Fatal Flaws are Ingrained in Laboratory Animal Research - But who cares?
Published in Cancer, Microbiology, and Neuroscience
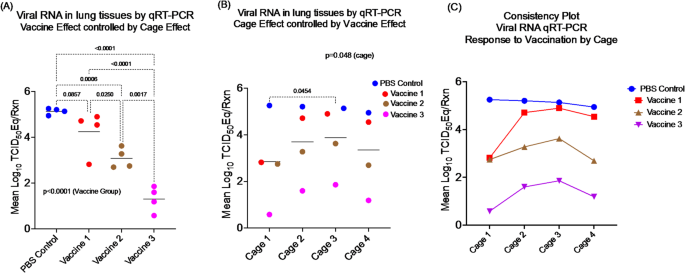
To determine the prevalence of biased laboratory animal research designs in the published literature, we conducted a structured review of animal experiments published in North America and Europe in 2022 (Scientific Reports https://rdcu.be/eCisi). These studies involved sophisticated techniques, talented scientists, and thousands of laboratory animals. And yet, when we examined how the experiments were designed, we found a sobering truth: not even one followed the principles of rigorous experimental design.
At first, this was hard to believe. But the deeper we looked, the clearer it became: the flaws were not subtle details buried in statistical jargon. They were fundamental problems in how the experiments were set up in the first place.
Three Problems That Undermine Reliability
- Randomization and Blinding
In any valid experiment, chance must decide which subject goes into which group. Randomization helps ensure groups are balanced and comparable. And blinding protects against the human tendency — conscious or unconscious — to see what we expect to see. Yet in no study we reviewed were animals fully randomized, with all researchers and analysts completely unaware of the groups they were working with. That leaves results open to bias before the data are even analyzed.
2. The Cage Effect
Animals living together in the same cage influence each other and share the same micro-environment. No two cages are ever exactly alike. If one cage of animals is assigned to each treatment, then the effects of treatment and cage become inseparable. It’s like comparing two schools by testing just one classroom in each — you can’t tell whether differences come from the schools or the classrooms. This “completely confounded design” makes treatment effects impossible to assess.
A better solution is the Randomized Complete Block Design (RCBD), where animals from different treatment groups are mixed within cages. In this setup, each cage acts as a fair test, allowing valid comparisons between treatments while using fewer animals overall. If this is not possible, then a valid but less efficient and more expensive RCBD with multiple cages of animals assigned to each treatment can be used.
3. The Wrong Unit of Analysis
Finally, we found that many studies analyzed data as though each animal were independent, even when treatments were applied to entire cages. This practice, called pseudoreplication, is like baking one batch of cookies but pretending each cookie had a separate recipe. It artificially inflates the sample size and makes results look more convincing than they really are.
Why This Matters
These flaws undermine the credibility of the entire field of laboratory animal research. And the consequences ripple outward:
- Ethical costs: Millions of animals are used each year in research, with the expectation that their use will generate knowledge to advance health. If the designs are invalid, animals suffer without producing trustworthy science.
- Scientific and economic costs: Time, money, and talent are poured into experiments that cannot deliver reliable results.
- Societal costs: Treatments that look promising in flawed animal studies often fail in human trials — delaying progress and sometimes exposing volunteers to unnecessary risk.
It is no wonder that laboratory animal science faces a reproducibility crisis. Many of its roots can be traced to how experiments are designed.
The Way Forward
The solutions are not new. A century ago, statistician R. A. Fisher laid out the principles of sound experimental design: randomization, replication, and blocking. Applied correctly, these principles solve the problems we found. The Randomized Complete Block Design, in particular, explicitly accounts for cage effects, ensures random allocation, permits valid statistical analysis, and requires the fewest number of animals.
But technical fixes alone are not enough. Change must happen at every level:
- Researchers must design experiments using rigorous block designs, proper randomization, and blinding.
- Funding agencies and ethics boards must demand clear documentation of study designs and train reviewers to spot invalid ones.
- Journals must enforce standards that prevent fatally flawed experiments from being published.
- Universities must create graduate programs to train a new generation of experts in experimental design and analysis who can work alongside research teams, funding bodies, ethics committees, and editorial boards.
A Call to Action
Science depends on public trust. That trust is eroded when people learn that most animal experiments are invalid by design. By addressing these flaws, we can make animal research more ethical, efficient, and impactful. We can ensure that when animals are used, their contribution genuinely advances both human and animal health.
