Can Large Language Models reason about emotions like humans?
Published in Computational Sciences and Behavioural Sciences & Psychology

Emotions are the glue of our social lives. People who are skilled at recognizing, understanding, and managing their own and others’ emotions—what psychologists call ability emotional intelligence (EI)—tend to form stronger relationships, communicate more effectively, and navigate social situations with ease. But EI isn’t just a valuable human skill; in an increasingly technology-mediated world, it’s becoming essential for machines as well. Social agents like mental health chatbots, educational tutors, and customer service avatars are now designed to support emotionally sensitive interactions, where understanding human emotions is key.
While the field of affective computing has made remarkable progress over recent decades—enabling these agents to detect emotional cues such as joy, fear, anger, or boredom through visual, auditory, or textual input—the emergence of Large Language Models (LLMs) like ChatGPT marks a new potential breakthrough: These models promise to greatly enhance agents’ ability to respond with greater fluency and flexibility in emotionally charged conversations, using natural, context-sensitive language.
However, to be effective in emotionally demanding situations—offering appropriate advice or drawing accurate conclusions—LLMs must also demonstrate a deep understanding of emotions: their causes, expressions, and regulation. Without this foundation, their usefulness in emotionally intelligent applications may be limited. Since these components closely align with what we, as researchers of human emotional intelligence, define as ability EI (Mortillaro & Schlegel, 2023), our central question in this study was:
Can LLMs emulate human ability emotional intelligence?
To explore this question, we conducted a two-part study recently published in Communications Psychology. First, we tested whether six leading LLMs—ChatGPT-4, ChatGPT-o1, Gemini 1.5 Flash, Copilot 365, Claude 3.5 Haiku, and DeepSeek V3—could complete five established performance-based EI tests, such as the Situational Test of Emotion Understanding (STEU; MacCann & Roberts, 2008) and the Geneva Emotional Competence Test (GECo; Schlegel & Mortillaro, 2019). These tests assess ability EI by presenting emotionally charged scenarios and asking for the most emotionally intelligent response. For example, one item describes "Alex