Model-Based Inference of the Past Guides Model-Free Credit Assignment
Published in Social Sciences

About two years ago I started my post-doc at the MPC UCL Centre for computational psychiatry and ageing research in London and I became interested in a fascinating multi-disciplinary topic called reinforcement learning (RL). Research in RL addresses the different ways in which organisms adapt to environments wherein actions provide rewards and/or punishments. My main interest is to understand how individuals learn to adapt behavior efficiently in such environments.
One influential theory suggests that such behavioral adaptation relies on separate contributions from two systems or processes. The first, a so-called model-free system, simply registers how rewarding (or punishing) each action has been in the past. Accordingly, individuals learn by trial and error which actions are more and which are less rewarding and, when faced with a decision situation, an individual tends to choose from the most successful past actions (not taking into account whether the conditions that made the action successful in the past still prevail). The second, named a model-based system, maintains an elaborate model of the world which represents information about the consequences of one’s actions and how these consequences are associated with rewards. This allows an individual to simulate the outcomes of alternative actions and to identify good action-plans.
How do the separate system contributions combine to determine one’s behavior? Often the situation is relatively simple because the systems agree on their action-recommendations. But sometimes they conflict! Imagine, for example, that you are driving home after work, when you hear in a traffic report that the road which you usually take is blocked (due to an accident). When you reach the turn to that road, your model-free system will still advice in favor of taking it, because this action was successful in the past. This system can’t incorporate the road-blockage information in its calculations because its evaluation are affected by past rewards alone. Your model-based system, on the other hand, will realize that this action is currently futile. It can thus design an alternative, more efficient, plan. In such conflict situations the two system will compete over which system dictates your action.

Dual-system RL theories, therefore, stress a temporal orientation distinction between the two systems. Whereas the model-free system is retrospective in that its (action) value estimates are rooted in the past, the model-based system is prospective, caring only about future outcome consequences. This division puzzled me quite a bit. It occurred to me that in both scientific research and real life, we rely on our theories and models not only to prospectively predict and plan the future, but also to retrospectively explain, interpret and infer the past. This principle underlies a myriad of phenomena such as the study of History, psycho-dynamic therapy and any attempt to understand why a friend behaved unkindly to us. Guided by this intuition, Mehdi Keramati, Peter Dayan, Ray Dolan and yours truly (@moran_rani) set out to demonstrate that retrospective model-based inference plays an important role in reinforcement learning.
The first challenge that we faced was identifying under which conditions it could be helpful to use a model to infer one’s past. We hypothesized that retrospective inference is instrumental in choice situations which entail state uncertainty. In many real-life situations the “state of the environment” is not fully known in the sense that one doesn’t have full access to information that could in principle affect one’s choice of actions. In such cases, if an action is rewarded, an individual has uncertainty with respect to when (i.e., in which states) exactly the action is beneficial. In other words, the individual does not know the state to which the credit that was earned from the action should be assigned. This limits the usefulness of the information that this action was rewarding for making future choices. Sometimes, however, the individual receives later information that allows it to retrospectively infer the state of the world that was operative when the action was taken. This inference can direct credit-assignment toward the relevant state.
To illustrate, imagine that you are asking a work-colleague for help with some mundane task. Your life experiences taught you that people differ in their tendency to provide help as a function of their mood (whereas some people tend to provide help when they are in a good mood, others tend to provide help when they are in a bad mood; Assume your colleague belongs to the latter type). Suppose, however, that currently you are aware of neither your colleague’s tendencies nor of her current mood. When the colleague agrees to provide help, your model-free system is unsure (so to speak) whether it should reinforce the “ask for help” action in the “good colleague mood” or the “bad colleague mood” state. In this case, it will learn that it is beneficial to ask for help disregarding the colleague’s mood. Clearly, this learned knowledge is not very accurate because your colleague doesn’t tend to provide help when she is in a good mood. Suppose, however, that you later learn that on the very same morning the colleague’s son was involved in a minor car accident. Relying on your model of mood, you can infer that your colleague was probably in a bad mood when she helped you. Consequently, you can reinforce the “ask for help” action specifically when the colleague is in a bad mood. The upshot is that by resolving uncertainty about the past, we can refine and improve the fidelity of our credit assignment processes.
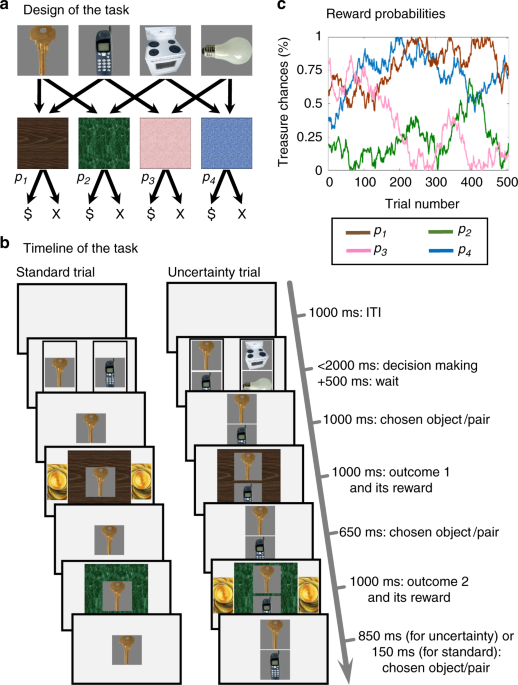
In our research, we examined this hypothesis by designing a task in which people had to repeatedly choose between different pictures. Each chosen picture opened a unique sequence of rooms in a treasure-castle (associated with that picture) and each room contained a reward with a certain probability. Over time, participants learned which pictures where more and less likely to provide rewards. Notably, our task allowed us to quantify separate contributions of the model-free and model-based systems to choices. Occasionally, participants chose a pair of pictures, rather than a single picture. In such cases they were told that only one of the pictures in their chosen pair will be executed i.e., open its associated sequence of rooms. The choice of which picture was executed was random and not revealed to participants and hence, participants experienced state uncertainty (which picture is executed?). Importantly, however, based on the sequence of rooms that were opened, participants could use their model of the task structure (which represented information about which rooms are opened by different pictures) to retrospectively infer which of the two pictures in their chosen pair was executed. Interestingly, and in support of our hypothesis, we found that people relied on their task model to infer which of the two pictures was executed. Furthermore, this inference allowed their model-free systems to assign credit (from the earned rewards) preferentially to the inferred picture. I invite you to read our paper for further details.

I am quite excited about these results. I think that they broaden our understanding of the functions served by the two reinforcement learning system. First, the findings show that the model-based system is not only a future-oriented planning system but it also engages in making sense of one’s past. Second, they show that the model-free and model-based systems are not necessarily competitive but rather, they can cooperate under conditions of state-uncertainty. Indeed, we could demonstrate that the model-based system can resolve past uncertainty to guide model-free credit assignment.
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in