence. While it is not apparent by looking at the weights of the system, the artificial intelligence is empirically learning about the underlying physics and chemistry of the process.
- No human bias in the creation process. Because researchers are human, all too often their underlying biases go into the design of experiments.
- You can do this method with limited input data. This study had only 7,000 input data points but due to the nature of the problem, we could still train a VAE as long as we set up a strong pipeline to filter results as seen in figure 2.
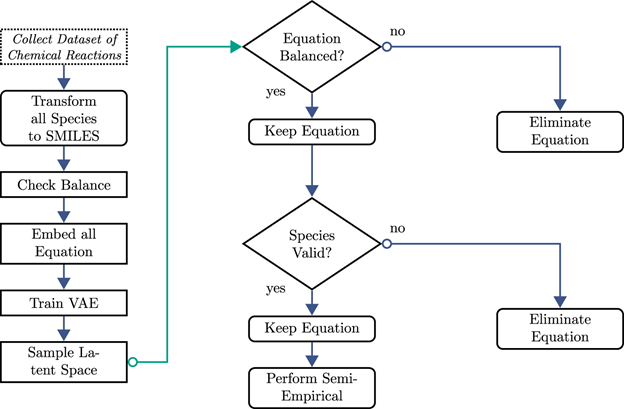
Figure 2: The generated equation is checked for both balance and existence. The semi-empirical calculation receives a SMILES descriptor and conducts an independent series of processes to generate a clean atomistic description before the calculation of thermodynamics data.
- Not just a dataset generator. This methodology can be used to generate specific types of reactions, not just general reactions. On top of that, the generated datasets can be filtered for reactions containing specific products or reactants a researcher is looking for.
- The generated datasets are thermodynamically similar to the original datasets. To visually and statistically compare trained and generated datasets of vastly different sizes, a random sample of 7000 equations was subselcted out of the generated dataset. An overlapping comparison between datasets was performed to confirm a correlation between the two datasets as seen in figure 3.
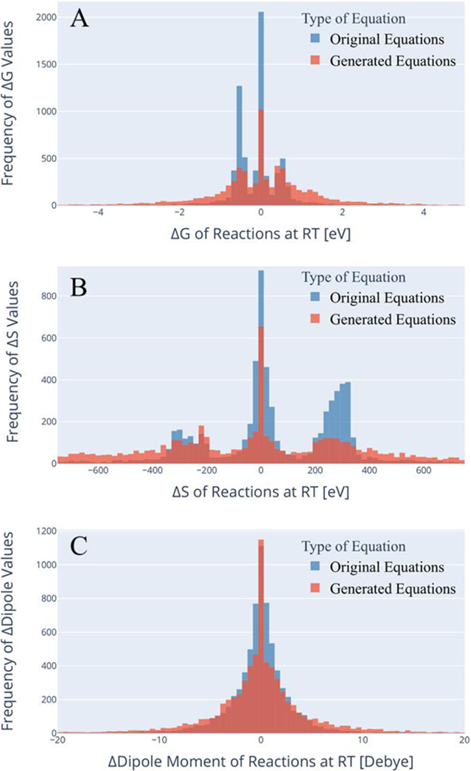
Figure 3: A is the Gibbs energy associated with Eq. (1). B is the difference in entropy between the product and reactant molecular species. C is the difference between the product and reactant dipole moment.
Thanks for reading, for more information, please read our paper at https://doi.org/10.1038/s42004-022-00647-x.
Follow the Topic
-
Communications Chemistry
An open access journal from Nature Portfolio publishing high-quality research, reviews and commentary in all areas of the chemical sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Chemical modification of proteins
Publishing Model: Open Access
Deadline: Sep 30, 2026
Sustainable waste management through polymer upcycling
Publishing Model: Open Access
Deadline: Aug 31, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in