Empowering Discovery with ARGOS: Using Algorithms to Automate the Unveiling of Complex Systems' Governing Laws
Published in Computational Sciences, Mathematical & Computational Engineering Applications, and Statistics
Imagine deciphering planetary motion without understanding gravity. That was first accomplished by Johannes Kepler, who formulated his laws of planetary motion in the early 17th century. His laws accurately described planetary motion, but the concept of gravity as the driving force was not fully understood until Isaac Newton's work later in the same century. Just as Newton built upon Kepler to reveal the laws of gravity that govern planetary motion, modern scientists rely on the discovery of differential equations from data when they attempt to understand complex systems, from the human brain to climate patterns, without knowing the underlying mathematical models.
Creating these models, however, is a complex task that often requires substantial input from experts in the respective fields. In today's world, where data is plentiful, the challenge is not just in developing these models but also in automating this process. Our paper, "Automatically discovering ordinary differential equations from data with sparse regression", showcases an innovative approach to this challenge, promising to accelerate our understanding of complex systems through the lens of data-driven discovery.
The Challenge of System Identification
At the heart of our exploration is the process of developing mathematical models in the form of differential equations that accurately represent the dynamics of a system from observed data. Traditionally, this task required a blend of deep subject matter expertise and painstaking manual efforts to align mathematical equations with observed behaviors.
In recent years, the field has been revolutionized by the introduction of sparse regression techniques. Sparse regression employs regularization methods in linear regression to impose sparsity in the estimated coefficients, effectively reducing model complexity by selecting only a subset of the most informative predictors for inclusion in the final model. These methods help us sift through the vast array of possible mathematical expressions to identify those few that truly capture the essence of the system under study. It is like having a sophisticated filter that separates the true from the spurious terms, allowing scientists to pinpoint the underlying structure of complex dynamics with unprecedented efficiency.
The Sparse Identification of Nonlinear Dynamics (SINDy) approach is a notable breakthrough in this area. SINDy uses a sparsity-promoting framework to extract the most significant terms from a complex, high-dimensional space of nonlinear functions, thereby unveiling readily understandable models from the data. Despite these advancements, SINDy requires a trial-and-error approach to adjust its hyperparameters, and its success can hinge on having prior insight into the system's governing equations—a significant hurdle when exploring uncharted territories.
Our work builds on and extends beyond the capabilities of SINDy, aiming to automate the discovery of dynamical laws with minimal human intervention.
Limitations of SINDy
Hyperparameters significantly influence SINDy's effectiveness. The algorithm reduces noise and differentiates data using the Savitzky-Golay filter, but this requires expert-driven manual selection of filter parameters, a process that is both labor-intensive and reliant on expert knowledge. Similarly, the sparsity-promoting hyperparameter in the optimization problem plays a pivotal role in striking a balance between model intricacy and fidelity to data. Proper calibration of this hyperparameter is crucial for balancing model complexity and accurately capturing system dynamics. Manual adjustment of this hyperparameter, usually via trial and error, remains a standard practice.
The Sequentially Threshold Least Squares (STLS) algorithm, at the heart of SINDy, is characterized by its nonconvex nature, rendering it suboptimal for extensive, high-dimensional datasets. Attempts to mitigate this through the adoption of ridge regression, in lieu of STLS, have only partially addressed the issue. While ridge regression penalizes irrelevant terms, it lacks the ability to select variables outright, necessitating a threshold at each iterative step. Consequently, the challenges of nonconvexity and manual hyperparameter tuning persist, even with Ridge Regression.
SINDy's extension through the Akaike Information Criterion (AIC) introduces an automated model selection strategy, employing a grid of sparsity thresholds alongside AIC to pinpoint the model that best captures a system's dynamics. However, this approach is hampered by its dependency on comparing predicted and idealized system states—a comparison that is often infeasible in real-world scenarios where we observe data, but the true system is inaccessible. Additionally, the model selection mechanism, which enumerates possible prediction models, becomes increasingly burdensome with higher-dimensional data, compromising efficiency. Our methodology demonstrates superior efficiency, especially in identifying Lorenz dynamics as data size escalates. Notably, SINDy with AIC's effectiveness has been validated under narrowly defined conditions—specific initial conditions, adequate observations, and minimal noise—highlighting the necessity for broader, more rigorous evaluations to ascertain its performance across varied contexts.