The tools to fix this are already in our hands. What’s needed now is the collective will to use them.
What do You Think?
Billions of dollars and millions of lives, human and animal, depend on the credibility of preclinical research. The tools to fix this problem already exist — what’s missing is the collective will to use them.
Our review shows that virtually all published comparative, laboratory animal studies suffer from biased designs. This conclusion is hard to dispute. But if anyone believes the current situation can be defended, we want to hear that defence — especially from funding agencies, research organizations, ethics boards, and journal editors, who are in the best position to mandate change.
And if no credible defence exists, then the harder questions remain: what must be done, and who will take responsibility?
We believe this calls for an open, frank discussion. What do you think? How can we, as a community, address these flaws and ensure that animal experiments truly deliver reliable knowledge?
Follow the Topic
-
Scientific Reports
An open access journal publishing original research from across all areas of the natural sciences, psychology, medicine and engineering.

Related Collections
With Collections, you can get published faster and increase your visibility.
Phytochemicals and health
Publishing Model: Open Access
Deadline: Jul 28, 2026
Infectious disease diagnostics
Publishing Model: Open Access
Deadline: Sep 23, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in
Interesting discussion but not very helpful for cancer models in mice.
One general aspect for cancer research needs to be considered: Cancer is a heterogeneous disease and we have learned not to translate results from one tumor model in mice to the general cancer patient population.
In cancer research now it is rather standard to test compounds in a panel of models – similar to clinical trails phase II. Single mouse study design is frequently used for this and randomization not longer an important topic. Giving this trial design, it is not longer necessary to compare groups with statistical tests. It is rather important to evaluate treatment effects on tumors (response) critical by using adopted RECIST criteria.
Blinding would definitely helpful, but frequently not possible because treatments are different.
Please do not have mice with different treatments in one cage. Compounds are excreted by mice with urine and feces and can be taken up by other mice. I have seen studies failing because the other compound has been detected in the plasma from one mouse in the same cage.
The unit of analysis is definitely relevant, but in a total different meaning. The statistician has rather to calculate how many different tumor models need to be used to allow comparison of response rates with SoC in clinical use.
Reply to Comment
Thank you for taking the time to share these important perspectives from the cancer research field. We are pleased to have the opportunity to address you challenges and agree with several of the points you raise, particularly that:
At the same time, we respectfully disagree with the suggestion that randomization, blinding, controlling for confounding, and statistical testing are unnecessary in this context. Panels of models are only as reliable as the individual experiments that comprise them. If each study within the panel is biased in design or execution, the conclusions across the panel will also be biased.
We therefore believe that rigorous experimental design principles apply equally to cancer models as to other preclinical studies. Panels of tumor models can improve representativeness, but studies that do not address the above within each model will yield unreliable results and conclusions. As emphasized in our paper, such studies are not ethical because they waste animal lives, resources, public funds (in many cases) and lead to the miseducation of young scientists.
We hope this is helpful and look forward to further discussions.
I think this paper makes a number of essential points about pre-clinical trial design, backed up by two analytical studies of recent publications. The necessity of using randomization, blinding, and the correct unit of analysis are well explained and supported, including for mouse cancer models. I believe that most MSc and PhD programs require students to take a course in statistics. Perhaps a course specifically on study design should also be required. In the paper, I think more emphasis might have been put on the need to start with a clearly stated Null Hypothesis, and situations when one might not be needed. Secondly, some discussion of when normal distribution of data cannot be assumed and when and where non-parametric statistics might be useful.
Overall a useful and timely contribution.
Thank you very much for your thoughtful and constructive comments.
We agree that graduate students in the biomedical sciences need a reasonable knowledge of statistics. A basic grounding in statistics is essential for designing unbiased studies that produce data suitable for analysis. This does not mean every investigator must become a statistician. Rather, it means they should have enough understanding to know when expert support is needed, and to be able to critically evaluate the validity of studies on which their own work depends. We also agree that dedicated training in study design would prove to be an invaluable, if not essential addition to their graduate education. This would greatly strengthen the long-term success of future researchers.
Your point about the importance of a clearly stated null hypothesis is well taken. In reviewing the literature, however, we found no examples where laboratory animal studies specified a null hypothesis. One reason is that these studies are seldom structured as true experiments, testing a single factor against a single outcome. Instead, they often include multiple factors and outcomes—many chosen only after data collection. In this sense, most laboratory animal studies resemble observational studies, which, if properly designed, are useful for generating ideas but not for formal hypothesis testing.
