From Labyrinths to Leapfrogs: Rethinking Pathfinding in Urban Networks Through Clustering
Published in Computational Sciences
Every city is a maze. From the webbed alleyways of Paris to the rigid grid of Manhattan, urban transport networks resemble the complex interconnectivity of neural synapses or metabolic pathways. As our societies become denser, smarter, and more dynamic, the challenge of efficient navigation across these tangled webs is no longer just the concern of urban planners—it is a computational problem at global scale.
In our recent study, published in EPJ Data Science (2025), we propose a new perspective on this classic problem. We introduce a hierarchical pathfinding algorithm based on graph clustering, which significantly accelerates shortest-path computations in large-scale transport networks while maintaining acceptable accuracy. Tested across over 750 real-world city graphs, our method demonstrates up to 50× speed-ups with minimal error, all while cutting energy consumption—adding a sustainability dimension to algorithmic design.
The Classic Dilemma: Dijkstra’s Legacy and Its Limits
Since Edsger Dijkstra introduced his algorithm in 1959, finding the shortest path between two nodes in a weighted graph has been a staple problem in graph theory and computer science. With a time complexity of O(M log N), where M and N are the number of edges and vertices respectively, Dijkstra’s method performs well for small to moderately sized graphs.
But urban-scale graphs are a different beast. A city like Dubai can easily feature 60,000+ nodes and hundreds of thousands of connections. When pathfinding must occur repeatedly and in real time—as in GPS navigation, logistics, or emergency response—the computational load quickly becomes untenable.
Thinking in Clusters: The Human-Like Shortcut
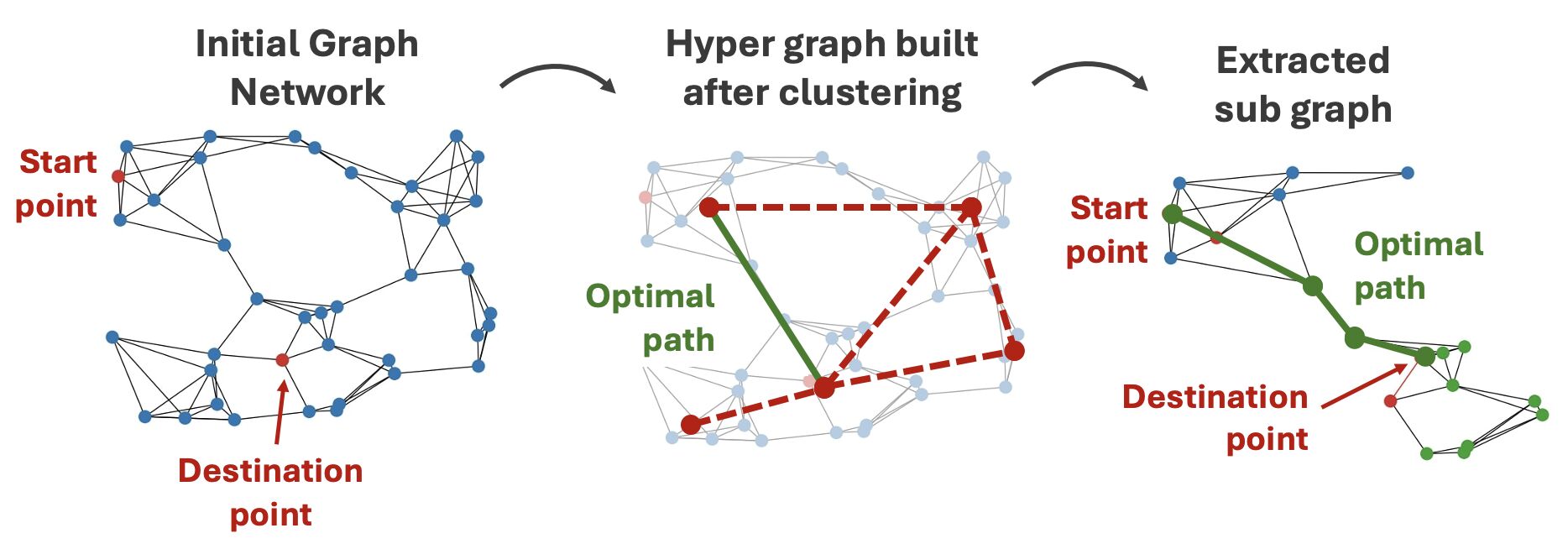
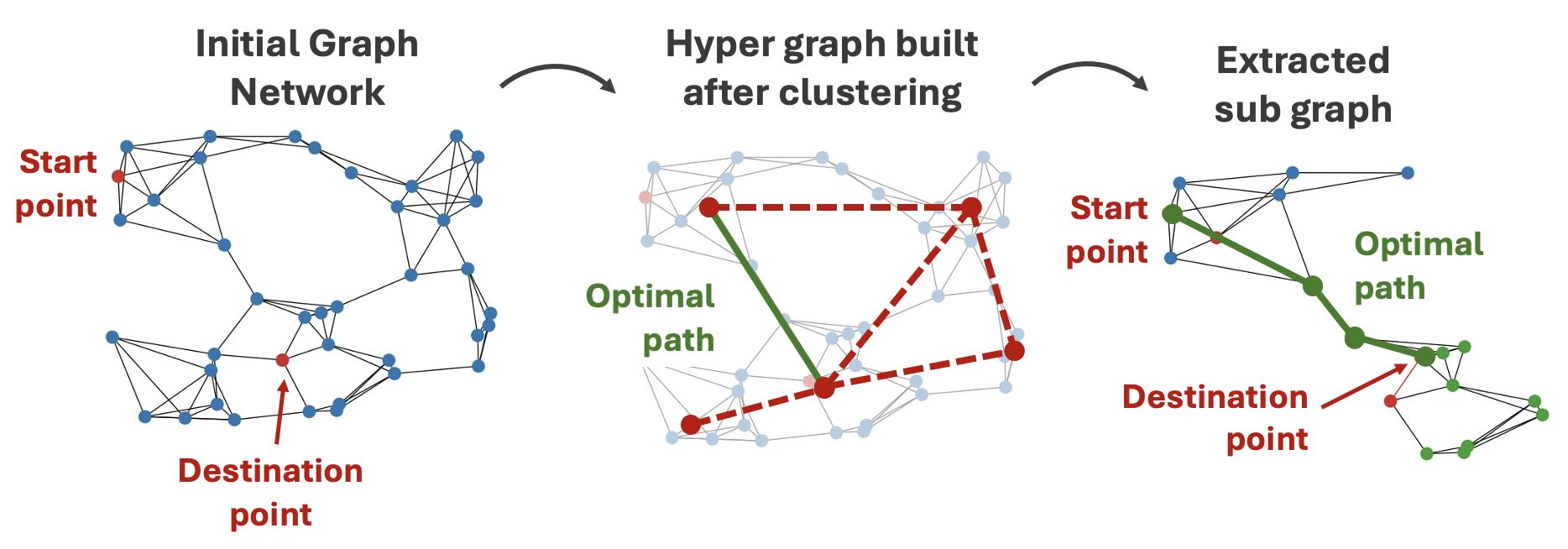
Our key insight mimics human intuition: we rarely compute global-optimal routes by evaluating every possible option. Instead, we think in zones. First, we decide on the right district to traverse—then we navigate locally. This forms the core of our Hierarchical Pathfinding Algorithm (HPFA).
