Making metabolic networks suitable for machine learning
Published in Bioengineering & Biotechnology

Have you ever found yourself frustrated by the poor accuracy of metabolic flux predictions when using unconstrained genome-scale metabolic models? Perhaps you've gathered extensive data and sought a solution through machine learning models for predicting metabolic fluxes. In this blog post, we'll delve into our journey of conceiving an innovative hybrid model that addresses these challenges and share the steps we took to bring this new model to life.
Genome-scale metabolic models (GEMs) serve as powerful mechanistic tools for exploring the metabolic characteristics of a wide array of organisms. Among GEMs, E. coli models stand out as the most accurate and comprehensive ones available to date 1. However, a significant hurdle for experimentalists lies in the requirement for flux measurements as inputs for GEMs. While they can control media compositions, these compositions cannot be directly utilized as inputs for GEMs to yield precise quantitative predictions.
Consider a scenario in metabolic engineering, where the objective is to optimize the production of a specific metabolite by identifying the ideal media composition. Simulations can be carried out by assessing the impact of various media compositions on the metabolite production rate using a GEM. However, in this case, experimentalists are faced with the laborious task of manually setting upper bounds on uptake fluxes for each media composition, a process that is not only time-consuming but also subjective.
The primary impetus behind the development of hybrid genome-scale models was to overcome this limitation.
On the other side of the modeling realm, seemingly opposed to mechanistic models, machine learning models have proven to be very useful in guiding experimentation 2. They also have proven to handle high-complexity problems, such as protein folding 3. We assessed these capabilities should be helpful, given the complex relationship (based on many regulatory mechanisms) between the controlled experimental setup of an experimentalist, and the metabolic fluxes found in an organism.
Observing the pros and cons of GEMs (mechanistic) and ML models, we investigated the field of hybrid modeling. Flux Balance Analysis (FBA) is the usual computation framework to infer predictions with GEMs. Consequently, the first step of the project was to build FBA-surrogating methods that can be integrated into neural network models. We successfully developed three kinds of FBA-surrogating methods. We found inspiring approaches, based on recurrent signaling networks 4, Hopfield’s networks 5, and Physics Informed Neural Networks 6. Using these approaches, and not without much effort, we decided to attempt an integration of GEMs with neural networks.
Then, we integrated these FBA-surrogating methods inside a neural network architecture, yielding our final hybrid model architecture. Naturally, we assessed their performance on many datasets, including FBA simulations and experimental data from bacterial species. Our results exhibited drastically improved regression performance on the growth rate, between FBA on GEMs and our hybrid models. We also observed that our hybrid models needed an amount of training data much lower than traditional machine learning methods. However, we still lacked a guarantee that hybrid model predictions were actually meaningful and reliable.
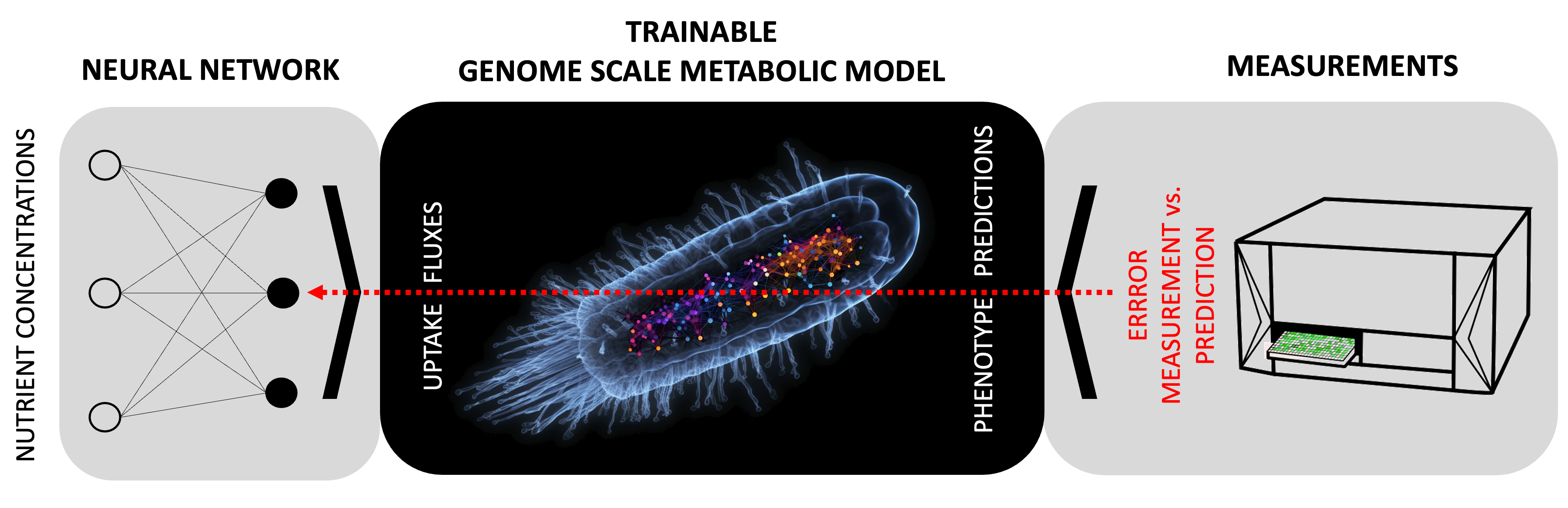
The final step of the project was to build a ‘reservoir computing’ approach. A hybrid model accurately mimicking FBA was obtained from training on simulation data. After freezing its parameters, we called this model a ‘reservoir’. Then, we learn from experimental data the best inputs for this reservoir to make accurate predictions. This approach enabled us to extract upper-bounds values of nutrients for all experimental conditions and use them as input of FBA. The FBA running with such inputs showed similar performance to the hybrid models alone, thus demonstrating that our hybrid models could indeed make meaningful predictions.
In summary, our study serves as a pioneering step towards advancing genome-scale metabolic network computation frameworks. As we embark on this journey of hybrid modeling for GEMs, we anticipate the community's collective efforts in developing more robust and fine-tuned hybrid GEM models. Ultimately, we envision a transformative shift in the computational framework paradigm for metabolic network modeling.
References:
- Reed, J. L. & Palsson, B. Ø. Thirteen years of building constraint-based in silico models of Escherichia coli. J. Bacteriol. 185, 2692–2699 (2003).
- Borkowski, O. et al. Large-scale active-learning-guided exploration for in vitro protein production optimization. Nat. Commun. 11, 1872 (2020).
- Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature 596, 583–589 (2021).
- Nilsson, A., Peters, J. M., Meimetis, N., Bryson, B. & Lauffenburger, D. A. Artificial neural networks enable genome-scale simulations of intracellular signaling. Nat. Commun. 13, 3069 (2022).
- Hopfield, J. J. & Tank, D. W. ‘Neural’ computation of decisions in optimization problems. Biol. Cybern. 52, 141–152 (1985).
- Raissi, M., Perdikaris, P. & Karniadakis, G. E. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 378, 686–707 (2019).
I am heading a research group interested in synthetic biology and systems metabolic engineering in whole-cell and cell-free systems. We develop in silico and experimental methods to search and design chemical and biological networks constrained by experimental data. The applications of our work include synthetic metabolic pathway design, building and testing for bioproduction, biosensing, and biocomputing. Other activities include structure-activity, sequence-function relationships, and the design of experiments using active and reinforcement machine learning methods.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in