Sounds of COVID-19: exploring realistic performance of audio-based digital testing
Published in Healthcare & Nursing


Motivation: The COVID-19 pandemic has shown the importance of fast, affordable, sustainable and effective testing methods to help monitor and contain the spread. Respiratory sounds have shown great potential for this purpose. With advances in machine learning, there is potential in leveraging sounds to bring about new possibilities for fully automated COVID-19 screening [1-3]. If such a technology were furthermore embedded in commodity devices, it would offer an inexpensive solution with the potential to be rolled out on a mass scale.
Yet, there is skepticism on how well machine learning can perform when used for real-world COVID-19 screening from sounds, mainly due to the data bias and the uncontrolled experimental settings [4-6]. Our recent contributions lie in exploring the realistic performance of sounds for COVID-19 detection in a holistic manner.
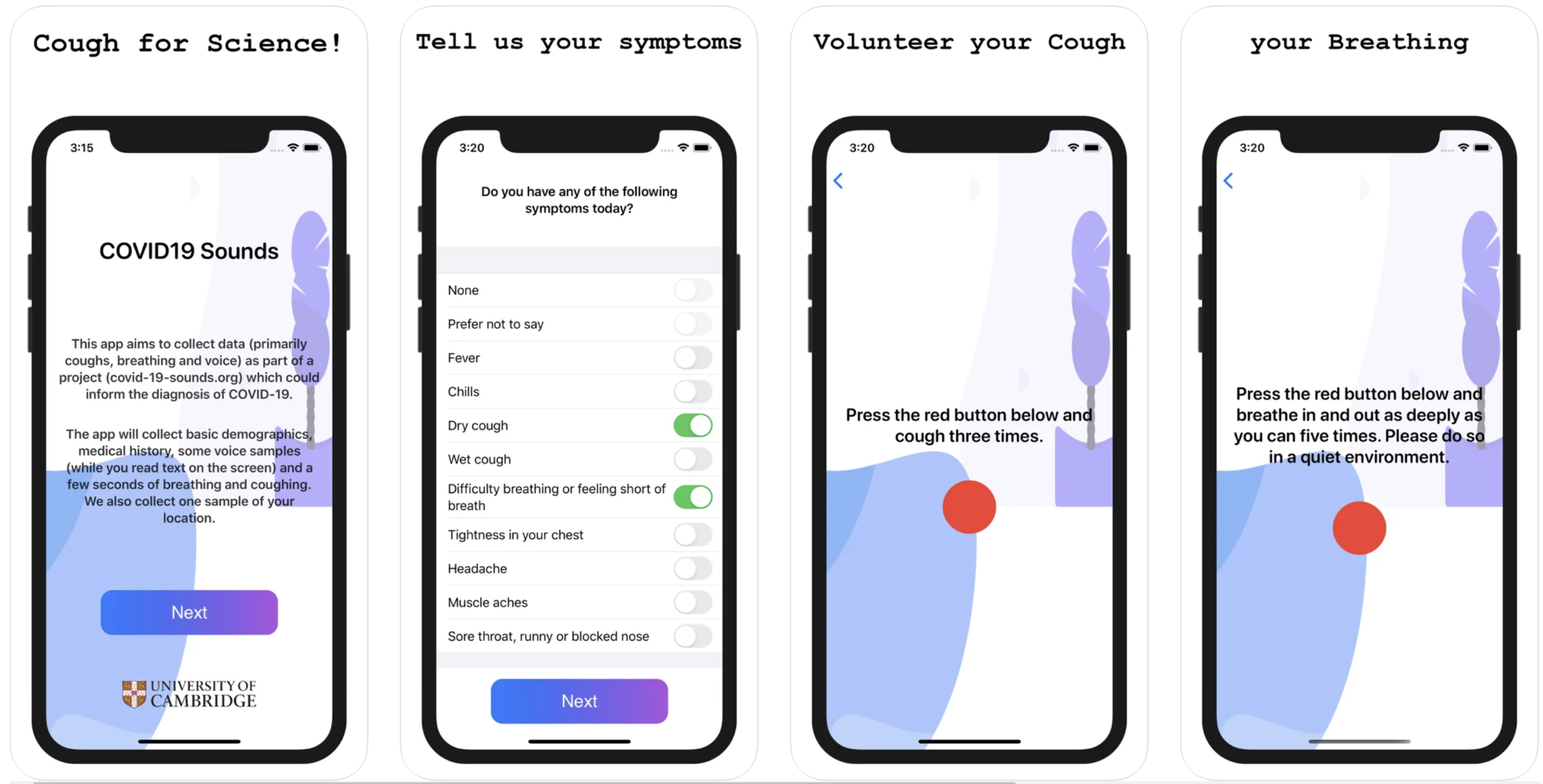
Fig. 1 Collecting voice data and labels by our smartphone app1.
