A high-quality dataset featuring classifed and annotated cervical spine X-ray atlas
Published in Computational Sciences
Background and Summary
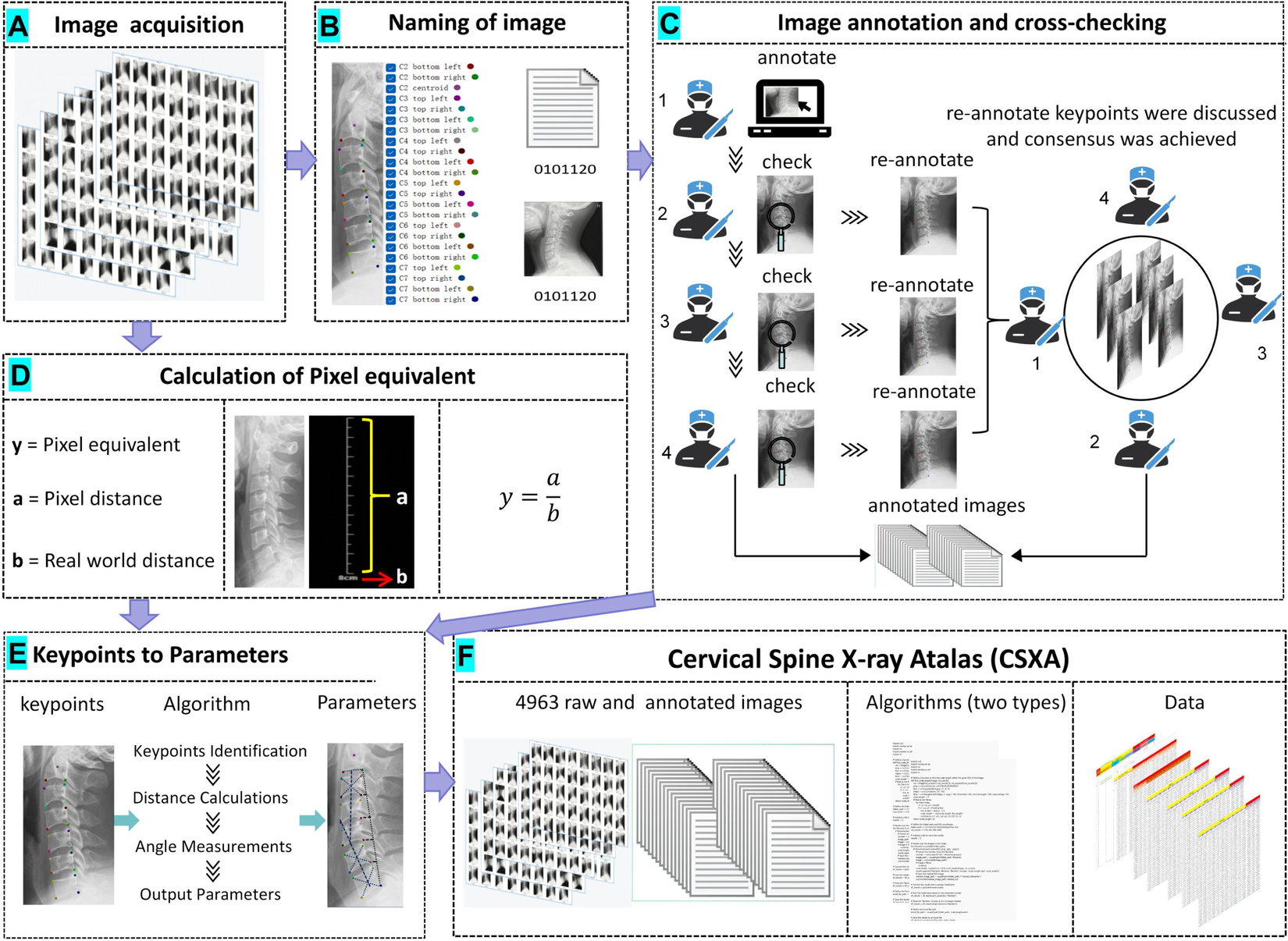
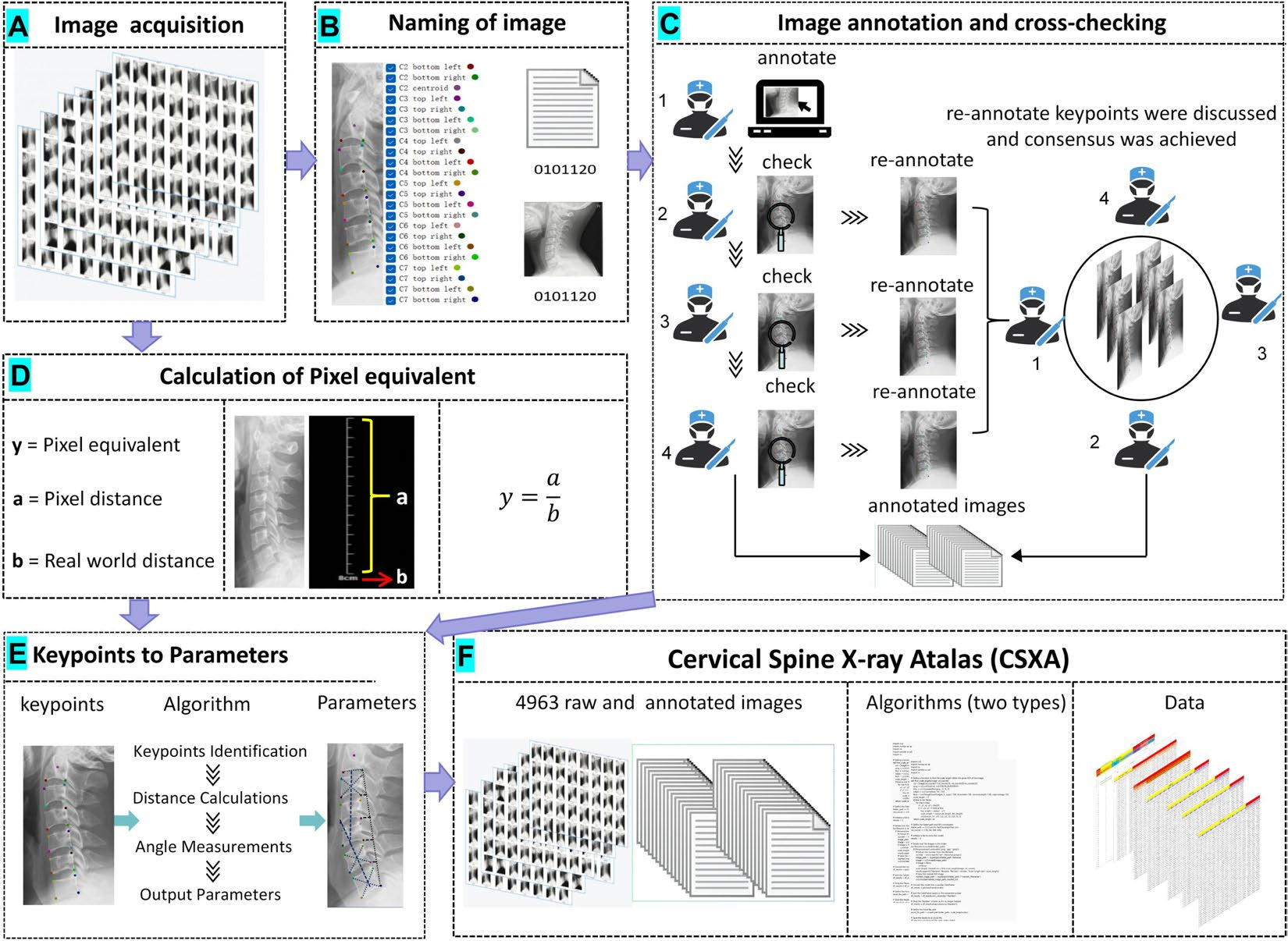
Recent research in computational imaging largely focuses on developing machine learning (ML) techniques for image recognition in the medical field, which requires large-scale and high-quality training datasets consisting of raw images and annotated images. However, such datasets for cervical spine X-rays are notably scarce. To fill the gap, we have developed the Cervical Spine X-ray Atlas (CSXA), an open-access dataset containing 4963 raw PNG images and an equal number of annotated images in JSON format. Each image is meticulously annotated with details including gender, age, pixel equivalent, and classifications for symptomatic and asymptomatic cases, as well as cervical curvature categorization and 118 quantitative parameters.
Research Methods and Behind-the-Scenes Image Collection and Annotation Process
The raw images were collected from multiple sources, including routine clinical visits and health checkups at Dongzhimen Hospital, Beijing University of Chinese Medicine. Image annotation was a collaborative effort involving four orthopedic spine surgeons, each with an average of six years of experience. The process involved three rounds of cross-checking to ensure accuracy and consistency. Keypoints for annotation included critical anatomical landmarks such as the corners of the vertebral bodies and the centroids of each vertebra. These points were selected based on their importance in diagnosing and assessing cervical spine diseases.
Algorithm Development