walking home from work and suddenly feeling fear," then asks what most likely caused it: (a) forgetting office keys, (b) hearing laughter, (c) seeing a barking dog behind a fence, or (d) hearing footsteps in a dark alley. The correct answer—(d)—represents a situationally appropriate source of fear (see Fig. 1)
Figure 1: Example item assessing emotion understanding
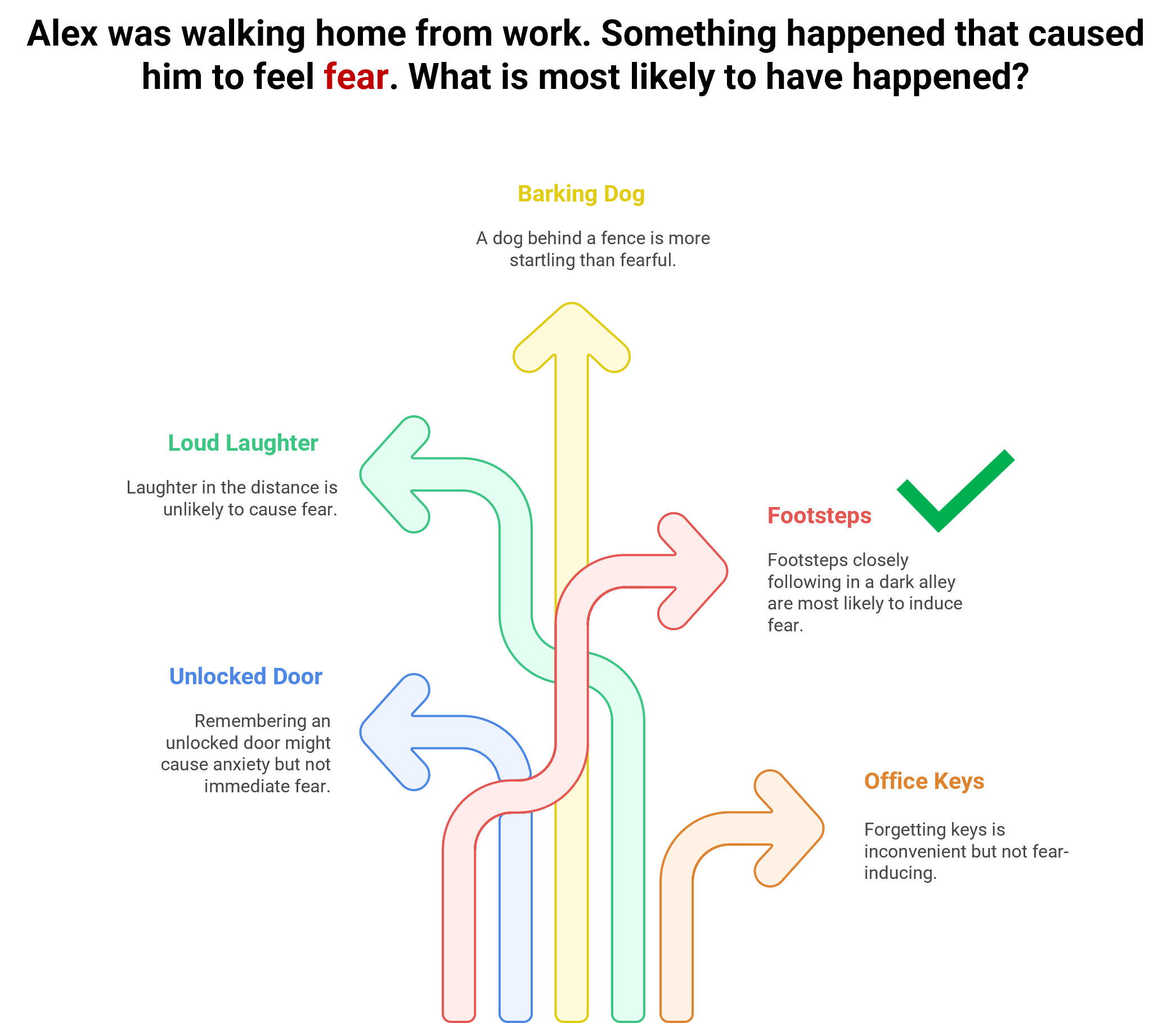
The results were striking: all LLMs performed well, and most outperformed human benchmarks (see Fig. 2). While humans averaged 56% correct, LLMs achieved 81%, suggesting that they already possess a robust understanding of emotional cues—at least in structured settings.
Figure 2: 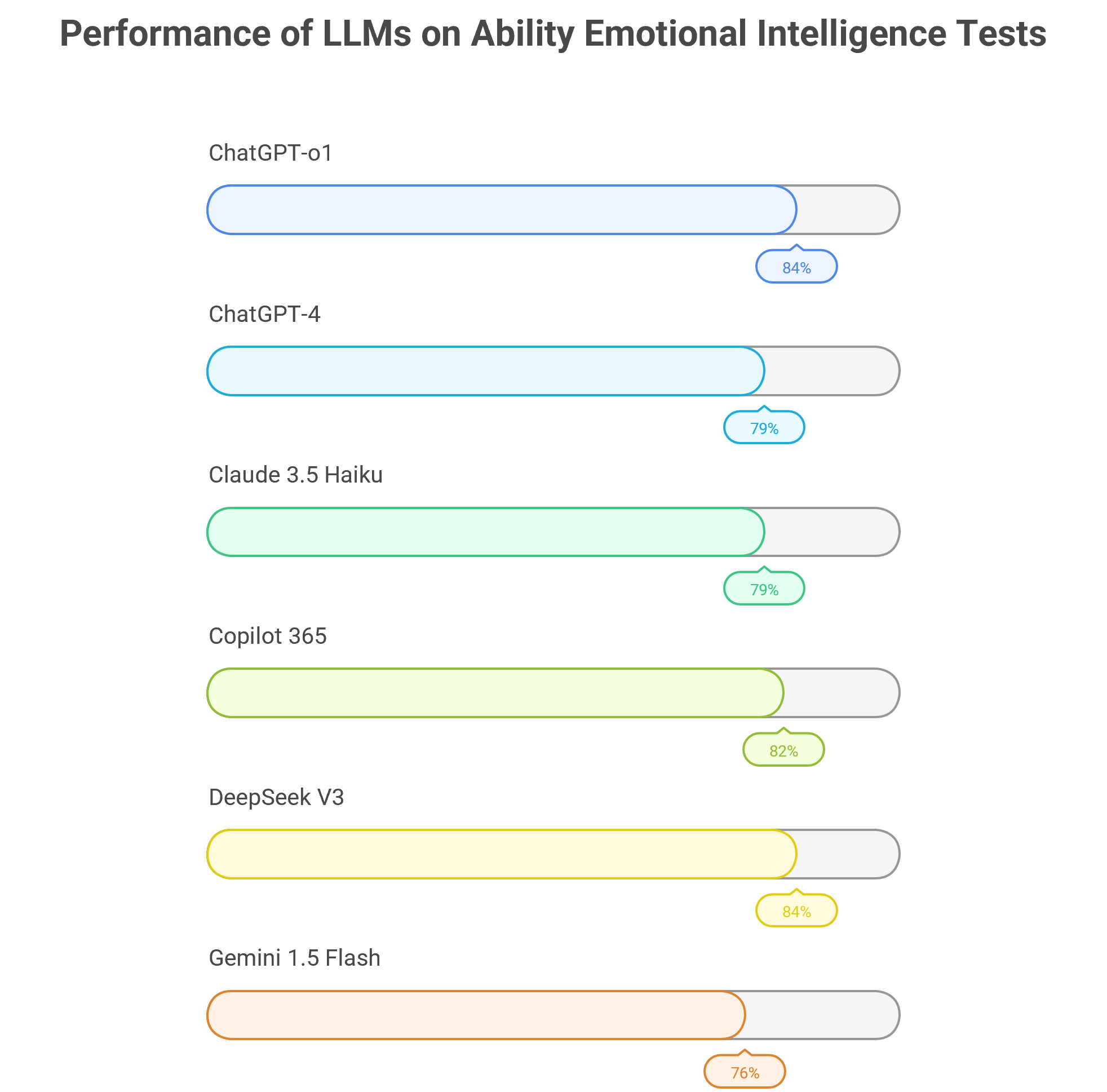
In the second phase, we took the project one step further. We asked ChatGPT-4 to generate entirely new EI test items, which we then administered to 467 participants across five studies. Each participant completed one original test (e.g., the STEU), one ChatGPT-generated version of that test, a vocabulary test (to measure crystallized intelligence), and an additional EI test to assess construct validity. Participants also rated both test versions for clarity, realism, and item diversity (see Fig. 3).