We also appreciate your suggestion about recognizing when data may not follow a normal distribution and when non-parametric methods might be more appropriate. We did not explore this in our paper because, in practice, we rarely found studies where the design allowed for a valid statistical analysis of any kind. Our main goal was to highlight design flaws that make proper analysis impossible from the outset. Once data from more rigorously designed studies are available, we believe a next step will be to examine how statistical methods—including parametric and non-parametric approaches—are applied or misapplied in laboratory animal research.
Very valuable work and worth highlighting. A couple thoughts:
I have seen several presentations on this very topic at the American Association for Laboratory Animal Science national meeting. I attend this meeting because I have an interest in animal welfare. However, I wonder how many investigators make up the audience at this meeting. It is primarily aimed at facility care staff/managers and veterinarians/vet techs. Is this topic presented at other meetings? For instance, since this study data consisted of vaccine research, will this be presented at vaccine/immunology conferences? Do you plan to review work in other fields and potentially present at other conferences? In general I don't think this message is getting to the right audience. Hopefully this publication is a step in the right direction.
Secondly, as a manuscript reviewer, the journal editors really need to take the ARRIVE guidelines into more consideration. I have reviewed for journals that at minimum encourage using the ARRIVE essential 10. Some have a statement asking the authors if they followed these guidelines. They check "yes", and yet I often point out several points related to the study design/statistics reporting that are in the essential 10, but not in the manuscripts. In my opinion, authors should be filling out a form, reporting which lines in their manuscripts fulfill the ARRIVE guidelines. I actually beta tested the 2.0 guidelines with a manuscript of mine and filled out a very inclusive table of where each point was located. It took a little time, but it made the manuscript more transparent.
Thank you very much for your comments. These are very important points.
Getting this message out and overcoming deeply ingrained approaches to study design that stretch back more than 100 years will be very challenging. Our initial action has been to publish our paper and through this, give the scientific community a clear description of our position on this issue. In the coming days we will make a joint press release, aimed at getting the attention of the scientific community and the general public. At the same time, we are in the process of opening discussions with major funding agencies as we believe they can act as a major control point to assure that poorly designed research does not receive their support. To keep our thinking practical, we are meeting with various laboratory groups and ethics boards to get their reaction to our ideas and recommendations. We are also meeting with university officials to discuss the establishment of training programs aimed at producing experts in study design and analysis. Where we go after that is still being considered and we will certainly pay attention to your recommendations and any others that we receive.
We are fully supportive of the ARRIVE guidelines, though our emphasis differs in important ways. ARRIVE focuses on the publication process, while our concern is with the planning stage of research. For this reason, we are more prescriptive and less flexible about critical issues related to bias, such as blinding, randomization, addressing cage effects, and using the correct unit of analysis. With respect to blinding and randomization, this distinction makes sense: no study design can anticipate every possible source of bias, so some level of imperfection will always need to be tolerated in the reporting of research.
I see. By the time you're at the ARRIVE guide stage, it's too late.
What are your thoughts of the PREPARE guide and having funding agencies require something similar? https://journals.sagepub.com/doi/10.1177/0023677217724823
Section 4 seems like it could be helpful, although the wording is a bit vague at this point. I think it's a good starting point at least.
Thank you for drawing attention to PREPARE: Guidelines for planning animal research and testing, an important document and associated website that offers much valuable guidance for researchers during the design and conduct of animal studies. Of particular relevance to our paper is the detailed supplemental information linked at norecopa.no, which expands on Section 4—Experimental design and statistical analysis.
Our paper, however, focuses specifically on the four fatal flaws that compromise the validity of most, if not all, laboratory animal experiments. If these flaws—related to failures in full randomization, full blinding, control of cage effect, and the use of the correct unit of analysis—are not rigorously addressed at the design and analysis stages, the resulting data are inherently unreliable and cannot support valid statistical inference.
Given the opportunity, we will strongly recommend that funding agencies verify that these core design elements are in place before a study proceeds to peer review. Without this foundation, even the best-intentioned initiatives such as PREPARE and ARRIVE cannot ensure that results will be credible, repeatable, reproducible and translatable to human and veterinary medicine.
Thank you for raising these critical issues around reproducibility and rigour in animal research. Addressing these challenges requires practical tools and cultural change, and there are resources available to help researchers, institutions and funders make meaningful improvements.
