Sharing Primate Phenotypes
Published in Ecology & Evolution, Protocols & Methods, and Anatomy & Physiology
Timeline
2010
Sergio starts his postdoc at the AMNH. He is there to scan primate wrist bones to compare them with the fossil apes from Spain.
"Why are you scanning all the skulls? And the long bones, too?" - Sergio's colleague, visiting from Spain
"Well, I'm here. And this skeleton is so nice. I think I'll make my own little virtual museum." - Sergio
2013
"Hey Sergio, how are you doing? Would you mind sending me all your capitates? Left if possible. It's for a good cause, you'll see. " - Team cheiridia member (aka Sergio's colleague working primate hands and feet)
2015
Dr. Santiago Catalano visits Sergio at Stony Brook University (second postdoc) to request primate morphometric data to try some "new things." Somehow, Sergio decides they need to collect more data from more species and more anatomical parts to work on bigger questions.
Later that year, Sergio starts a new job at The George Washington University (assistant professor). With the help of students, he enlists all his resources to digitize as much as possible from the nearby Smithsonian collections (NMNH).
2016
"Dear Professor Almécija,
I'm a PhD student at Dr. Warrior's lab. I follow your research with much interest, and I would appreciate it if you could share all [emphasis added] your hand bone scans. I can mail you a hard drive, or I can potentially stop by your lab during my upcoming trip to DC." - Student request #7
"Please understand that the data you are requesting is part of my ongoing research and that of my students. Stop by the lab, perhaps we can arrange a collaboration." - Sergio
2020
"I'm a student from Italy trying to gather enough data to finish my dissertation on the evolution of the human hip. I can't travel, and most collections are closed for visitors, anyway. Would you be willing to share your scans?" - Student request #29
"Sure, I put a copy of all my foot scans in a Dropbox folder. See the link below. Please reach out as your studies move on to publication so we can share a little blurb regarding our funding sources with you to add your acknowledgments.
Best wishes with your project!" - Sergio
REPEAT THE ABOVE EVERY OTHER WEEK
Upon returning to the office, Sergio coordinates with his lab members (including students, postdocs, and volunteers) to start uploading all their scans, amassed over a decade of international data collection, into MorphoSource, originally under "restricted download," to facilitate showing and sharing our data on a one-by-one basis.
2021
"I'm a student working on the functional morphology of primate chewing, and I'm compiling a dataset of skull 3D scans. Browsing through MorphoSource, I found this scan that will be crucial for my dissertation." - Student request #103 (the student has marked over 100 scans for download)
Sergio ensembles "The Team," formed by other primate morphologists (of all career levels) and representatives of each natural collection involved. The mission: finish organizing and uploading all their non-human primate 3D data housed in their servers to MorphoSource and make the proper arrangements to make them openly available.
Of course, I'm just paraphrasing. The quotes above are not literal, but you get the idea.
10,000
To give you some perspective regarding the working time that it took to make this project possible:
- Every scan takes ~30-60 minutes to digitize once you know how to do it right.
- Every scan takes ~5-60 minutes to post-process (e.g., clean) before it can be used. For example, a small, simple bone like a phalanx takes little. A cranium can take hours.
- Uploading every scan to MorphoSource takes from ~5 minutes for a simple 3D mesh to potentially hours for each stack of CT scans (it requires extra data processing, such as zipping folders with thousands of images).
So, being conservative and simplifying, creating and sharing this massive phenotypic dataset took The Team ~10,000 working hours.*
To put this effort into context, imagine a straight ~14-month shift working 24/7, and this is discounting the multiple trips to national (US: AMNH, NMNH, CMNH, Stony Brook University) and international (Belgium: RMCA) museum collections to curate and digitize the specimens, writing the grants to cover the expenses, etc.
For further context, have you ever heard of the "10,000 hour rule" popularized by Malcolm Gladwell? Basically, it's the estimated time of focused work that it takes to create a Bill Gates from scratch, or the Beatles, or Beethoven.
Paper
Reviewer #2 was pretty much what you can expect from Reviewer #2 (you know what I'm talking about). What strikes me most is that #2 fought to the dead to ensure this paper didn't see the daylight. However, there didn't seem to be any problem with the data being available through MorphoSource. In other words, #2 wanted the data described in the paper but didn't want to have to cite the paper that described the project...
Why was it important to publish this descriptive paper? First, we wanted to provide a place where possible users could learn about the dataset and how they could use it. A place that researchers, granting agencies, and journal articles could point out every time they used the data (#2 didn't like this). But it was not just about due recognition to all the parties involved—researchers, students, curators, and collection managers involved, many of which also coauthored the paper. It was also about providing the proper background about the data compiled in this particular project (methods, quality, comparability, etc.), and how the intricacies of digital data curation work in MorhphoSource.
In addition, I must say that this 3D dataset of primate skeletons includes some cool specimens, especially apes. For example, it features a female bonobo (AMNH-M 86857; Pan paniscus) that constitutes the smallest documented adult individual known of this species from the wild. It also features the holotype of Grauer's gorilla (RMCA 8187; Gorilla beringei graueri, or Eastern lowland gorilla), as well as another gorilla (AMNH-M 202932) that we believe is the very same collected by Henry C. Raven in 1929 near Lake Kivu as a part of the Columbia University-AMNH expedition. This specimen was later pivotal in Raven’s landmark monograph on gorilla anatomy.
