Training large-scale optoelectronic neural networks with dual-neuron optical-artificial learning
Published in Computational Sciences
In recent years, there’s been a lot of excitement about using light for super-fast AI computing. Imagine computers that work at the speed of light, using optical computing devices. Although researchers were looking into this concept about 30 years ago, there's a renewed interest in this field because of the recent advances in optical modulation devices and the emergence of novel optical neural network architecture1,2,3,4 such as diffractive neural networks1,2,3. Today, optical neural networks have reached 500 ps-level inference speed5 and <1 photon per multiply6.
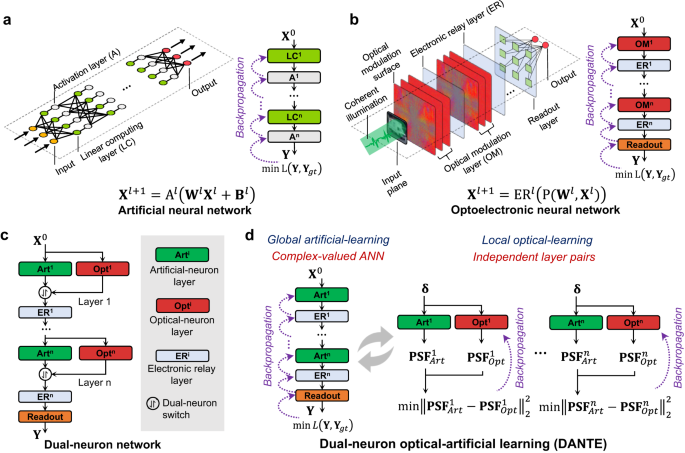
Just like how artificial neural networks work, current optical neural networks also organize the whole optical computing system into a large mathematical function and optimize the network parameters using back-propagation-based gradient descent. But, when it comes to large-scale optical neural networks, there’s a big challenge because of the intrinsic complexity of modeling the optical wavefronts. Let's take the recently popular diffractive neural networks (D2NN) as an example. The input-output relationship of a D2NN layer is derived based on Fourier optics, involving two 2D Fast Fourier Transformations (FFT) and element-wise multiplication. In contrast, an artificial neural network layer only consists of a straightforward multiplication operation. To put it in simple terms, training a D2NN layer is over ten times more complex than training an artificial neural network layer. This results in slower and more challenging convergence when training large-scale D2NN models.
At Tsinghua University, we are exploring dual-neuron training methods, aiming to enable the training and applications of large-scale optical neural networks. We keep asking: “Can we combine the well-established ANN neuron architecture and the potential ONN neuron architecture to make the training faster and better?”.
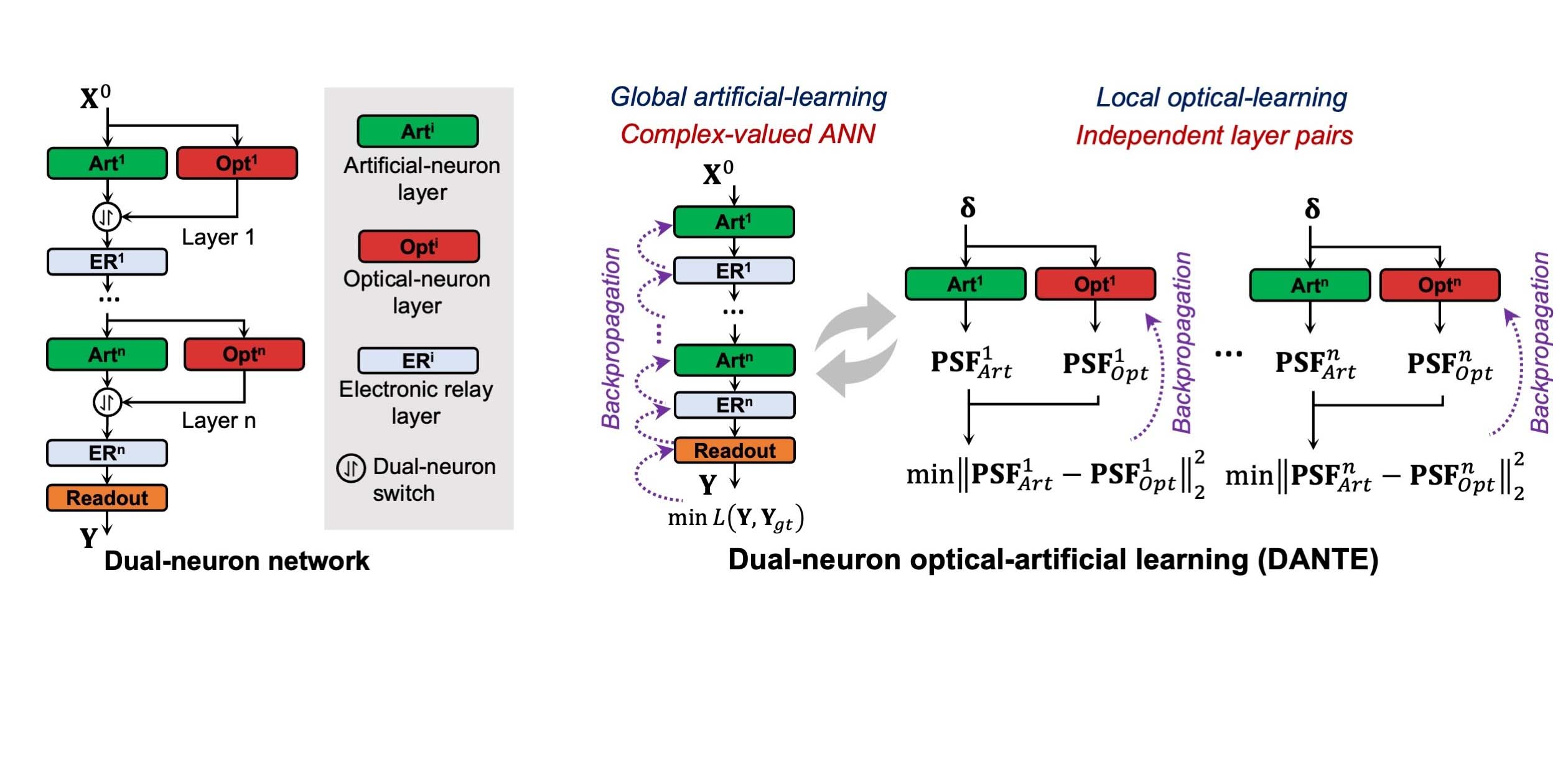
Dual-neuron optical-artificial learning (DANTE)
In our Nature Communications paper “Training large-scale optoelectronic neural networks with dual-neuron optical-artificial learning”, we introduce DANTE, a dual-neuron optical-artificial learning architecture. As depicted in the figure below, we represent the ONN using both optical-neuron layers and artificial-neuron layers. The optical-neuron layers accurately mimic how light behaves, while the artificial-neuron layers simplify the complex optical-diffraction modeling using lightweight functions. Unlike conventional learning methods, DANTE separates network learning into two steps: global artificial learning and local optical learning. By adding artificial neurons during global learning, we reduce the complexity of optimization and memory requirements, resulting in faster and better overall convergence. In the local optical learning step, the parameters in optical-neuron layers are learned efficiently from the optimized artificial neurons, rather than relying on extensive datasets, which further speeds up the network training process.
")
Enable the training of large-scale ONNs with DANTE