One key initiative is the NC3Rs Experimental Design Assistant (EDA), which supports researchers in planning robust and reproducible studies. By guiding users through key design considerations—such as randomisation, blinding, and sample size calculation—the EDA helps reduce bias and improve the reliability of findings. The EDA is endorsed by many funders worldwide such as the NIH in the US or UKRI in the UK.
Complementing this, the ARRIVE guidelines now include the ARRIVE Study Plan, which encourages researchers to document their experimental design in advance and links to guidance to support good experimental practices from the outset. The ARRIVE study plan fosters collaboration between researchers and animal units by clearly communicating the planned procedures and rigour strategies to be used.
Finally, the latest edition of the IACUC Handbook introduces a new chapter dedicated to reproducibility. This addition underscores the responsibility of oversight committees to consider study design rigour as part of ethical review, ensuring that animal use delivers scientifically valid outcomes.
Together, these resources provide a practical framework for improving the quality and reliability of animal research. Another important question is ‘How do we act?’ – these tools offer a clear starting point.
Thank you very much for taking the time to comment on our paper. We greatly value the perspective of the NC3Rs, given its longstanding leadership in promoting rigor, transparency, and refinement in animal research.
There is no question that the NC3Rs has made an extraordinary effort over the past 15+ years to provide researchers with tools to improve study design and reporting. The EDA, the ARRIVE guidelines, and more recently the ARRIVE Study Plan represent thoughtful, well-constructed resources. Many elements of these tools are excellent and, in the hands of investigators experienced in study design, statistical analysis, and the biology of their model, will support robust experimental planning.
However, the evidence we present in our paper indicates that despite the availability of these and other resources, including the PREPARE guidelines, the overall quality of laboratory animal research has not measurably improved and lags well behind that of human studies. This disconnect raises an important question: why are these well-designed tools not producing the expected impact at the level of published studies?
Because our work focuses on study design, we want to comment specifically on the Experimental Design Assistant. In our view, the EDA will prove most effective when used by a team that includes expertise in experimental design, biostatistics (inferential and exploratory analyses), and the relevant biology. It can also help individual laboratory researchers better appreciate the strengths and weaknesses of their planned research and to understand how rapidly even ostensibly simple designs become complex. In this sense, the EDA may be best understood as an expert tool, one that is used directly by methodologists, and indirectly by bench scientists who seek their guidance.
An equally important consideration is the set of conditions under which the EDA can contribute to a genuinely unbiased laboratory animal study design. In our view, the tool’s true value will be realized only when studies begin with a clearly defined, a priori null hypothesis and, where appropriate, pre-specified secondary outcomes. For experiments intended to support inferential conclusions, several additional foundational requirements must also be in place: complete, formal randomisation of all procedures that may influence the primary outcome; full blinding of all study personnel, from animal handling through data management and analysis; explicit control of cage effects; control of other known confounding variables; and the use of the correct unit of analysis. If these conditions are not met, a study may have exploratory value in identifying potential hypotheses, but it cannot yield valid explanatory conclusions. Without these elements, no checklist or design assistant, however well-conceived, can ensure the internal validity of a laboratory animal experiment.
Finally, for any tool or guideline to have impact, it must be used and used correctly. To explore the extent to which the EDA is being implemented in practice, we conducted a focused Google Scholar search (2024–2025) using mice as the model species, given their prominence in laboratory research. Of approximately 100,000 estimated comparative mouse studies published during this period, only 24 referred to the EDA. Among these, six did not report how the EDA was used; sixteen used it only for sample size calculation; one used it for both sample size calculation and randomisation of a single variable; one provided a flow chart in the supplementary material; and none met the basic requirements of an unbiased study design. These findings are consistent with the results in our paper, which demonstrate that unbiased designs, if used at all, remain exceedingly rare in the published literature.
In summary, while the contributions of the NC3Rs are significant and deserve wide recognition, our analysis suggests that meaningful improvement will not occur until the research community consistently adopts the requirements we have listed, while incorporating many of the other practices that both the NC3Rs and others have long recommended. Tools such as the EDA and the ARRIVE Study Plan provide a foundation, but cultural change, enforcement by funders and institutions, and a commitment by investigators to implement these principles are essential if we hope to achieve the scientific validity that ethically justifies the use of animal experiments.
We look forward to further discussion of these issues.