Study design: We collected and prepared sound recordings from 2,478 English-speaking volunteers, who reported positive or negative COVID-19 test results through the data collection app, as illustrated in Fig. 1. With the realistic participant-independent and demographic-balanced training and validation setting, we evaluated the performance of our proposed deep neural network using cough, breathing and voice sounds as input, as illustrated in Fig. 2. Further, by extending the data with various biases introduced, we investigated the impact of random-split, data split with gender bias, data split with age bias, and data split with language bias on model performance.
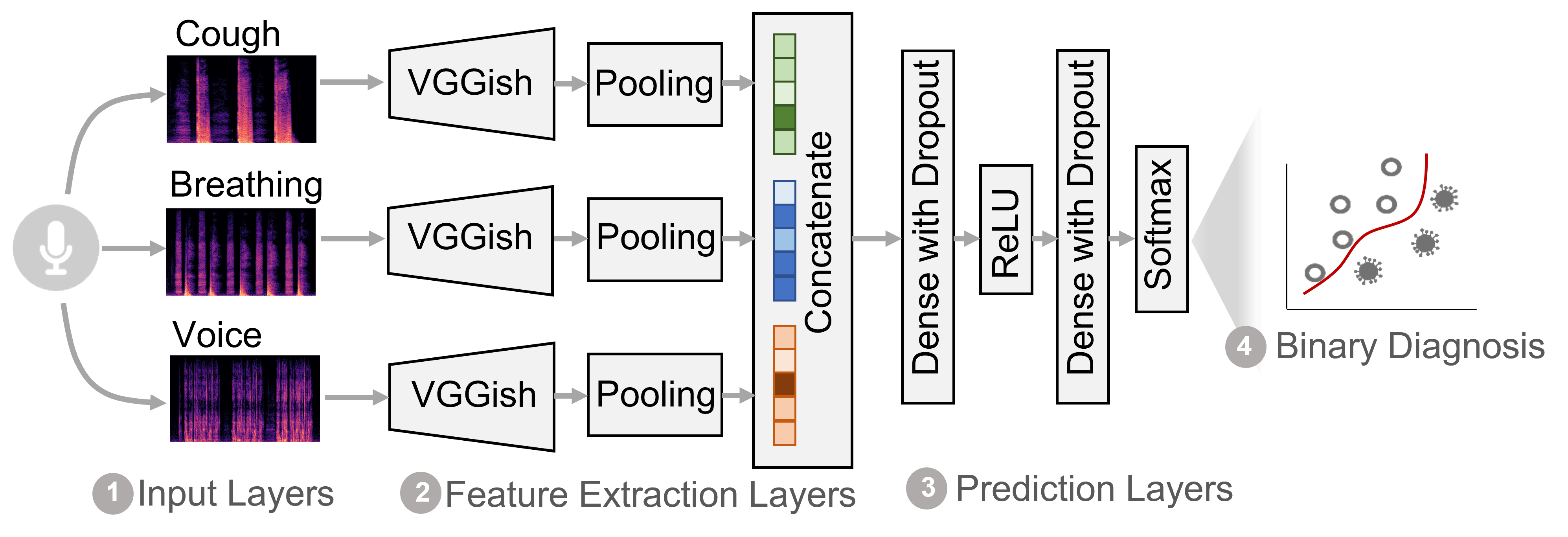
Fig. 2 Overview architecture of the deep learning model.
