Deep-Channel: Taking the donkey work out of single-channel analyses.
Published in Protocols & Methods

Patch clamp is an incredibly powerful technique, but Sakmann and Neher won the Nobel Prize for the recording method itself, not the analysis. There are still no fully automatic tools. It is not just my group that think that; it is a widely held view and I cite Twitter for evidence:

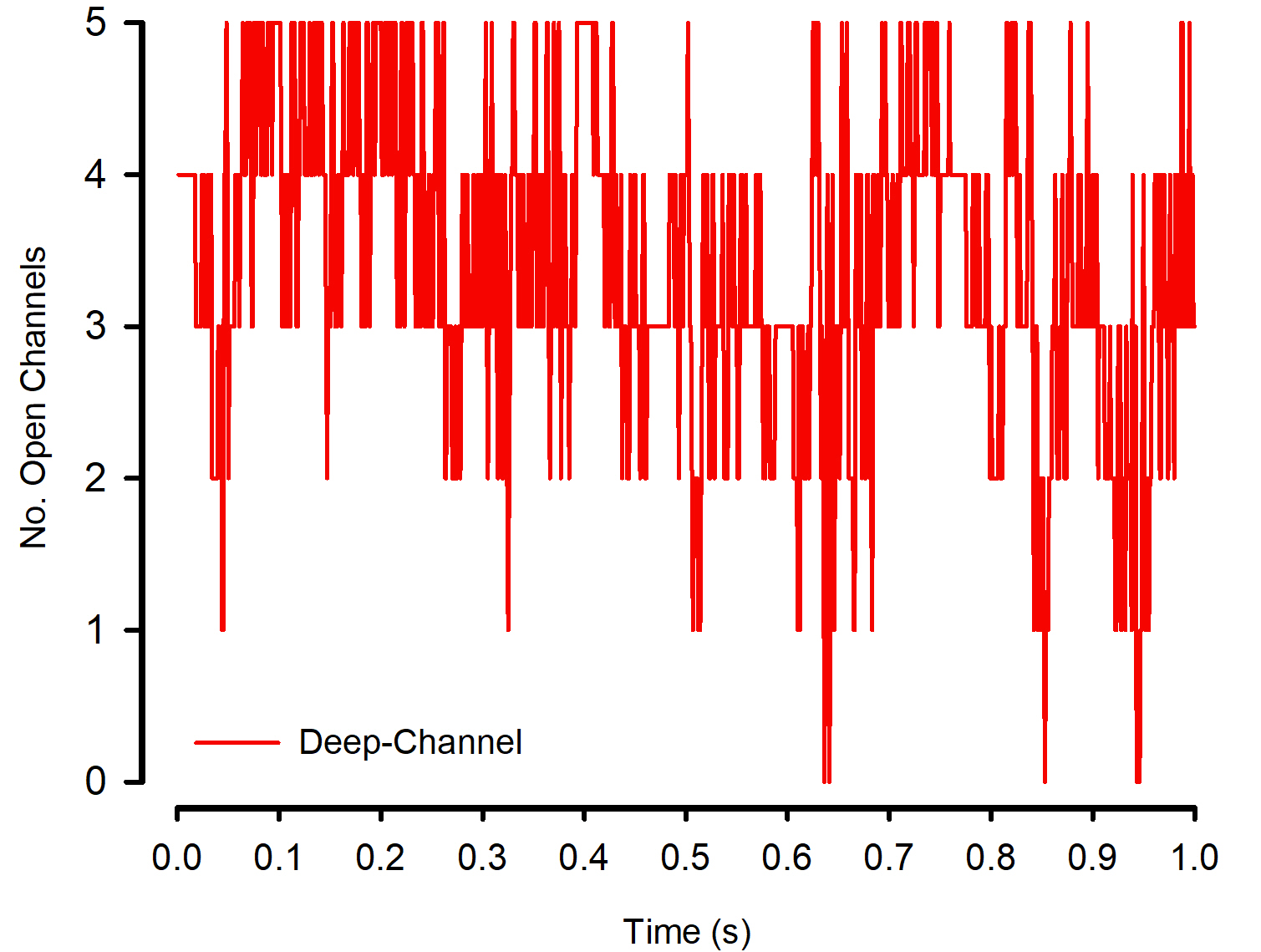
There are machines now that will automatically record ion channel activity, but they are not too popular (in terms of “single channel recording”) because there isn’t an accepted way to automatically analyse it, well not down to the degree of resolution you can do manually. Therefore, in this project, we’ve demonstrated how a deep learning neural network (the lay term would be artificial intelligence) method could automatically analyse ion channel data instead: Deep-Channel.
I am an ion channel specialist working on ion channels for some 30 (or more!) years now, but I have only been writing deep learning software for a few years now. I have taught a wide range of animal neuroscience including the visual system for many years, including Wiesel and Hubel’s work on the visual system. So, I always find it funny that when people describe convolutional neuronal networks (CNN) in seminars; they quite often describe how it works by analogy with an animal visual system then often coyly chuckle and throws in; “well of course the visual system isn’t really like a CNN….” ...but as someone who works/teaches in both worlds… I always want to throw my hand up and ejaculate “hey, no it is EXACTLY like that!”. So, the difference is that of course the brain has real neurones and unknown loss functions and methods (essentially) of strengthening connections, whereas with a CNN we know exactly how the code works.
The basic idea is the same; (sparing readers a third-rate account of a CNN) essentially, what a network does is look at the image like an animal (a human person in our case). Yes. It. Does. If you can see “it” by eye (and “classify it”) and you have a big enough training set it seems that a properly written deep neural network will be able to do it too.
So now to our problem; In the real world of single-channel analyses, nice big clear events are easy to analyse. but frequently we have these little glitches and things that a human expert will just look at and go; “event –not event (just noise)- event” etc. and move on. But that is so subjective! ….and are they even right? …experts may agree amongst themselves, but they are still not necessarily right; essentially the true “answer” is unknowable.
I’ve seen this argument in cricket (names withheld):
The technology says the batter hit the ball and it was caught so s/he is out.
Did the batter really hit the ball?
[batter] “I didn’t hit the ball, so it is not a legitimate catch, the tech is wrong”.
But the machine said you did. How do you know you didn’t hit the ball?
[batter] “Because I can feel it when I do hit it”.
How do you know if it is possible to touch the ball and not feel it?
[batter] “Because I can feel it when I hit it….”
So, when the machine says you hit it and you don’t feel it?
[batter] “the machine is wrong”.