Figure 3: Overview of the second phase of our project
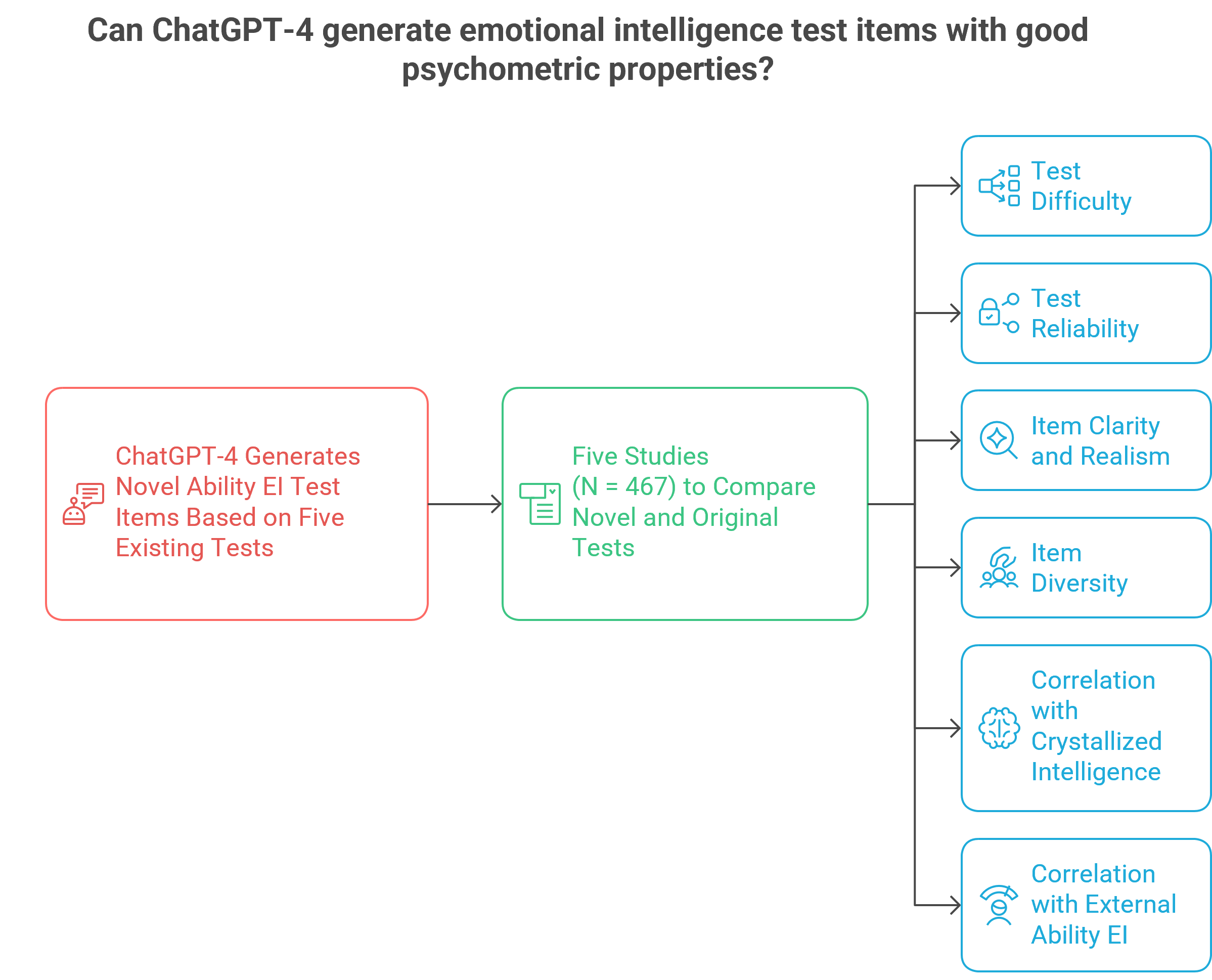
The findings were encouraging:
AI-generated tests were rated as equally clear and realistic as the originals and showed similar levels of difficulty, reliability, and validity. This overall performance suggests that ChatGPT-4 not only understands emotional concepts but can creatively apply them to produce psychometrically sound assessments. In our view, the ability to both solve and construct such tests reflects a high level of conceptual understanding.
So what does it all mean?
From an EI perspective, these findings have both practical and theoretical implications. Practically, they point to new possibilities in developing emotion-related assessments and training materials. Traditionally, creating reliable performance-based EI tests is time-intensive, involving scenario development, response crafting, and large-scale validation. Our results suggest that ChatGPT-4 can significantly accelerate this process, generating diverse and valid content with minimal input. In professional and educational settings—such as Social Emotional Learning (SEL) programs—LLMs could be used to produce tailored training scenarios for domains like healthcare or hospitality, enhancing discussion, reflection, and skill-building.
