Optimal tracking strategies in a turbulent flow
Published in Physics
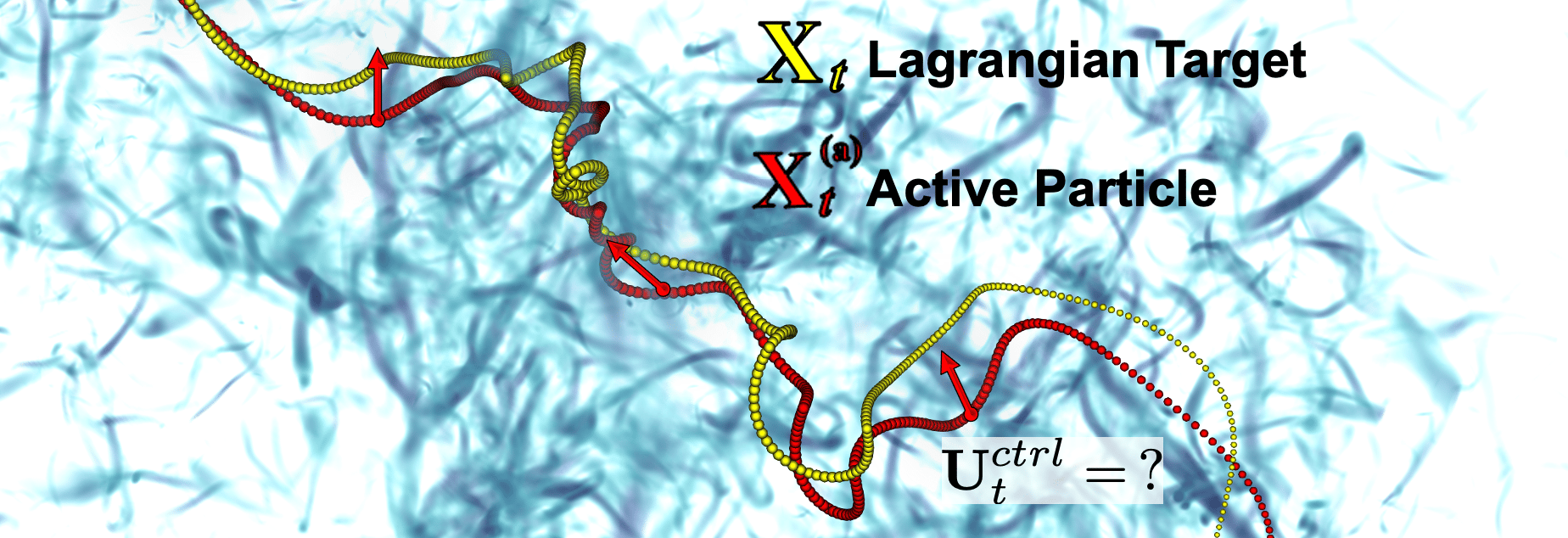

Finding optimal navigation strategies for active agents in a complex fluid environment is a notoriously difficult problem with applications ranging from environmental monitoring to micro-medicine.
Aside from flying vehicles such as airplanes or drones, which have full control on their trajectory, recent research has focused on optimizing point-to-point path planning also for slow-moving objects, micro-swimmers and active particles [1-4]. These objects have only limited maneuverability, hence the need to optimize their small active control. Indeed, these slow objects tend to be carried away by the flow and need to appropriately exploit it in order to reach their destination.
A Dynamic Target
In our paper, we address the problem of optimizing active particle trajectories, applying control theory [5,6]. However, the active particle destination is not a fixed point in space but an ever-moving object, a "Lagrangian Target" transported by the turbulent flow itself [7,8] (as depicted in Figure 1). In typical set-ups, the relative distance between two passive drifters would always grow due to Lagrangian chaos. Here, only the target is passively advected, while the active one must learn how to exploit and explore the flow in order to tame the chaoticity of the system. In particular, our active agent must harness local flow structures, avoiding regions of strong fluctuations, and exploiting the long-time correlations typical of turbulence. This problem is also relevant to many real-world applications, such as keeping in a pattern formation a swarm of oceanic drifters [9] and floaters (see Figure 1); interpreting strategies to catch non-swimming preys by micro-swimmers in turbulent environment; developing autonomous self-propelling protocols for mini-robots navigating in complex bio-flows or for gliders in the atmosphere or ocean.