Of course cricketers are picked for their cricket skills rather than their logic, but let’s spell this out; if the only way you know if you hit it, is when you feel you hit it and you are developing a machine to detect hits… there is no ground truth for hit or not, because clearly the human could make mistakes.
This is exactly the problem for developing the ultimate CNN to detect ion channel events.
There is no ground truth. We can compare our algorithm against a whole bunch of experts, but even if they all agree that an opening is an opening…. there just ain’t no way to know if they were right. So we just gave up.
No of course we didn’t! So what are the alternatives? Well one method is to simulate ion channel events. You set up a Markovian stochastic (“random” model) add a bit of noise and off you go you can generate ground truth open and close along with realistic LOOKING ion channel signal. Train your model on that? The potential biases in that method are horrendous. Noise will be simulated, and your network will learn to detect simulated ion channels. We tried a clever (we think!) workaround. We used a trick of playing that simulated data out into a real patch-clamp amplifier and recording it back thus picking up real amplifier noise and real filtering artefacts. There are still caveats however; there is a tendency for larger ion channel openings to have more noise and slightly different noise spectra. We had no way around that!
At the end of the paper, as you will see…what many people want to see, of course, is validation of the model against real ion channel data. There are major problems here; firstly, well as above, there is no a priori way to analyse real data and get a perfect “ground truth”. But now also this is magnified, because our Deep-Channel model can analyse really complex multi-channel datasets that we human experts, armed with existing software just cannot come close to analysing. …So our solution here was a compromise; we ran off a couple of strips of really quite simple ion channel data (real ion channel data from patch-clamp experiments) and got a few of us “experts” to analyse that [blinded]. We took our modal average analyses results and treated this as a ground truth. Then we compared Deep-Channel analyses with the “human experts” with the Cohen’s and Fliess’ kappas (Fliess kappa is kind of like a Cohen’s kappa agreement score, but with several different assessments). Sure enough there was a strong and statistically significant agreement.
Now here is the thing; where there is discord between Deep-Channel and human assessment…. which is correct? There is no way to tell.
So here, for the blog, not the paper… what do we have left to do? Well we are anxious for feedback on performance so we can improve the model; Deep-Channel2 is on the horizon already!! don’t want to give too many clues until we are ready to present this, but more features are coming, greater flexibility and of course it will all join the existing Github repository.

Please have a go with our software, tell us how you get on and hopefully we can put the idea of spending hours and hours of laborious (and subjective) single-channel analyses out to grass.
Link to full paper here.
Follow the Topic
-
Communications Biology
An open access journal from Nature Portfolio publishing high-quality research, reviews and commentary in all areas of the biological sciences, representing significant advances and bringing new biological insight to a specialized area of research.

Related Collections
With Collections, you can get published faster and increase your visibility.
Artificial Intelligence Methodology in Structural Biology
Publishing Model: Hybrid
Deadline: Nov 30, 2026
Healthy Aging
Publishing Model: Open Access
Deadline: Dec 31, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in