Worth it
Of course, it was all worth it. Thanks to MorphoSource working collaboratively with natural history collections, many of their specimens now have digital counterparts from which morphological data can be easily retrieved from any corner of the planet with a computer and internet access. In addition, each collection can manage and track the use of these data at any time. In addition, the collections can keep updating their records with more and more specimen metadata as it becomes available from old records, and time allows it. In addition, working with digital specimens will help reduce the ware of invaluable physical specimens. And, thanks to the descriptor paper, all of the critical information surrounding some key elements of the dataset will not be lost.
Of course, this project and accompanying paper didn't occur in a vacuum. They were inspired by the works of similarly minded folks (e.g., Copes et al., 2016; Bjarnason & Benson, 2021; Blackburn et al., 2024). Years ago, I was a little sick. The affection is called data hoarding. It affects young researchers very commonly. It's only normal. Collecting the data for one's dissertation can take the life out of you. New researchers need to protect this beloved resource and use it to produce a body of work (many via collaborations) that will, hopefully, secure them a job. Totally understandable. But...one day, you let go. One day you will realize that, counterintuitive as it sounds, the more you give, the more you get. By the way, no one ever said "thank you" to me before for any other project or paper that I worked on. It feels good.
I can see that as more people share what they most protect, more opportunities will emerge, and they'll be freer to do what matters. And what's more important than contributing something new to the world?
Ps.
2019
Graduate student Sergio Almécija, against all odds, convinces PhD advisor (Salvador Moyà-Solà) to purchase a unit of the revolutionary, inexpensive, portable, wonderful NextEngine surface laser scanner.**
"You won't regret it. With one of these, I can travel the world and build our own virtual collection from which to collect data FOREVER."
*Simplified math: 6,000 scans * 100 minutes [digitizing + processing + uploading to MS] = 600,000 minutes, or 10,000 hours.
**NextEngine, Inc., seems to have ceased operations around 2021 due to its relatively outdated technology. RIP.
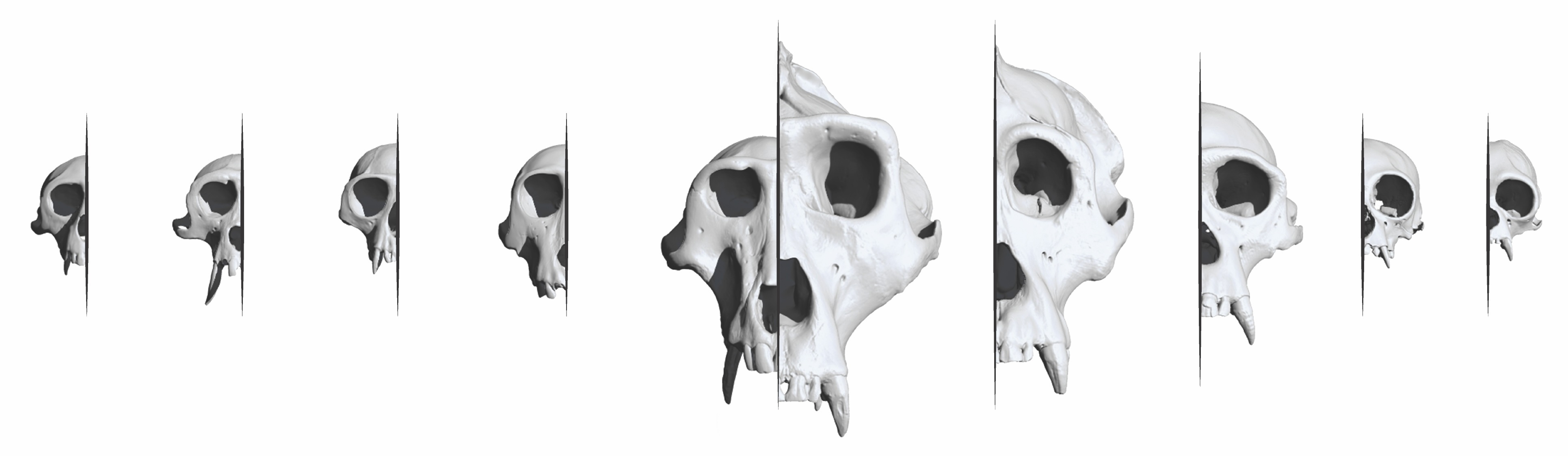
The banner image in this article represents crania of the following species (from left to right): Chlorocebus sabaeus, Macaca fascicularis, Colobus guereza, Mandrillus sphinx, Papio hamadryas, Gorilla gorilla, Pongo pygmaeus, Pan troglodytes, Symphalangus syndactylus, and Hylobates klossii. Together with the logo accompanying the MorphoSource project, they were created by researcher, artist, colleague, and paper coauthor Christopher M. Smith.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Oct 10, 2026
Wearable and Computer Vision Data for Health and Behaviour Research
Publishing Model: Open Access
Deadline: Aug 08, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in