De novo gene birth
Published in Ecology & Evolution

Where do new genes come from? The conventional answer is the duplication and divergence of old genes. But where do those old genes come from? It has recently become clear that rather than some chicken-and-egg story going back to a “big bang” of gene birth back in the primordial soup, genes continue to be born “de novo” from time to time, from non-coding sequences.
De novo gene birth is surprising – you might expect random polypeptides to be pretty deleterious. But around the time that the evidence for de novo gene birth started accumulating, some of my more mathematical research pointed to a way to get around this problem, via forces that could promote “preadaptation”. Back in 2011, Ben Wilson, then an undergrad in my lab, published a paper applying this previously abstract theory to the more specific conundrum of de novo gene birth. Our preadaptation theory predicted that non-coding transcripts would sometimes get translated by accident, to high enough levels to for natural selection to screen out the worst option and pre-select more viable ones. Ben used ribosomal profiling data to confirm this theoretical prediction. Years later, for our current paper, Ben returned to my lab, this time as a postdoc, to continue the same line of research.
We wanted to know more specifically what it is, at a biochemical level, that makes some polypeptides more amenable to becoming new genes than others. I had planned to study this by compiling a list of well-verified newborn genes and matching them as best I could to controls. Then I met Rafik Neme, who talked me into a better strategy. On the assumption that most gene families were originally born de novo, Rafik collaborated with another postdoc, Scott Foy from my lab, to assign an age to every gene family in mouse. We found elevated intrinsic structural disorder not just in the youngest genes, but dating back for hundreds of millions of years – in the light of this finding, Rafik’s advice was clearly correct.
Our most striking result is that the biggest difference between genes and non-genes isn’t for old genes, but for young genes. In other words, when it comes to structural disorder, a polypeptide has the highest chance of being born if it is extra gene-like, rather than sort-of gene-like. Our results bring home the fact that gene birth is a sudden transition. Evolution will quickly ditch a newly translated polypeptide, via one of any number of mutations that could disrupt the ORF or its translation, unless that polypeptide provides the organism with some advantage. There is either an advantage that natural selection can act on, or there isn’t. Because of this dichotomy, gene birth is sudden – and with this paper, we now know more about the circumstances that help make it possible.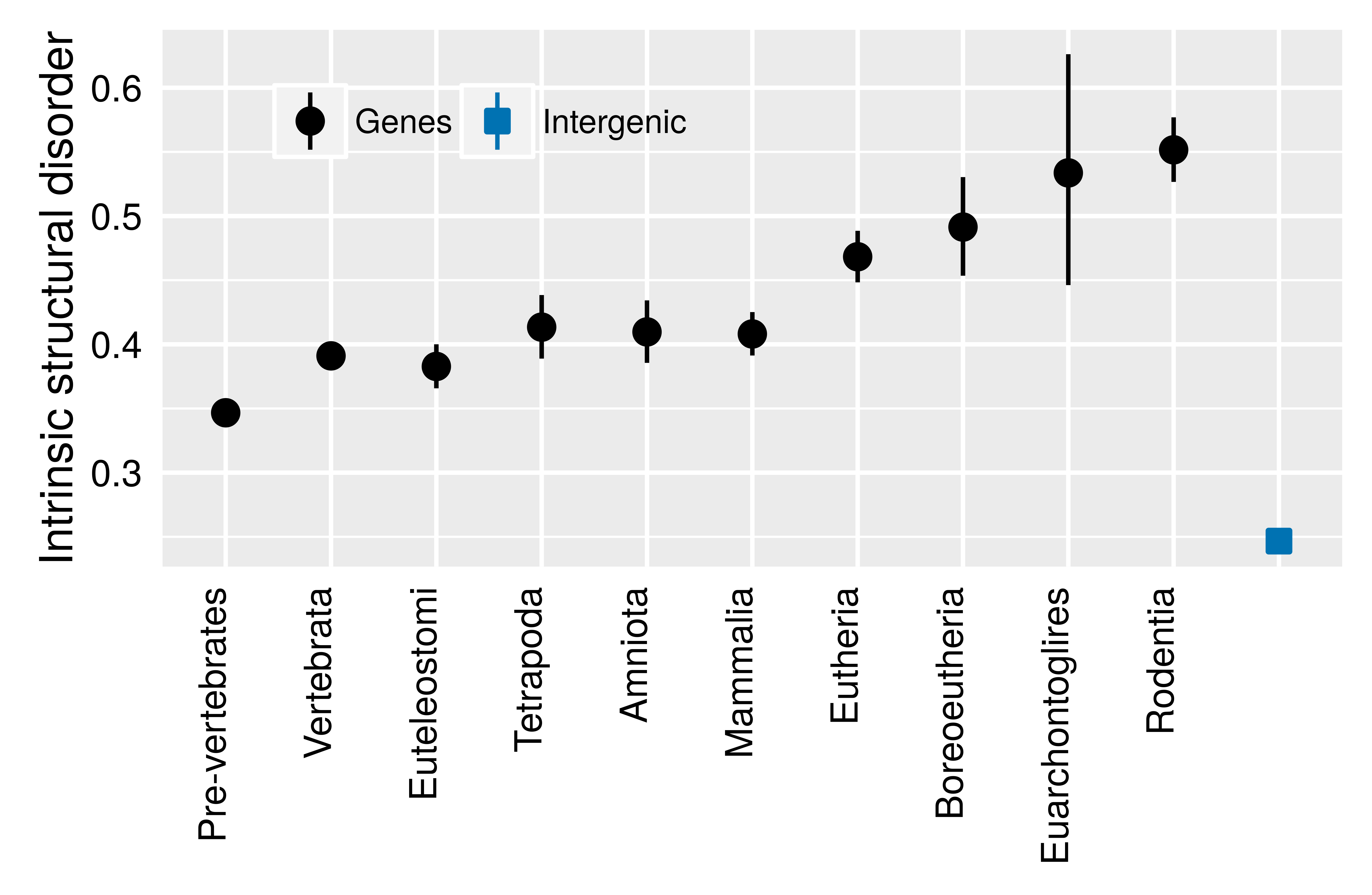
The paper in Nature Ecology & Evolution is here: http://go.nature.com/2onvfdq




Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in