AI Learns the Secrets of Tipping Points
Published in Social Sciences, Mathematics, and Statistics

Imagine a financial market teetering on the brink of a bubble or crises, an - apparently drowsy- disease outbreak escalating on a social network or a seemingly stable climate tipping into a cascade of extremes: scorching heat, vanishing water, and rising seas. These scenarios highlight the challenges of studying tipping points in complex systems. Traditional methods, like high-fidelity agent-based models (ABMs), offer valuable insights, but their computational demands can be a real roadblock.
This is where our research steps in. We propose a groundbreaking framework that harnesses the power of Machine Learning to analyze tipping points in large-scale ABMs. Here's the computational trick : we extract low-dimensional "hidden patterns" from the data, allowing us to develop efficient models -- learned from observations-- that capture the key dynamics near tipping points.
The Big Picture: Our approach offers several benefits:
- Reduced Complexity: By focusing on the core dynamics, we significantly decrease computational costs compared to the high-dimensional ABM.
- Unveiling Secrets: We identify the underlying mechanisms driving tipping points, providing valuable insights for prevention or mitigation.
- Quantifying the Unlikely: We calculate the probability of rare, catastrophic events triggered near tipping points.
In the recent publication in Nature Communications (Fabiani et al. 2024), the Professor Kevrekidis group in collaboration with the Professor Siettos group, implement an efficient machine learning framework bridging numerical analysis, neural networks, Gaussian processes and the equation-free framework.
Our work paves the way for estimating probabilities of rare events in complex systems, and detect tipping points/catastrophic shifts.
The developed code is available in a Gitlab repository.
Lab photo at DDE 2023 conference in Naples
The Kevrekidis and Siettos research groups at a recent conference (including collaborators not pictured) - where the final revisions for this paper were completed!
Background
Complex systems often exhibit multiscale phenomena, leading to unexpected emergent behaviors, including catastrophic shifts. These shifts, which represent significant and often irreversible changes in the system's behavior, occur more frequently near tipping points. Tipping points, often linked to bifurcation points in nonlinear dynamics, are critical to understanding and predicting these major transitions.
Accurately computing the frequency and probability of such transitions, as well as detecting the tipping points that drive them, is crucial across many domains. Traditional approaches using Agent-Based Models (ABMs) have been essential in digital twin modeling for applications in ecology, epidemiology, and economics. However, these high-fidelity models often require extensive, computationally expensive simulations, particularly in high-dimensional spaces.
To overcome these challenges, a systematic analysis involves two key tasks: identifying low-dimensional collective variables to describe emergent dynamics and constructing reduced-order models (ROMs) for efficient numerical analysis. Techniques like diffusion maps, ISOMAP, and autoencoders help discover these variables. Subsequently, data-driven methods such as SINDy, Gaussian process regression, neural networks, and random projection neural networks are employed to develop surrogate models.
Illustrative case studies include a financial market ABM showing the onset of a bubble and an epidemic ABM on a social network demonstrating outbreak dynamics. Both reveal that the emergent behaviors around tipping points can be effectively captured on low-dimensional manifolds, significantly reducing computational costs.
We compare the advantages and disadvantages of various surrogate models and the effort required to train them. Notably, our framework shows that near tipping points, the complex behaviors of both benchmark examples can be accurately captured by a one-dimensional stochastic differential equation. This finding highlights the fundamental dimensionality of the normal form associated with these tipping points, leading to a substantial decrease in computational costs for the tasks at hand.
