Building foundations from Datathons to Open Data
Published in Computational Sciences and Statistics

Explore the Research
BOLD: Blood-gas and Oximetry Linked Dataset - Scientific Data
Scientific Data - BOLD: Blood-gas and Oximetry Linked Dataset
In the 21st century, an increasingly educated, technological, and globalized world, the prejudices that we witness in various societies are incomprehensible; yet they persist, seem to grow larger, and mercilessly leave historical learning behind. Prejudices are usually rooted in limited, positive or negative, personal experiences. These beliefs are then ingrained over generations through a process of social cognition that simplifies the complexities of social groups into simplistic and harmful labels.
As active citizens, we all have naturally been aware of these social issues, but it was not until recently that we realized that these social issues are also rooted in the way we do science and build our knowledge systems.
As we read more and more about these topics, it is now evident that medicine and engineering are not innocent in contributing to these social injustices. Of course, health disparities have been recognized for years, but recent artificial intelligence (AI) breakthroughs have shed a spotlight on these issues. AI has not only proven to be very skilled in perpetuating racial biases and generating unfair outcomes or predictions, but has also made us ask: “why is AI biased?”. Knowing how machine learning works, the logical answer to that question is that AI is biased because we humans are too, and AI is very good at learning patterns from data. Garbage in, garbage out.
But what biased patterns are these?
Racial bias in pulse oximetry medical devices stands out as a quintessential health inequity. Although the unreliability of pulse oximetry has been a reason for concern for decades, it was not until the COVID-19 pandemic that this was associated with race, as a surrogate for skin tone. Pulse oximeters estimate arterial oxygen saturation by measuring light absorption of oxyhemoglobin and deoxyhemoglobin in capillary blood, but this physical principle can be independently affected by skin tone. In other words, these devices are well calibrated for White patients, but not as much for darker-skinned patients.
The MIT Critical Datathon
In May 2023, our research group, MIT Critical Data, led by Dr. Leo Anthony Celi, organized the MIT Critical Datathon (i.e, data + hackathon), as we sought data-driven solutions to mitigate the pulse oximetry bias. To address such a complex and open-ended problem, we gathered talented high school and undergraduate students from underrepresented groups, as well as health equity investigators across several disciplines: data scientists, physicians, nurses, and pharmacists. With a 1:1 student-mentor ratio, throughout two intense days of coding, we set out to find the best pulse oximetry correction models.

By the end of the datathon, we had a handful of reasonable pulse oximetry correction models, loads of great discussions, and more questions than we started the event with. (Figure 1) However, we realized how arrogant it would be to think that we could solve such a complex problem in two days, with a single dataset from Boston, and a limited group of people. Therefore, we came to the conclusion that we need a better understanding of the pulse oximetry problem and its causal drivers; more open data and better curation; and an even more inclusive community to work on this issue!
BOLD: a blood-gas and oximetry linked dataset
Fast forward a year, “BOLD: a blood-gas and oximetry linked dataset” is now published as an article on Scientific Data and the data is publicly-available on PhysioNet. Since the MIT Critical Datathon, we expanded the original dataset that we prepared for the challenge, to include three electronic health records (EHR) databases: MIMIC-III, MIMIC-IV, and eICU-CRD, comprising and a wide array of variables that could be related to pulse oximetry bias.
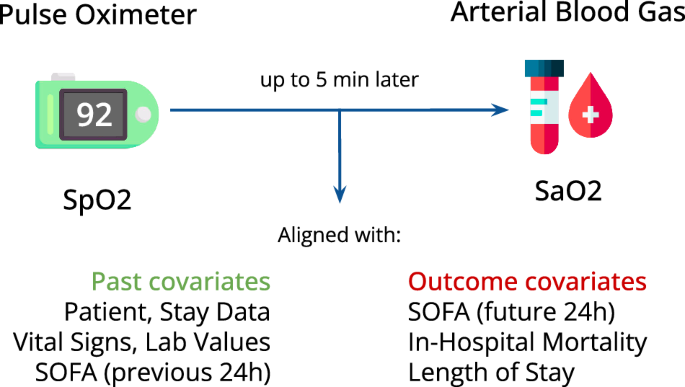
Pulse oximeters measure peripheral arterial oxygen saturation (SpO2) noninvasively, while the gold standard (SaO2) involves arterial blood gas measurement. Paired SpO2 and SaO2 measurements were time-aligned and combined with various other sociodemographic and parameters to provide a detailed representation of each patient. BOLD includes 49,099 paired measurements, within a 5-minute window, and with oxygen saturation levels between 70–100%. (Figure 2)

Our curated dataset eliminates a key barrier to entry in the field of data science for critical care. Its creation required the involvement of specialized and multidisciplinary teams of data scientists and clinicians who can navigate complex EHR databases from different health systems. With its public release, our hope is that it will serve as a test bed for future generations of trainees.
Impact
The dataset has been used as an educational tool in other events around the world, such as the “Collaborative Data Science in Healthcare” (BST 209) Summer course, at Harvard T.H Chan School of Public Health and the 3rd Big Data Machine Learning Healthcare Datathon, at the Tokyo Medical and Dental University, in Japan. (Figure 3)

Our published research and dataset not only address the critical issue of pulse oximetry disparities but also offer versatile tools for the broader medical research community. By detailing our methodologies and sharing our modular scripts (GitHub, Figure 4), we provide avenues for other researchers to build upon this work, potentially extending it to other biometric readings (e.g., body temperature, blood pressure), clinical contexts (e.g., home-based care, primary care, emergency room), or data systems (e.g., in their own health system’s databases).

Conclusion
Pulse oximetry bias is just one of the many systemic biases that occur at the crossroads of medicine and engineering. With this work, we hope to pave the way to advance a specific health equity issue, through definition of data curation and harmonization standards, promotion of open data, and community building. (Figure 5)

Figure 5. Participants of the MIT Critical Datathon, May 18–19, 2023, Cambridge, MA.
We invite you to explore BOLD and contribute to our collective journey towards more equitable medicine!
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Jul 10, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in