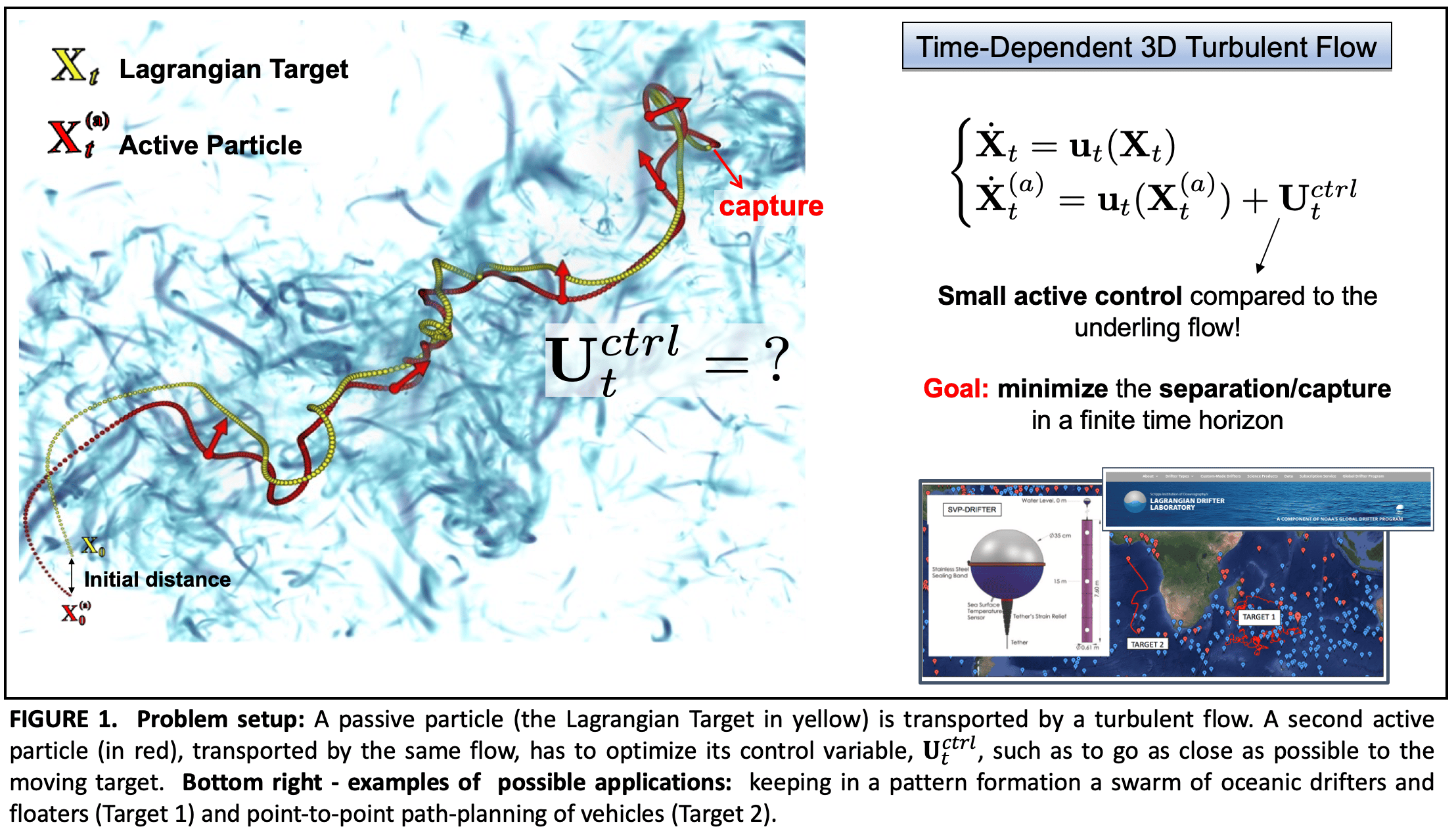
Q: How to define a suitable optimization criterion to reach the Lagrangian Target trajectory (capture) in a minimum time?