Methodology Insights
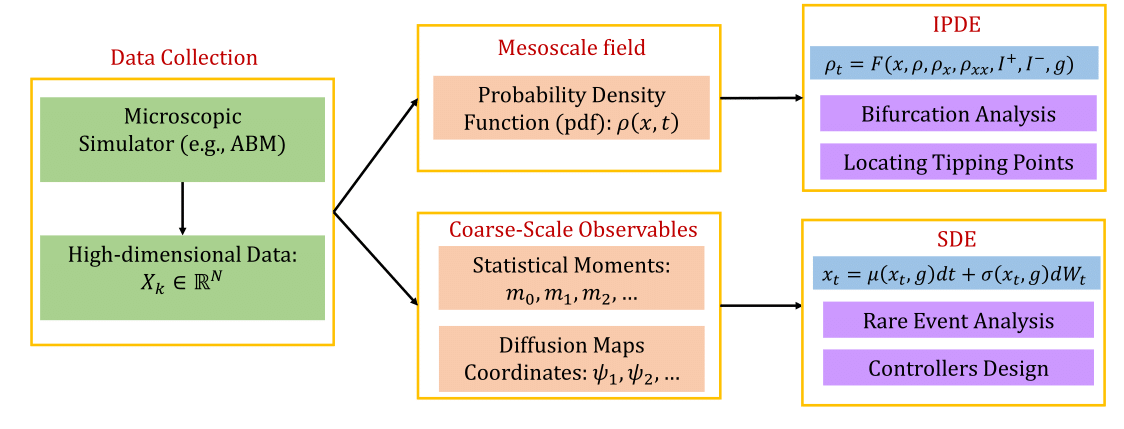
Given high-dimensional spatio-temporal trajectory data from ABM simulations, the framework involves the following steps :
- Discover Hidden Patterns: Identify low-dimensional latent spaces to describe the emergent dynamics at the mesoscopic or macroscopic scale.
- Identify Surrogate Models: Use machine learning to develop black-box mesoscopic IPDEs, ODEs, or, after further dimensional reduction, macroscopic mean-field SDEs.
- Locate Tipping Points: Perform numerical bifurcation analysis on the surrogate models to identify tipping points.
-
Rare-Event Analysis: Utilize the identified mean-field SDEs for uncertainty quantification of catastrophic transitions. This involves:
- Performing repeated brute-force simulations around the tipping points.
- Applying statistical mechanical (Feynman-Kac) formulas for escape time distributions in the effectively 1D problem
Neural Network approaches for learning the dynamics
Imagine a powerful learning tool loosely inspired by the brain. This tool, called a artificial neural network, can be used to create simplified models that capture the essence of complex natural phenomena.
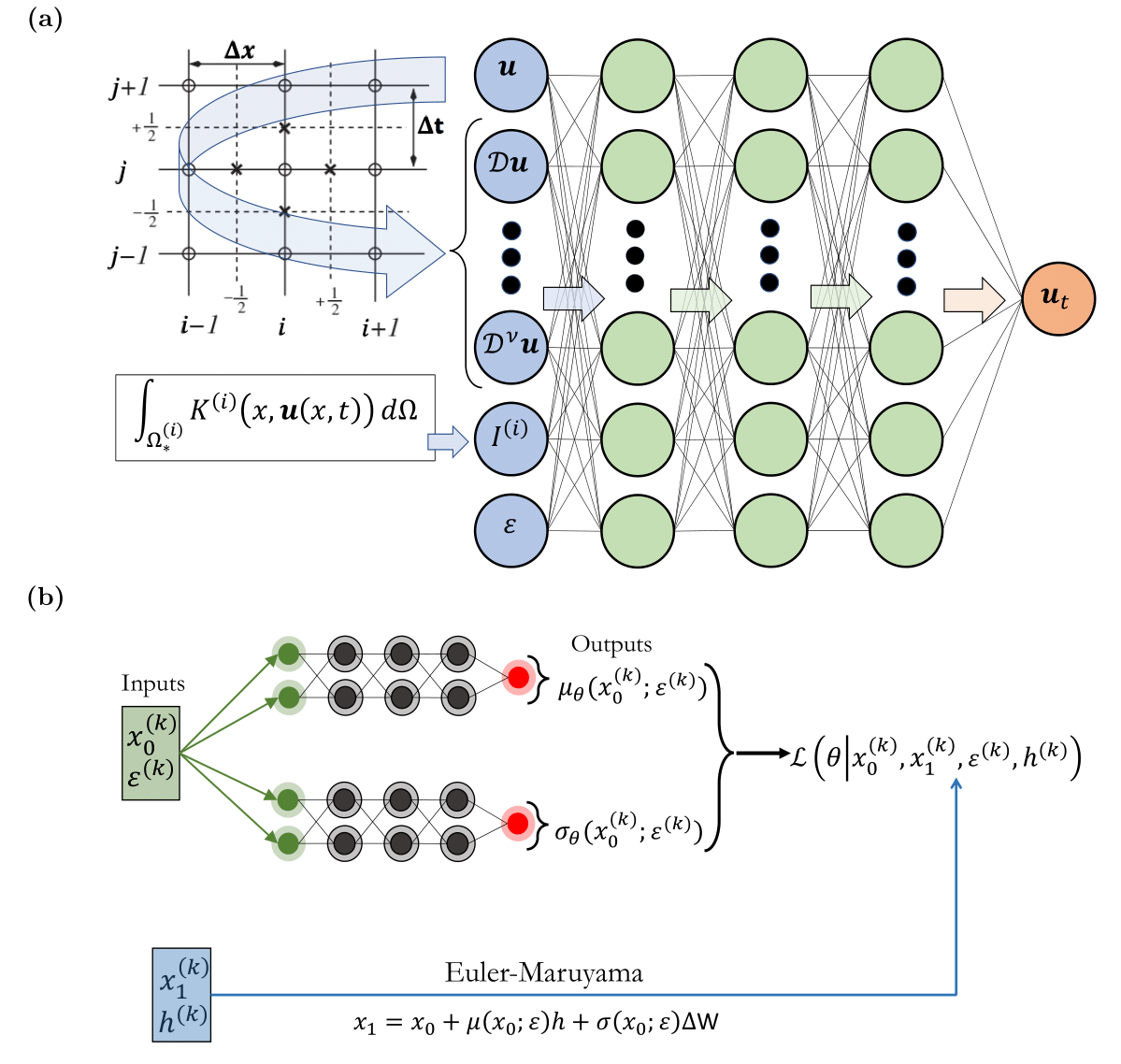 Schematic of the neural networks used for constructive machine learning assisted surrogates. (a) Convolutional Neural Network (CNN). The input is constructed by convolution operations, i.e. a combination of sliding Finite Difference (FD) stencils, and, integral operators, for learning mesoscopic models in the form of Integro-PDEs; the inputs of the Integro-PDE are local and/or global features .