An advanced algorithm was developed to convert 23 keypoints from the annotated images into 77 quantitative parameters. These parameters are essential for diagnosing and treating cervical spine diseases. The algorithm uses Python scripts to compute the pixel equivalent for each image, ensuring that the quantitative measurements are accurate and reliable.
Data Validation and Quality Assurance
The annotated data underwent rigorous validation, including manual measurements and cross-checks to ensure consistency. The pixel equivalent were verified using ImageJ software to confirm the accuracy of the computed distances and angles. Access and Use The CSXA dataset, algorithm, and related documentation are available for open access on GitHub and the Science Data Bank. Researchers are encouraged to utilize these resources for their studies, contributing to the advancement of computational imaging and machine learning in the medical field.
Relevance to the Community
The CSXA dataset and accompanying algorithm have significant implications for the research community. By providing a comprehensive, high-quality dataset, we aim to facilitate the replication of experiments and the development of new ML techniques for medical imaging. This resource is particularly valuable for researchers focusing on cervical spine diseases, offering a robust foundation for future studies and algorithmic advancements.
Follow the Topic
-
Scientific Data
A peer-reviewed, open-access journal for descriptions of datasets, and research that advances the sharing and reuse of scientific data.

Related Collections
With Collections, you can get published faster and increase your visibility.
Genomics in freshwater and marine science
Publishing Model: Open Access
Deadline: Jul 23, 2026
Computer vision in plant science and agriculture
Publishing Model: Open Access
Deadline: Jul 10, 2026




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in