Theoretically, our findings contribute to the ongoing debate over whether AI can “possess” empathy (Inzlicht et al., 2024; Perry, 2023). While affective empathy—feeling what others feel—may remain out of reach for current systems, cognitive empathy—understanding what others feel—appears well within their capabilities. Even without subjective experience, AI agents can behave as if they understand and care: offering advice, practicing active listening, and helping users feel supported. In many applied contexts, from mental health bots to caregiving robots, this may be sufficient to produce meaningful outcomes.
Moreover, LLMs offer distinct advantages in emotionally demanding contexts. Unlike humans, whose emotional responses can vary due to mood, fatigue, or stress, AI systems provide consistent performance. Research shows that human emotional competence often diverges between maximal performance (what people can do) and typical performance (what they usually do). For example, people may avoid interpreting others’ emotions accurately if doing so is uncomfortable (e.g., Simpson et al., 2011). In contrast, LLMs can deliver optimal performance in every interaction.
Still, important questions remain.
Emotional understanding in natural conversation is often subtle, ambiguous, and shaped by cultural context. Our study focused on well-structured test vignettes, leaving it unclear how well LLMs perform in the messiness of real-life interactions. Moreover, the research was conducted in Western contexts, using tests developed in Australia and Switzerland, and LLMs like ChatGPT-4 are trained predominantly on Western-centric data. Yet emotional expressions, display rules, and regulation strategies differ significantly across cultures, and what is considered emotionally intelligent in one culture may be inappropriate in another.
Looking ahead
Despite their limitations, our findings suggest that LLMs can be valuable tools in human-machine interactions. Looking ahead, we are eager to see these technologies further developed and validated across cultures and used to help humans in navigating the emotional aspects of their daily lives. As researchers, we see great potential in integrating emotion theory with AI to create tools that foster connection, emotional insight, well-being, and meaningful productivity in an increasingly digital world.
References
Inzlicht, M., Cameron, C. D., D’Cruz, J., & Bloom, P. (2024). In praise of empathic AI. Trends in Cognitive Sciences, 28(2), 89–91. https://doi.org/10.1016/j.tics.2023.12.003
MacCann, C., & Roberts, R. D. (2008). New paradigms for assessing emotional intelligence: Theory and data. Emotion, 8(4), 540–551.
Mortillaro, M., & Schlegel, K. (2023). Embracing the emotion in emotional intelligence measurement: Insights from emotion theory and research. Journal of Intelligence, 11(11), 210. https://www.mdpi.com/2079-3200/11/11/210
Perry, A. (2023). AI will never convey the essence of human empathy. Nature Human Behaviour, 7(11), 1808–1809. https://doi.org/10.1038/s41562-023-01675-w
Schlegel, K., & Mortillaro, M. (2019). The Geneva Emotional Competence Test (GECo): An ability measure of workplace emotional intelligence. Journal of Applied Psychology, 104(4), 559.
Simpson, J. A., Kim, J. S., Fillo, J., Ickes, W., Rholes, W. S., Oriña, M. M., & Winterheld, H. A. (2011). Attachment and the Management of Empathic Accuracy in Relationship-Threatening Situations. Personality and Social Psychology Bulletin, 37(2), 242–254. https://doi.org/10.1177/0146167210394368
Images for this post were created with napkin.ai and Gemini.
Follow the Topic
-
Communications Psychology
An open-access journal from Nature Portfolio publishing high-quality research, reviews and commentary. The scope of the journal includes all of the psychological sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Replication and generalization
Publishing Model: Open Access
Deadline: Dec 31, 2026
Comparative Psychology of Cognition, Affect, and Behaviour
Publishing Model: Open Access
Deadline: Oct 31, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in