Control Theory
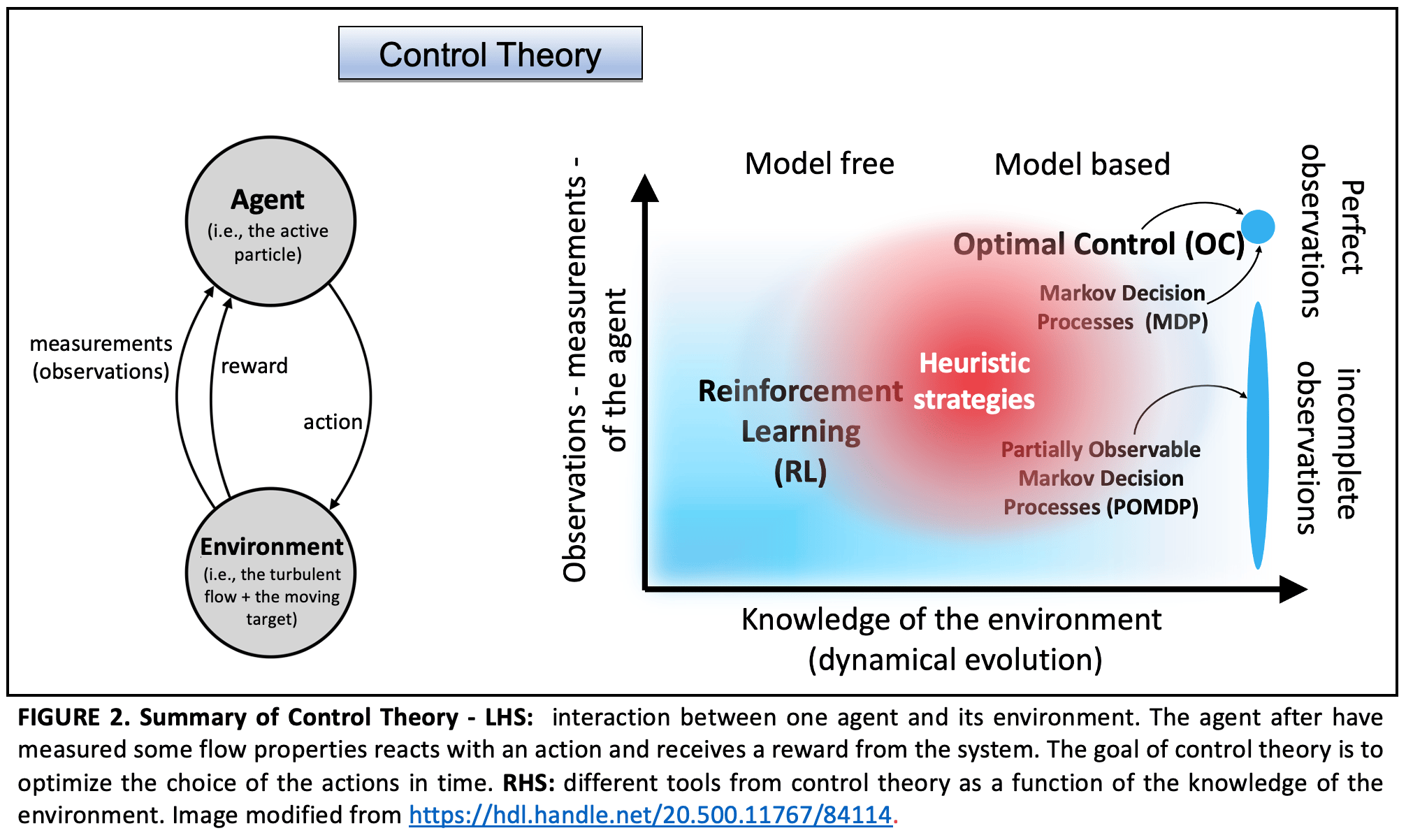
Control theory is a field of study focused on regulating the behavior of systems. It includes various approaches, from model-free to model-based methods. While the first are based on data-driven techniques (e.g., Reinforcement Learning) and are suitable for complex, real-world systems, the latter leverage mathematical models to achieve precise and efficient control. The choice between these approaches depends on the specific application and the available knowledge about the system being controlled (see Figure 2).