Schematic of the neural networks used for constructive machine learning assisted surrogates. (a) Convolutional Neural Network (CNN). The input is constructed by convolution operations, i.e. a combination of sliding Finite Difference (FD) stencils, and, integral operators, for learning mesoscopic models in the form of Integro-PDEs; the inputs of the Integro-PDE are local and/or global features .
(b) A schematic of the neural network architecture, inspired by numerical stochastic integrators, used to construct macroscopic models in the form of mean-field SDEs.
Our investigation into complex natural phenomena utilizes two key neural network architectures:
-
Type 1: Convolutional Neural Networks: Finding patterns in small-scale details (a): The first delves deep. It employs specialized filters and calculations to analyze intricate data points, akin to examining tiny clues. By meticulously dissecting these details, it uncovers the underlying "rules" governing small-scale behavior. These insights then empower the creation of simplified models that effectively capture the overall dynamics of the system.
-
Type 2: SDE-Network: Understanding the bigger picture (b): The second network adopts a broader perspective. Inspired by scientific methods for simulating random events, it unveils the average behavior of the entire system. This strategic approach grants us a deeper understanding of how the system typically unfolds on a larger scale.
In both cases, the neural networks learn from data (like measurements or simulations) to create these simplified models. By harnessing the power of both these specialized neural networks, we gain a comprehensive view of complex natural phenomena, from the intricate details to the overarching patterns.