Introducing ARGOS

Named after the mythological Greek giant famed for his ability to see and observe everything, ARGOS is a methodology designed to address the limitations of SINDy.
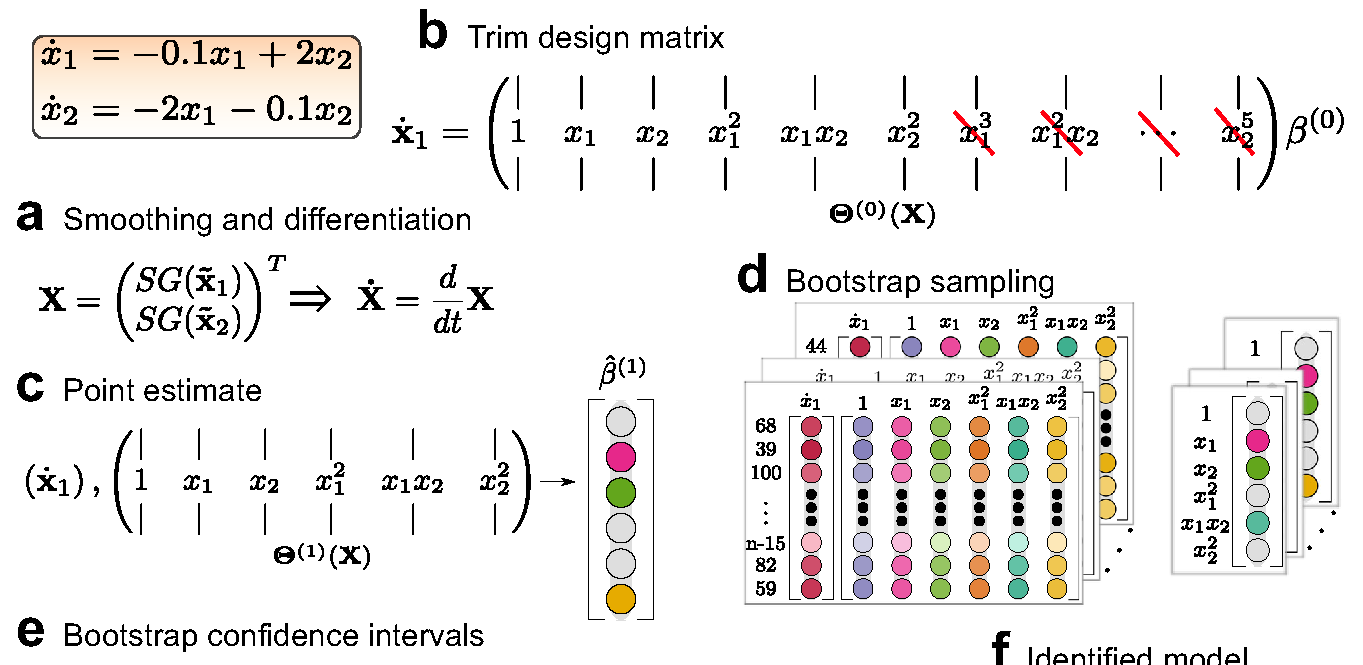
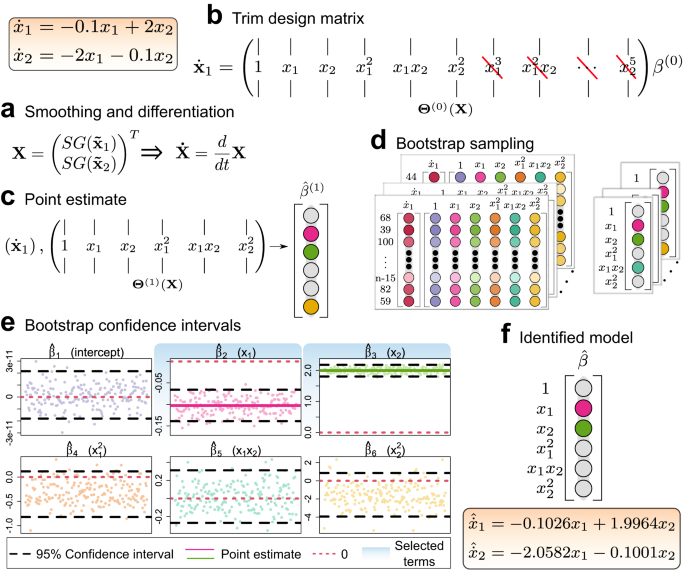
ARGOS begins with a modern twist on a classic technique: the Savitzky-Golay filter. This step is crucial, as it allows the algorithm to focus on the essence of the system's dynamics, stripping away the noise and highlighting the signal. Unlike its predecessors, ARGOS adds a layer of automation to this process, adjusting its parameters to fit the data at hand, saving scientists from the tedious task of manual tuning.
After preparing the data, ARGOS uses the lasso and adaptive lasso algorithms to select the key variables describing the system dynamics. Consider the example of analyzing plant growth, where factors like sunlight, water, soil type, and many others may influence the outcome. The lasso algorithm simplifies this process by pinpointing the key variables. The adaptive lasso is an extension of the lasso that applies a unique weighting system that emphasizes the most impactful factors while accounting for the presence of collinearity.
Finally, ARGOS uses bootstrap sampling to measure the reliability of its findings. This statistical technique involves repeatedly sampling from our data, with each sample used to estimate a model. By looking at how these models vary, ARGOS can give us a confidence interval for each variable it identifies as important. Through this process, ARGOS further selects variables associated with nonzero coefficients.
ARGOS - Balancing Strengths and Limitations

One of the key strengths of ARGOS is its ability to consistently identify three-dimensional systems, given moderately sized time series and high levels of signal quality relative to background noise. This capability is especially important since many of the phenomena we seek to comprehend and forecast, from atmospheric dynamics to biological processes, occur within three-dimensional space. ARGOS opens new avenues for scientific discovery and innovation by effectively capturing these systems' essence.