Main findings: On the demographic-representative testing set, our deep learning model with three sound types yielded a ROC-AUC of 0.71 (95% confidence interval (CI) 0.65-0.77), with Sensitivity of 0.65 (0.58-0.72) and Specificity of 0.69 (0.62-0.76). The combination of three sound types outperformed any single modality: a ROC-AUC of 0.66 (0.60-0.71) on cough, 0.62 (0.56-0.68) on breathing, and 0.61 (0.55-0.67) on voice was achieved. These results demonstrate a promising deployment of our sound-based COVID-19 detection model. Moreover, the performance remains consistent in various demographic and medical history subgroups, showing that our model could be applied at scale with reliable accuracy.
By purposefully introducing biases, we show how some results from previous works might have been over-optimistic. From Fig. 3, random-splits yielded higher accuracy than user-splits, with the performance gains coming from the overlapping participants from training. However, this is less realistic, as in real-world scenarios the model should ideally be well adapted to the unseen new population. Demographic bias either in age or gender appears to also lead to biased results. For instance, Sensitivity of 0.23 (0.14-0.33) but Specificity of 0.93 (0.90-0.97) were obtained on the biased (Female) group, because positive females were under-represented in the training set and this model tended to treat female participants as negative. Similar results can be observed in age-biased groups. When it comes to language bias, when positive Italian-speaking participants were over-represented for training, sensitivity was as low as 0.25 (0.15-0.36) in the English subgroup and specificity was close to 0 in the Italian subgroup, and this bias particularly impacted voice modality.
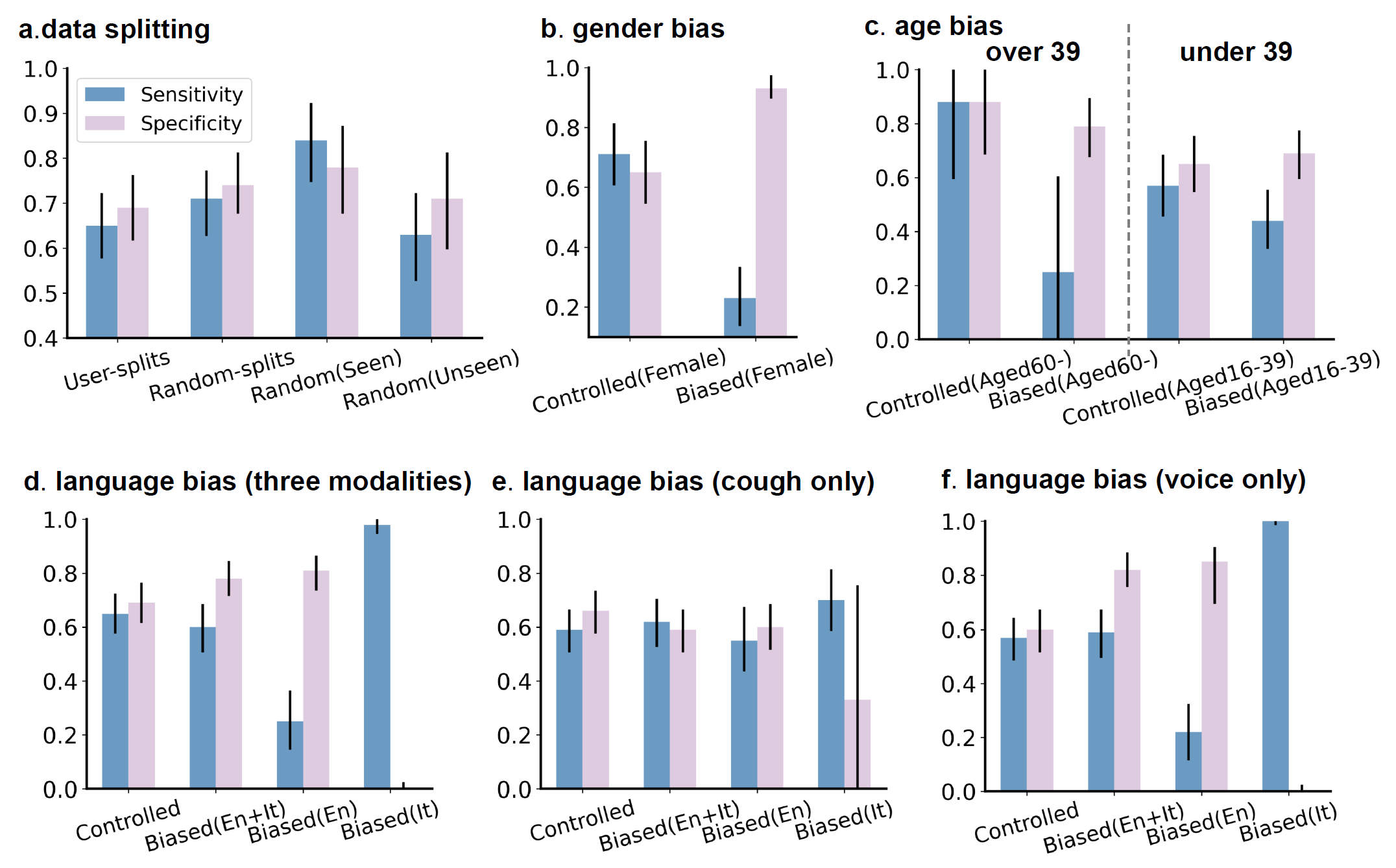
Fig. 3 Performance comparison. (a) User-independent splits v.s. sample-level random splits. (b) Controlled demographics v.s. gender bias. (c) Controlled demographics v.s. two types of gender biases: all negative participants in training set aged over 39 or under 39. (d, e) and (f) Model for English-speakers v.s. model for biased English- and Italian-speakers.