In our paper we focused on the model-based tools, finding the perfect path to catch a constantly moving target in the shortest possible time. In this case we need to know everything about the environment, like the gradients of the flow and the target positions at every time. But we also explored a different approach, using heuristic/reactive strategies. These are like quick decisions based on what's happening right now in the environment, without knowing the whole history. Thus, these approaches are obtained through some local approximation of the real system dynamics (i.e., neither model free nor model based).
Tracking Lagrangian targets
When we had full knowledge of the environment, our optimal control strategies were highly effective in taming the chaos and capturing the target. Moreover, our optimally controlled trajectories turned out to be stable and robust to perturbations in the initial position of the Lagrangian pair, which is a priori unexpected. In other words, even if we shifted the initial conditions of the Lagrangian pair a bit, our control still worked, bringing the pursuer closer and closer to the moving target. In terms of dynamical systems theory, we can say that the target trajectory becomes an attractor for the controlled dynamics.
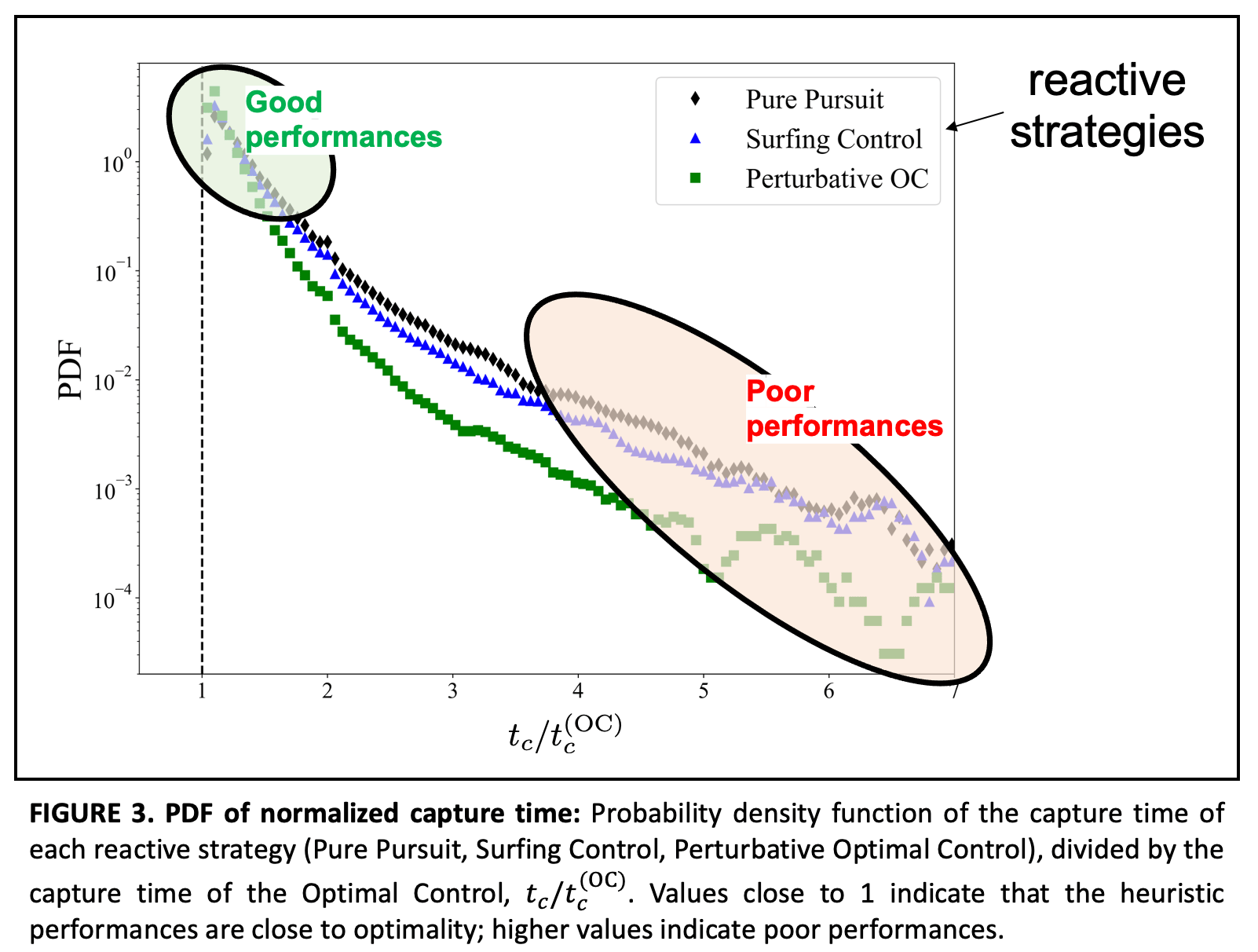
When we turned to reactive approaches, the reliability of our solutions became less clear. At times, the heuristic strategies proved to be effective and remarkably close to the optimal solution, which is quite extraordinary considering that they rely solely on local information, unlike the optimal approach which requires a complete knowledge of the flow. However, there were cases where the heuristic strategies fell short. This is more quantified in Figure 3. The effectiveness of reactive approaches depended entirely on the characteristics of the underlying flow and how quickly the target trajectory diverged from that of the active particle. In practical scenarios, it is clear that success will require the development of more sophisticated control strategies beyond reactive methods.
One interesting avenue is to explore heuristic strategies that incorporate temporal and/or non-local information. This opens up exciting possibilities for improving control in real-world situations where responding to local cues may not be enough.