The illustrative case: an event-driven financial market ABM
Imagine a large group of investors (like 50,000) constantly bombarded with financial news. Each investor has a "buying/selling mood" that sways between positive (wanting to buy) and negative (wanting to sell). This mood is influenced by two things:
- Actual News: This could be positive news that makes them want to buy or negative news that makes them want to sell.
- What Others Are Doing: This is where it gets interesting! The model considers how much investors are influenced by what others are doing (mimetic behavior). A high "mimesis strength" means investors are more likely to follow the crowd.
Here a video:
Here's the key finding: When the "mimesis strength" gets too high (think everyone copying everyone else), the whole market gets unstable. This can lead to "financial bubbles" where everyone rushes to buy, driving prices up way too high. Eventually, the bubble bursts, and everyone rushes to sell, leading to a crash.
Numerical Results
We investigated how well artificial intelligence (AI) (neural networks model) could predict these tipping points and reduce the computational cost associated with the estimation of the rare events probability.
The study compared two different neural network models. Both models effectively predicted the critical point where the system becomes unstable. The first, the convolutional neural network, is used to learn a global surrogate model (an integro-PDE operator). The second, the SDE-neural Network, learns a coarse-scale targeted model in the vicinity of the tipping points which can also reproduce the stochastic volatility of the macroscopic emergent dynamics. Thus, allowing for rare events computations.
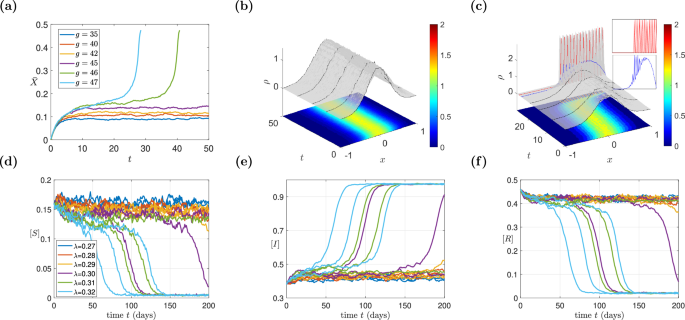
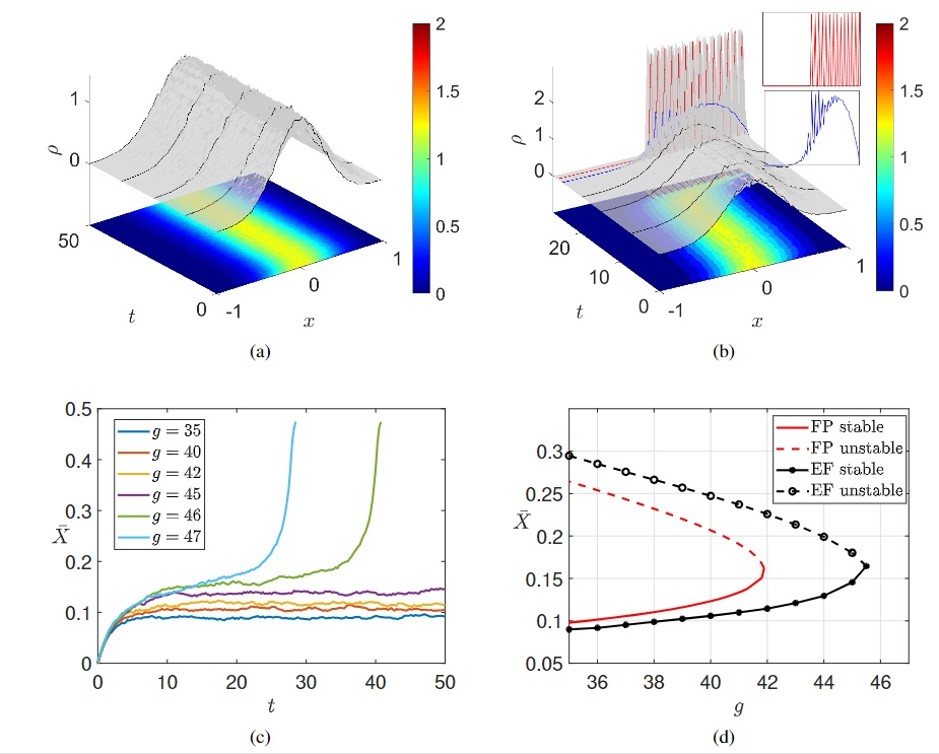
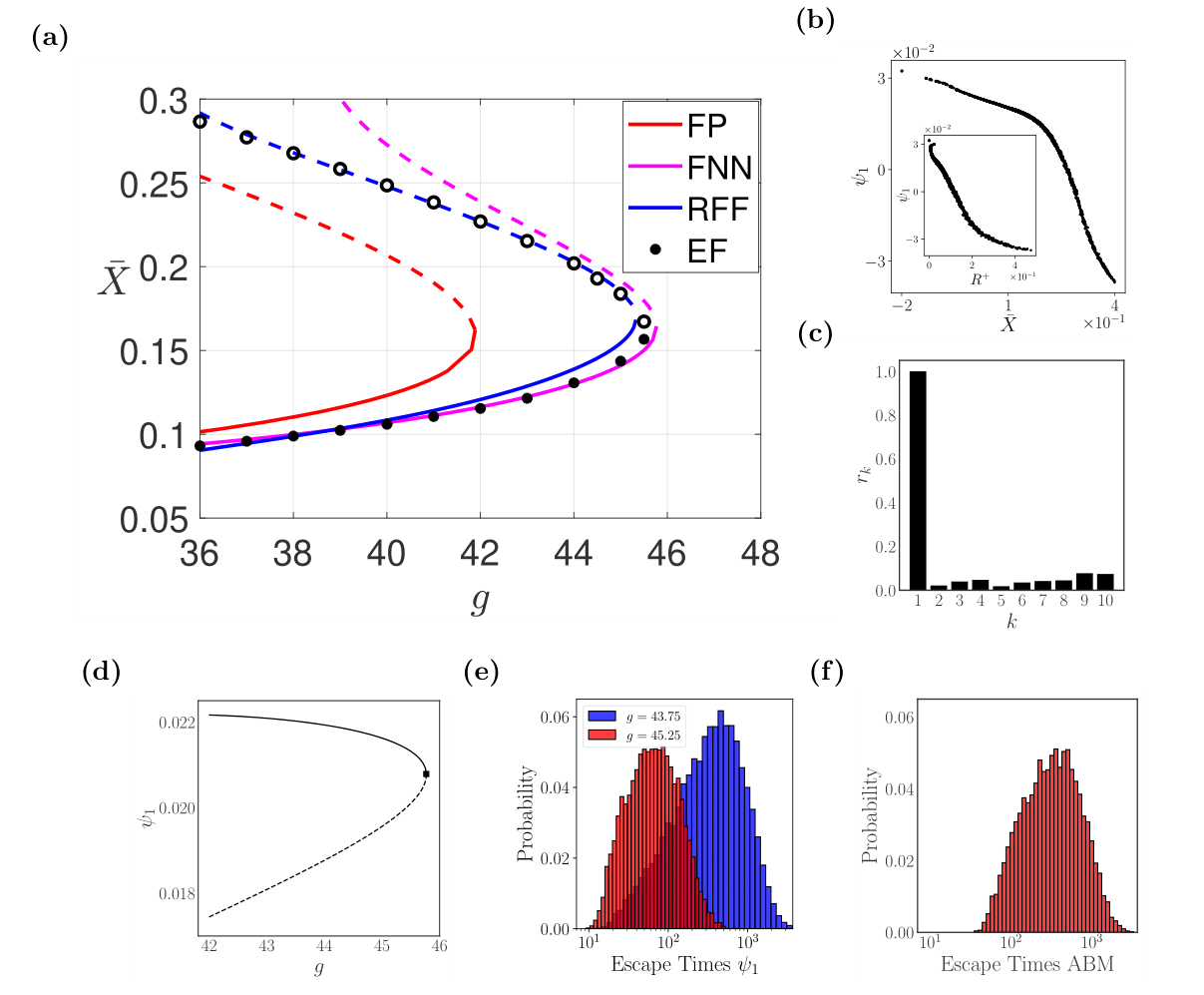 Panel (a): This looks at how a key factor (represented by "") affects the overall stability of the market. Imagine a switch: above a certain value of "" the market might behave differently. The neural networks (FNN & RFF) accurately locate the tipping point whereas the analytical Fokker-Planck (FP) model does not. Panels (b) and (c): Here feature selection algorithms show the corresponding low-dimensional behavior. These focus on the overall behavior of the group, instead of the individual behavior of the agents (like investors) within the market simulation. They look at how their preferences and actions change based on the overall market state. Panel (d): This describe the market stability in terms of the low-dimensional machine-learning derived variable. Panels (e) and (f): These explore how quickly things can change in the market simulation when the system is close to a tipping point. They show how long it takes for the market to left the stable state and undergo to a catastrophic shift in the presence of noise.