Linear regression, a widely used statistical method, assumes that the variance of errors is constant across all levels of the independent variables, an assumption referred to as homoscedasticity. Violations of this assumption can significantly affect the accuracy of a model. In our exploration, particularly when analyzing the Lorenz system without noise, this assumption of constant variance did not hold, leading to inaccuracies in the model. The presence of non-constant variance in the model's residuals—differences between observed and predicted values—pointed to this issue. Interestingly, introducing a slight amount of noise into the system helped mitigate this problem, making ARGOS more adept at identifying the true dynamics.
Outlook
Our paper provides a new tool for researchers to identify the underlying dynamical systems that govern various phenomena, which is particularly useful when the true system dynamics are complex and not easily discernible (ARGOS is available as an R package on CRAN, with the source code also available on GitHub).
The success of the method in identifying three-dimensional systems suggests that it could be extended to even higher-dimensional systems. As we continue to refine and expand its capabilities, we extend an invitation to researchers and scientists from every scientific domain to harness the power of ARGOS in their investigations. Together, we stand on the brink of a new era, poised to propel scientific progress through the automation of science, revolutionizing our approach to discovery and understanding.
Follow the Topic
-
Communications Physics
An open access journal from Nature Portfolio publishing high-quality research, reviews and commentary in all areas of the physical sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Advances in Quantum Networking: QKD and beyond
Publishing Model: Open Access
Deadline: Jul 31, 2026
Nonlinear dynamics of living systems
Publishing Model: Open Access
Deadline: Nov 09, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in