The efficient implementation of a full convolutional neural network with multiple memristor arrays
Published in Electrical & Electronic Engineering

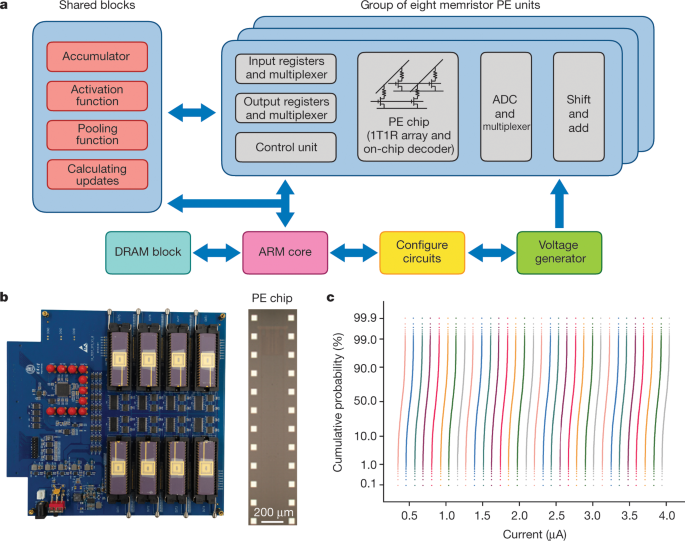
In conventional computing hardware, handling the artificial-intelligence (AI) related workloads requires frequent data shuttling between physically separated computing and memory units, which consumes extensive latency and energy and hinders the practical AI applications. Thanks to Ohm’s law and Kirchhoff’s current law, memristor-based neuromorphic computing is capable of conducting the parallel multiply-accumulate (MAC) functions, where the calculating happens at the data-storage location. This in-memory computing is promising to boost the computing efficiency in terms of the deep learning tasks than its counterparts based on von-Neumann architecture.
Nowadays, the experimentally memristor-hardware demonstrations focus on the neural networks with fully-connected (FC) structure, e.g. the perceptron, multi-layer-perceptron (MLP), recurrent neural networks (RNN, such as LSTM networks). Most of the existed works are based on single memristor array, which is divided into several portions to implement the weights of different layers. However, the most critical neural network model for computer version tasks, i.e. the convolutional neural networks (CNNs), is still missing, and the practical hardware architecture for deep neural networks require to split the weights to varied memristor arrays to jointly process the workloads. The major challenges are: (1) The inherent device variability, state-stuck issue, conductance drifts and other non-ideal characteristics in and between different memristor arrays [1]. (2) The efficient mapping of convolution networks to analog memristor arrays is still missing [2]. (3) In memristor based CNNs, due to many neurons share and reuse a small set of weight kernels in convolutional layers, it is less straightforward to implement convolutional operations with memristors than the fully-connected structure [2].