Panel (a): This looks at how a key factor (represented by "") affects the overall stability of the market. Imagine a switch: above a certain value of "" the market might behave differently. The neural networks (FNN & RFF) accurately locate the tipping point whereas the analytical Fokker-Planck (FP) model does not. Panels (b) and (c): Here feature selection algorithms show the corresponding low-dimensional behavior. These focus on the overall behavior of the group, instead of the individual behavior of the agents (like investors) within the market simulation. They look at how their preferences and actions change based on the overall market state. Panel (d): This describe the market stability in terms of the low-dimensional machine-learning derived variable. Panels (e) and (f): These explore how quickly things can change in the market simulation when the system is close to a tipping point. They show how long it takes for the market to left the stable state and undergo to a catastrophic shift in the presence of noise.
Take-Home Messages
Preventing catastrophic shifts by designing effective control policies is one of our biggest challenges today. Climate change, ecosystem extinctions, pandemics, and economic crises can all be triggered by small changes or random events near tipping points. These tipping points are usually linked to bifurcations in system dynamics, making it crucial to identify and understand these mechanisms and quantify their probabilities.
Real experiments to study these phenomena on a large scale are often impractical or unethical, so high-fidelity agent-based models (ABMs) serve as vital tools to create informative "digital twins." However, the complexity of these models makes the task computationally demanding.
We propose a machine-learning framework to infer tipping points in large-scale ABM simulations. This involves constructing mesoscopic and mean-field-level ML surrogates from high-fidelity data to locate bifurcations and quantify the probability of catastrophic shifts. Our approach was illustrated using two ABMs: one modeling trader behavior in financial markets and another modeling epidemic spread on social networks. Both models reveal tipping points leading to financial bubbles and epidemic outbreaks, respectively.
While traditional analytical surrogates offer some physical insights, they can bias bifurcation analysis and tipping point detection. In contrast, our approach uses manifold learning to identify low-dimensional latent spaces and learn mean-field-level SDEs, providing a computationally efficient alternative. However, this method may result in variables that are not explicitly interpretable.
Different modeling tasks require different surrogates, emphasizing the importance of choosing the right ML approach for each task. Future work may extend to more general classes of SDEs or even fractional evolution operators for more informative models. Although our focus is not on constructing early warning systems, the collective variables identified through our framework could serve as potential coordinates for such systems.
Our main goal is to show how machine learning can systematically construct reduced-order models to understand and analyze the mechanisms behind tipping points and quantify rare event probabilities from detailed ABM simulations, addressing the curse of dimensionality.
This blog post only scratches the surface! The full paper delves deeper into the technical details of the model, the mathematical underpinnings, and the broader implications of the findings. If you're interested in a deeper dive, I highly recommend checking out the original research paper
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Biosensing
Publishing Model: Hybrid
Deadline: Sep 30, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in