HPFA begins by analyzing the graph for clusters or communities using the Louvain method, a fast and efficient algorithm for detecting modular structure. Within each cluster, we identify a centroid node—a kind of local hub that minimizes the average path length to all other nodes in the cluster.
We then construct a centroid graph: a coarse-grained version of the original network where nodes represent cluster centroids, and edges encode inter-cluster connections. By computing a path through this centroid graph and refining it locally within each cluster, we dramatically reduce the number of operations required compared to traditional global search.
The Numbers: Faster, Greener, and Nearly as Accurate
Tested on real-world transport graphs of cities like Paris, Prague, and Dubai, HPFA consistently demonstrated an acceleration factor of 10–50× compared to standard Dijkstra’s algorithm. For instance, in Dubai’s 59,000-node graph, HPFA computed paths nearly 40 times faster than the classical method—with an average deviation from the optimal path of just 14%.
The algorithm also scales well with graph size. Our theoretical model, validated across hundreds of city graphs, shows that maximum acceleration follows a power law relative to graph size. The larger the graph, the more beneficial the hierarchical clustering becomes.
Beyond speed, HPFA offers another compelling advantage: energy efficiency. Using the eco2AI library, we quantified the reduction in energy consumption and corresponding CO₂ emissions. Results show up to an order of magnitude decrease in emissions, making HPFA not just faster, but also greener—an increasingly critical consideration in AI-driven systems.
Limits of Clustering: When the Maze Fights Back
Not all graphs yield equally to clustering. Our results reveal a direct relationship between graph topology and algorithmic error. Random graphs, such as Erdős–Rényi networks, tend to lack the modular structure necessary for effective clustering, leading to higher errors. Similarly, when inter-cluster connectivity is dense, the centroid-based shortcuts may miss significant portions of the optimal path.