We first evaluate the capabilities of DANTE on two representative ONN designs: ONN-3-3 and ONN-3-7, in simulation experiments. In subfigure b below, we can see that DANTE brings significant improvements in both accuracy and training speed. Compared to the existing approach single-neuron learning approach, DANTE boosts the accuracy of ONN-3-3 from 73.61% to 82.53% and ONN-3-7 from 74.67% to 84.91%. Moreover, it makes the training process more than 100 times faster, reducing ONN-3-3’s training time from 60 hours to just 0.3 hours and ONN-3-7’s from 194 hours to 0.7 hours. To see how far we could go with DANTE, we scale up the networks even more, as displayed in subfigure c and d. On widely recognized benchmarks CIFAR-10 and ImageNet-32, we achieve performance similar to well-known neural networks, VGG-11 and VGG-16, respectively.

We also develop a physical ONN system using readily available optical devices to check if DANTE can work in the real world. The results prove that our physical ONNs can effectively extract features from the images encoded in the input optical fields, and enhance the image classification performance. Looking forward, there exists the exciting potential to integrate the physical ONN system with high-precision nanofabrication techniques, which could significantly elevate the computational capabilities. For further technical details, please refer to our research paper “Training large-scale optoelectronic neural networks with dual-neuron optical-artificial learning” available through open access.
To sum it up, our dual-neuron optical-artificial learning (DANTE) framework effectively tackles the learning challenges faced by ONNs, which arise from the intricate spatial and temporal complexities involved in optical diffraction modeling. Consequently, we have achieved remarkable success in training large-scale ONNs that were previously considered impossible to train using existing approaches. The experimental results demonstrate the enormous potential of ONNs in advanced machine vision tasks. We firmly believe that our research will establish a solid theoretical foundation for the training and deployment of large-scale ONNs, paving the way for a new era in which ONNs can solve large-scale practical problems.
Contact: fanglu@tsinghua.edu.cn
References
- Zhou, T. et al. Large-scale neuromorphic optoelectronic computing with a reconfigurable diffractive processing unit. Nat. Photonics 15, 367–373 (2021).
- Xu, Z. et al. A multichannel optical computing architecture for advanced machine vision. Light Sci Appl 11, 255 (2022).
- Chen, Y. et al. All-analog photoelectronic chip for high-speed vision tasks. Nature 623, 48–57 (2023).
- Zhou, T. et al.Ultrafast dynamic machine vision with spatiotemporal photonic computing.Sci. Adv.9,eadg4391(2023)
- Ashtiani, F. et al. An on-chip photonic deep neural network for image classification. Nature 606, 501–506 (2022).
- Wang, T. et al. An optical neural network using less than 1 photon per multiplication. Nat Commun 13, 123 (2022).
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Healthy Aging
Publishing Model: Open Access
Deadline: Dec 31, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in