In this work, a versatile memristor-based computing architecture was proposed for neural networks, and accordingly, eight 2K memristor crossbar arrays were integrated to implement the system. The optimized device stacks and fabricating process lead to the memristor arrays exhibiting uniform intermediate states under identical programming conditions. In addition, we have experimentally demonstrated a complete memristor-CNN (mCNN) with the novel hybrid training method and proposed parallel computing technique on multiple memristor arrays.
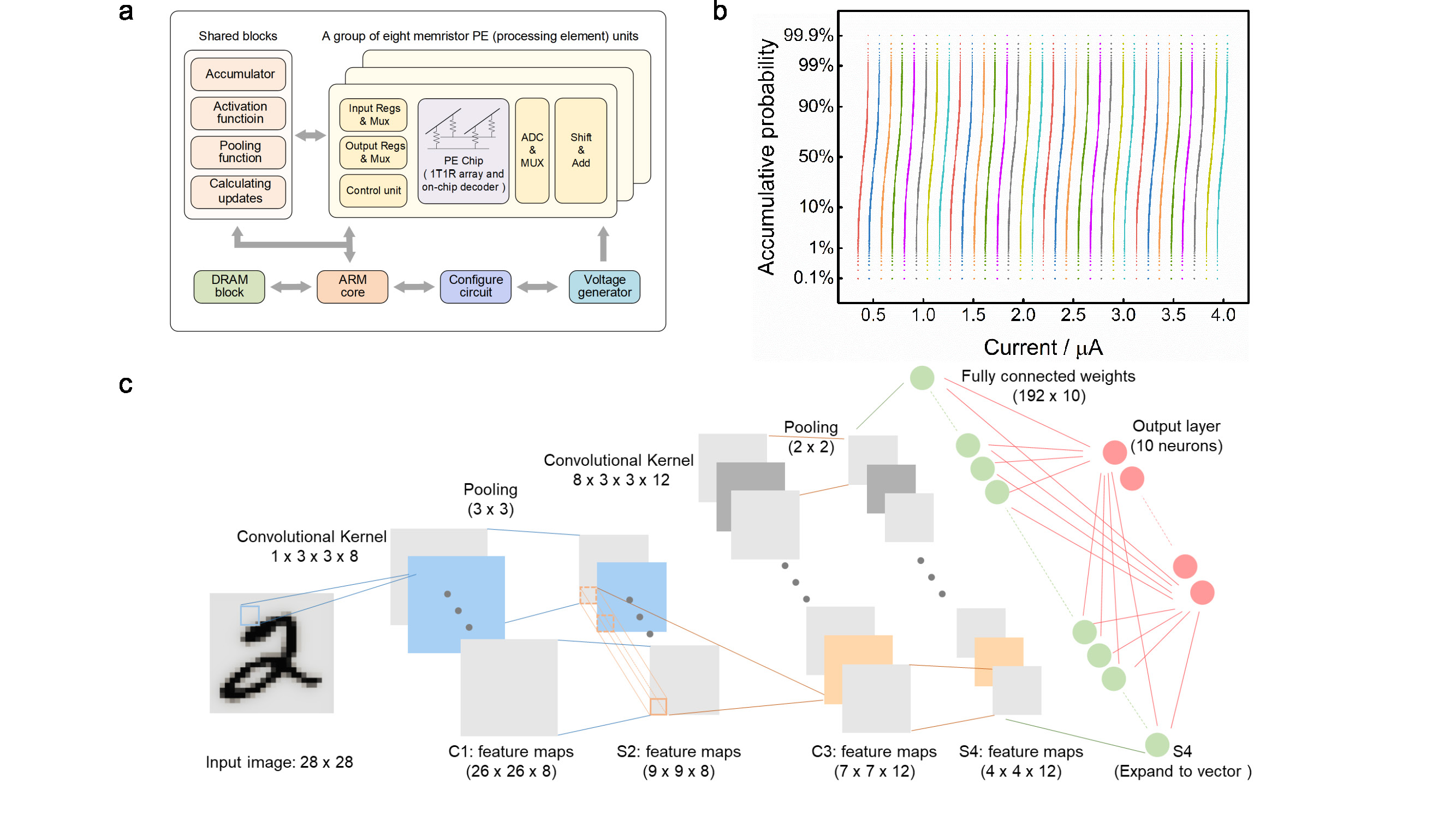
The non-ideal device characteristics are considered as the substantial hurdles to result in the system performance degradation. To circumvent various non-ideal factors, a hybrid training method is proposed to implement the mCNN. In hybrid training, the ex-situ trained weights are firstly transferred to the memristor arrays, and in next phase, only a part of the memristor weights are in-situ trained to recovery the system accuracy loss due to device non-ideal characteristics. In this work, only the last FC layer is in-situ trained.
In mCNN, the memristor-based convolutional operations are time-consuming due to the need to feed different patches of input during the sliding process. In this manner, we proposed a spacial parallel technique by replicating the same kernels to different groups of memristor arrays. These different memristor array could deal with different input data in parallel way and expedite convolutional sliding tremendously. The device non-ideal characteristics could incur the random transferring errors in different memristor groups regarding the same kernels, therefore, hybrid training method is adopted at the same time.
Eventually, A five-layer memristor-based CNN (mCNN) was successfully demonstrated and achieved and a high accuracy > 96%. After evaluating, the mCNN neuromorphic system presents more than two orders of magnitudes higher energy efficiency than state-of-the-art graphics processing units (GPU). The proposed hybrid training method and spacial parallel technique at system-level have shown to be scalable to larger networks like ResNET, and they could be extrapolated to more general memristor-based neuromorphic systems.
These results were recently published in Nature:
"Fully hardware-implemented memristor convolutional neural network", Nature. 577, pages641–646(2020)
https://www.nature.com/articles/s41586-020-1942-4
[1] Xia Q, Yang J J. Memristive crossbar arrays for brain-inspired computing[J]. Nature materials, 2019, 18(4): 309.
[2] Ambrogio S, Narayanan P, Tsai H, et al. Equivalent-accuracy accelerated neural-network training using analogue memory[J]. Nature, 2018, 558(7708): 60.
Follow the Topic
-
Nature
A weekly international journal publishing the finest peer-reviewed research in all fields of science and technology on the basis of its originality, importance, interdisciplinary interest, timeliness, accessibility, elegance and surprising conclusions.

Related Collections
With Collections, you can get published faster and increase your visibility.
Carbon Dioxide Removal
Publishing Model: Hybrid
Deadline: Jan 16, 2027


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in