We explored the impact of these structural factors through a range of synthetic graph experiments. Notably, we observed that increasing graph density without preserving the relative layout of vertices can lead to rapid degradation in accuracy. This points to a critical insight: preserving topological coherence is key to maintaining both speed and fidelity in hierarchical methods.
A Versatile Framework: Plug and Play Pathfinding
While our study focused on classic Dijkstra’s algorithm, HPFA is not algorithm-specific. It can be combined with bidirectional search, A* heuristics, or even contraction hierarchies, resulting in compound benefits. We tested various combinations and found that hierarchical A*, for instance, offered up to 55× acceleration with only a 14% error margin.
We also evaluated different clustering techniques, such as k-means and greedy modularity. While some methods reduced error further, they typically required more computation time during the preprocessing phase—making Louvain a robust compromise between quality and speed.
The Future: Smarter Cities, Sustainable AI
Hierarchical approaches like HPFA align closely with the demands of modern smart cities, where edge computing, real-time response, and sustainable AI are no longer optional. In an age where computational efficiency directly translates into energy savings and environmental impact, algorithmic innovation must be measured not just in speed, but in watts and grams of CO₂.
Moreover, our framework opens the door to adaptive algorithms that adjust clustering granularity based on real-time network conditions—such as congestion or road closures. This would allow for dynamic pathfinding systems that combine local reactivity with global foresight.
Final Thought: Graphs as Narratives
At its heart, our work reflects a shift from brute-force search to intelligent abstraction. Cities, like genomes or social networks, are not just collections of points and lines—they are stories, with structure, hierarchy, and meaning. By teaching our algorithms to see that structure, we give them the ability not just to compute faster, but to understand better.
As AI continues to pervade our infrastructure, such understanding—rooted in structure, efficiency, and sustainability—may be the most important shortcut of all.
PhD in Computational Physics, Head of R&D at Sber AI, Scientific consultant at AIRI. Alma mater: MIPT 2019, ESPCI 2014, NSU 2011.
Follow the Topic
-
EPJ Data Science
This journal offers a publication platform to showcase the latest contributions to the study of techno-socio-economic systems, wherein the focus of the journal is on analyzing and synthesizing massive data sets to achieve new insights into societal phenomena and behavior.

Related Collections
With Collections, you can get published faster and increase your visibility.
Predicting fertility outcomes in PreFer data challenge and beyond: advances and limits
Fertility outcomes are among the key life outcomes shaping individual lives and societies. Different disciplines have extensively studied them, yet important gaps in our knowledge remain, illustrated by the difficulties in anticipating future fertility and its unexpected changes. This special collection explores prediction as a new approach to studying fertility behaviour. A prediction-focused approach offers several distinct opportunities: establishing benchmarks of predictive performance and trying to beat them can drive theoretical and methodological innovation; comparing predictive performance across outcomes and contexts can give insights into underlying mechanisms of fertility behaviour; tracking predictability over time can show how fertility behaviour evolves; improved predictions might enhance demographic forecasting.
This special collection aims to document current fertility predictability by leveraging advances in statistical learning and novel data sources, such as large-scale administrative data. Using fertility outcomes as an example, it also aims to provide broader insights into why life outcomes remain difficult to predict, demonstrate how prediction-focused approaches can advance life course research, and showcase novel computational social science methods.
This collection builds in part on the PreFer data challenge (Predicting Fertility in the Netherlands), in which teams predicted three-year fertility outcomes using Dutch survey and register data. However, we welcome contributions examining fertility prediction across diverse contexts, populations, and data sources.
Topics of interest include, but are not limited to:
- Predictability of different fertility outcomes across contexts
- Sources of unpredictability
- Foundation models for fertility prediction
- Use of administrative, digital trace, or linked multi-source data
- Predictability of fertility outcomes across demographic and socioeconomic groups
- Temporal trends in fertility predictability
- Model interpretation for understanding fertility behaviour
- Using predictive modelling to test theoretical mechanisms
- Applications to demographic forecasting
- Ethical considerations in fertility prediction
If you have questions about fit, please contact guest editors Gert Stulp (g.stulp@rug.nl) and Elizaveta Sivak (e.sivak@rug.nl).
Submission Information:
Authors should select the collection “Predicting fertility outcomes in PreFer data challenge and beyond: advances and limits” under the “Details” tab during the submission stage. All submissions will undergo the standard peer-review process of EPJ Data Science.
Publishing Model: Open Access
Deadline: Sep 30, 2026