Wall + Camera + Computation = Mirror?
Published in Electrical & Electronic Engineering


Mirrors and matte walls are quite different. When light reaches a mirror, it reflects at a single angle specified by the law of reflection; when light reaches a matte wall, it is scattered in all directions. Thus, to use a matte wall as if it were a mirror requires some mechanism for regaining the one-to-one spatial correspondences lost from the scattering. No optical technique can undo scattering, but computational imaging can approximately separate (or unmix) the light that travels different paths to a detector. In essence, computation can turn a matte wall into a mirror.
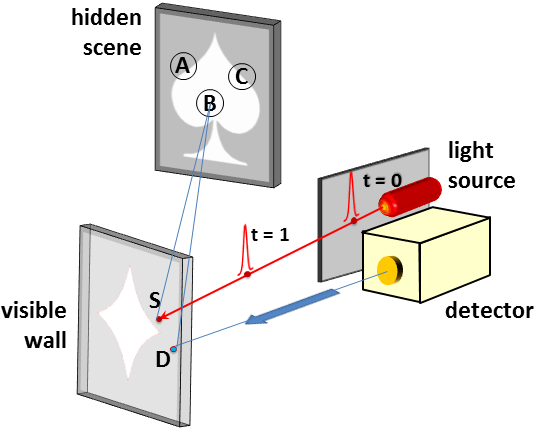

Our method is based on modeling that is perhaps simpler and equipment that is definitely cheaper. Instead of requiring time of flight to separate light paths, we rely on the existence of an opaque occluding object in the scene. When we fix a camera field-of-view (FOV) (a portion of the visible wall), wherever the occluder happens to be, there will be a portion of the hidden scene with the property that it is blocked from some part of the camera FOV and not blocked from some other part of the camera FOV. We define this portion of the hidden scene as the computational FOV, as shown to the left. We can compute an image of the computational FOV because of the separation of light paths created by the occluder. Restating this from the perspective of the hidden scene, light from the computational FOV neither reaches the whole camera FOV nor is blocked from the whole camera FOV. Therefore, the occluder and light from the computational FOV create a penumbra—a pattern of partial shading as in the image below—in the measured camera image. As detailed in the paper, the solution of a linear inverse problem maps the camera measurement to an image of the computational FOV.
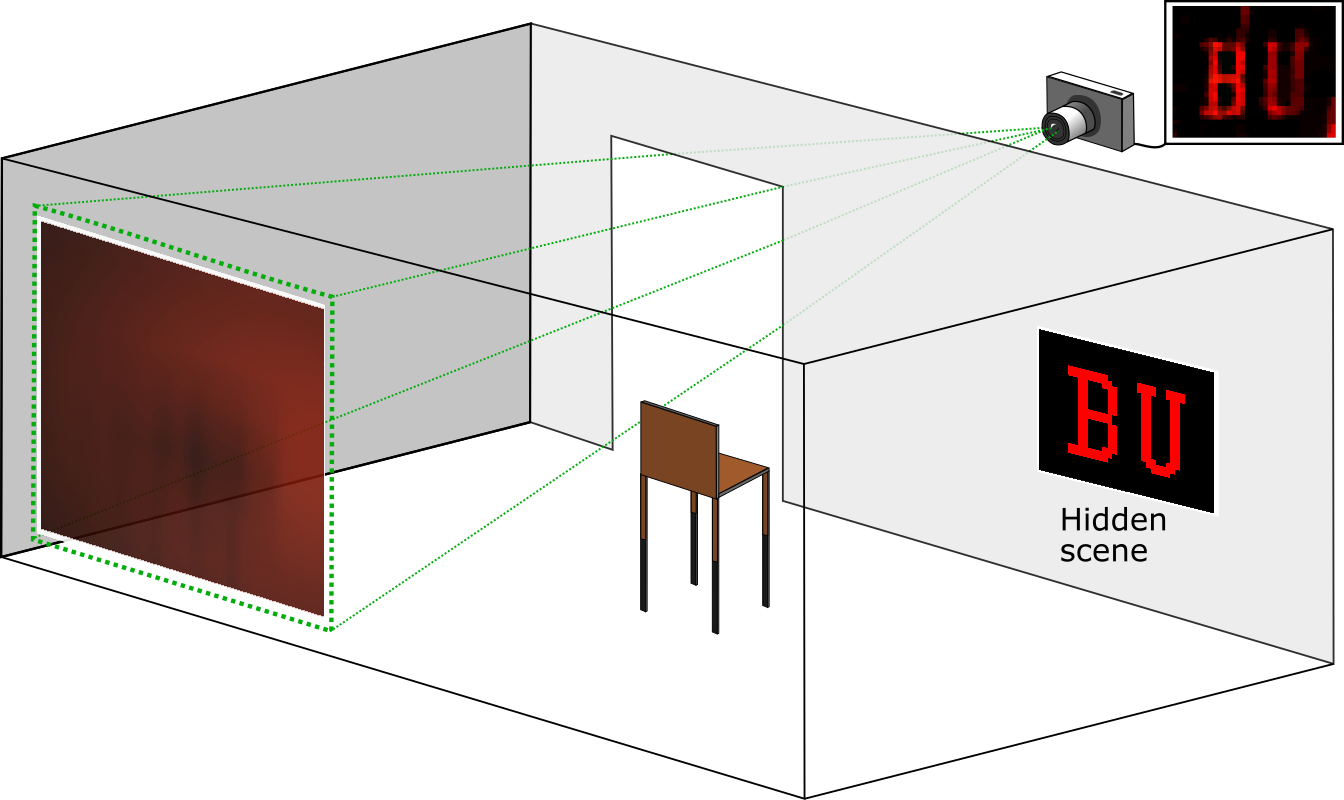
Penumbrae are often very weak and appear to be nothing but blurry messes. Our work certainly makes me look at them differently, always wondering how much could possibly be inferred.
The ideas behind this work with Charles Saunders and John Murray-Bruce from my group at Boston University were not generated in a vacuum. We have been working on NLOS imaging as part of a DARPA-funded team with several co-PIs at the Massachusetts Institute of Technology: Fredo Durand, Bill Freeman, Jeffrey Shapiro, Antonio Torralba, Franco Wong, and Greg Wornell. Torralba and Freeman have, in particular, exploited occlusions to produce “accidental cameras” in earlier work.
Follow the Topic
-
Nature
A weekly international journal publishing the finest peer-reviewed research in all fields of science and technology on the basis of its originality, importance, interdisciplinary interest, timeliness, accessibility, elegance and surprising conclusions.

Related Collections
With Collections, you can get published faster and increase your visibility.
Carbon Dioxide Removal
Publishing Model: Hybrid
Deadline: Jan 16, 2027


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in