Why Imputing Laboratory Data Matters
Published in Healthcare & Nursing
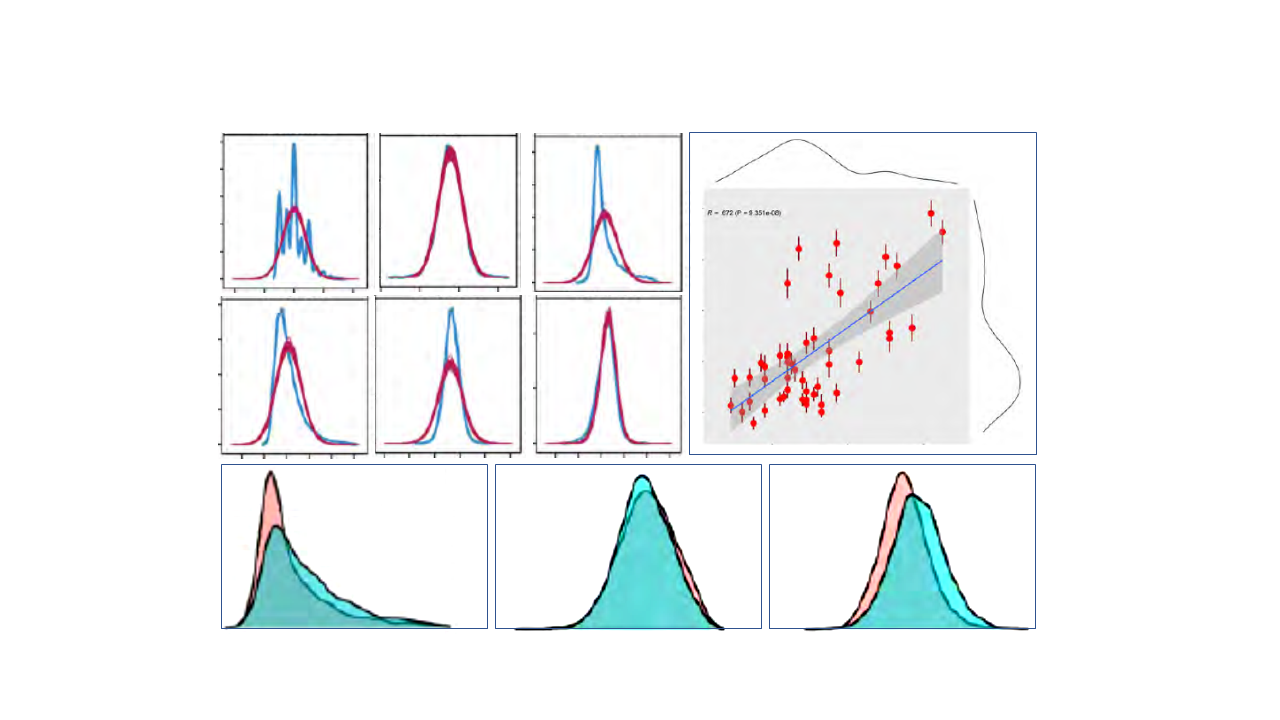
We believe for artificial intelligence (AI) to reach new heights and be fair, effort should be invested in improving the quality of the data and ensuring patients with a lower data footprint are included in the training data sets. Patients have a lower data footprint for many reasons, including, for instance, 1) having limited access to healthcare or superior insurance plans, 2) being younger and healthier, or 3) moving continuously across the different health systems. In this study, we investigated the pattern and mechanism of missingness and developed an imputation framework for the ‘real-world’ electronic health records (EHR) laboratory data.
What is unique about EHR data?
The expansion of EHR and recent advances in ML and AI have afforded opportunities to enhance models for outcome prediction, patient triaging, and identification of at-risk patients, among others.1 A carefully designed EHR-embedded clinical decision support system that could assist practitioners according to the practice guideline is a step towards real-time and personalized care delivery at scale. Even though data extracted from EHR are rich and longitudinal, they are asynchronous and non-trivial to analyze; EHR data has thousands of features, but with typically low prevalence for the outcome of interest and high not-completely-at-random missingness. For instance, even a standard laboratory variable such as hemoglobin A1c, the biomarker for diabetes, can have more than 40% missingness in a large EHR-based cohort used to predict mortality following vascular events.
What should one ask when designing experiments to impute laboratory data?
1) What is the pattern or mechanism of missingness in the variables of interest?
2) How to choose the algorithms and procedures for imputation of missingness?
3) How well to impute laboratory data in a cross-sectional design compared to a longitudinal design?
4) Can auxiliary variables based on comorbidity information be helpful in the imputation model?
5) How well is the conclusion made from a single dataset applied to an independent dataset with a different setup or missingness pattern – namely generalizability?
In this study, we
1) Provide a detailed description of the missing pattern and explore the missingness mechanism in the laboratory variables of the EHR from two distinct healthcare systems.
2) Perform simulation of two missingness patterns recognized in this study.
3) Present a comparative assessment of the well-established and commonly used imputation procedures.
4) Demonstrate the degree of the utility of latent information extracted from the comorbidity matrix, as auxiliary variables in the imputation model.
5) Evaluate the generalizability of the findings by analyzing two datasets with distinct disease cohorts from two different healthcare systems.
Understanding the missingness in EHR laboratory variables will help to recognize and tackle the missingness in other variables. The laboratory findings are weighted heavily in the diagnosis/prognosis of the diseases, and if not carefully designed, imputation or lack thereof can introduce systemic algorithmic bias. This bias is mainly due to the bias embedded in the model training dataset.
References:
- Noorbakhsh-Sabet N, Zand R, Zhang Y, Abedi V. Artificial Intelligence Transforms the Future of Health Care. Am. J. Med. [Internet]. 2019 [cited 2019 Apr 1];132:795–801. Available from: https://www.sciencedirect.com/science/article/pii/S0002934319301202
Follow the Topic
-
npj Digital Medicine
An online open-access journal dedicated to publishing research in all aspects of digital medicine, including the clinical application and implementation of digital and mobile technologies, virtual healthcare, and novel applications of artificial intelligence and informatics.

Related Collections
With Collections, you can get published faster and increase your visibility.
Synthetic Clinical Data and Privacy-Preserving Frameworks for Trustworthy Health AI
Publishing Model: Open Access
Deadline: Jun 03, 2027
Digital Biomarkers for Enabling Proactive Clinical Decisions
Publishing Model: Open Access
Deadline: May 18, 2027
Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in