In the future, it will be important to see how these strategies work with increasing turbulence strength, and we're thinking about applying them to tiny things like micro-swimmers so that we can include hydrodynamic interaction effects. We're also looking at ways to deal with measurement errors that occur along the whole trajectory.
For more details, please read our paper !
References
[1] Biferale, Bonaccorso, Buzzicotti, Clark Di Leoni & Gustavsson. Chaos: An Interdisciplinary Journal of Nonlinear Science. 2019 Oct 24;29(10):103138. Zermelo’s problem: Optimal point to-point navigation in 2D turbulent flows using reinforcement learning.
[2] Colabrese, Gustavsson, Celani, Biferale. Phys. Rev. Letters 118 (15), 158004, (2017). Flow navigation by smart microswimmers via reinforcement learning.
[3] Colabrese, Gustavsson, Celani, Biferale. Phys. Rev. Fluids 3, 084301, (2018). Smart Inertial Particles.
[4] Borra, Biferale, Cencini & Celani. Phys. Rev. Fluids 7, 023103 (2022). Reinforcement learning for pursuit and evasion of microswimmers at low Reynolds number.
[5] Bryson, A. E. and Ho, Y. Applied optimal control: optimization, estimation and control (New York: Routledge, 1975).
[6] Sutton, R. S., & Barto, A. G. Reinforcement learning: An introduction. MIT press (2018).
[7] Calascibetta, Biferale, Borra, Celani & Cencini. Eur. Phys. J. E 46, 9 (2023). Taming Lagrangian Chaos with multi-objective reinforcement learning.
[8] Biferale, Bonaccorso, Buzzicotti & Calascibetta. (2023). TURB-Lagr. A database of 3d Lagrangian trajectories in homogeneous and isotropic turbulence.(arXiv:2303.08662)
[9] http://gdp.ucsd.edu/ldl_drifter/index.html

This work was supported by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (Grant Agreement No.882340).
Follow the Topic
-
Communications Physics
An open access journal from Nature Portfolio publishing high-quality research, reviews and commentary in all areas of the physical sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Nonlinear dynamics of living systems
Publishing Model: Open Access
Deadline: Nov 09, 2026
High-Energy Light Sources - From Tabletop to Large Facilities
Publishing Model: Open Access
Deadline: Sep 30, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in