Conclusion: For digital technologies to penetrate the clinical practice, it is pivotal that studies become more explainable and that the models acquire resilience to data noise, variability and bias present in real data. We highlight the need for more realistic evaluation and report model performance when considering various factors in leveraging sounds for COVID-19 test. Our study makes one step in enabling medical doctors to accurately assess the practical value of this technology and further facilitate its application.
Key takeaways: To boost the trustworthiness of machine-learning-enabled healthcare applications, rigorous experimental setting and holistic evaluation are fundamental and crucial. Specifically, we suggest that developers pay attention to these facts:
- Character imbalance between the groups of ill and healthy data introduced in the training phase can lead to a biased model. The impact of confounders (demographics in our study) should be carefully controlled for model parameter learning.
- Systematic evaluation with reported sensitivity and specificity for various subgroups can help assess the model’s realistic performance and eliminate bias, which is desired before deployment.
For more details about our work, please refer to the paper published in npj Digital Medicine. We are also contributing the dataset collected and the model we developed in this study to the research community.
Reference:
[1] Schuller, B., et al. COVID-19 and Computer Audition: An Overview on What Speech & SoundAnalysis Could Contribute in theSARS-CoV-2 Corona Crisis. Frontiers in digital health 3 (2021): 14.
[2] Andreu-Perez, J. et al. A generic deep learning based cough analysis system from clinically validated samples for point-of-need COVID-19 test and severity levels. IEEE Transactions on Services Computing (2021).
[3]Coppock, H. et al. End-to-end convolutional neural network enables COVID-19 detection from breath and cough audio: a pilot study. BMJ Innovations 7, 356–362 (2021).
[4] Wynants, L., et al. Prediction models for diagnosis and prognosis of COVID-19: systematic review and critical appraisal. BMJ 369 (2020).
[5]Topol, Eric J. Is my cough COVID-19? The Lancet 396.10266 (2020): 1874.
[6] Coppock, H., et al. COVID-19 detection from audio: Seven grains of salt. The Lancet Digital Health 3.9 (2021): e537-e538.
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in