Global biomarkers of sepsis-causing bacteria investigated through the lens of multi-omic approaches
Published in Microbiology

Sepsis is a life-threatening, end-stage illness, in which the body starts to damage its own organs in response to infection. Bacterial sepsis represents a major cause of death, with the World Health Organization attributing approximately 20% of all human deaths to sepsis. This threat is exacerbated because we continue to fight bacterial infections with antibiotics, which inevitably drives increased antimicrobial resistance, reducing our current last line treatment options. To address this issue of poor survival outcomes and antimicrobial resistance, there needs to be investment and research towards developing novel targets for enhanced diagnostics, therapeutic intervention and vaccine development.
The primary aim of this project was to identify biological signals that are common between key bacterial blood pathogens, Escherichia coli, Group A Streptococcus pyogenes (GAS), Klebsiella pneumoniae species complex (KpSC), and Staphylococcus aureus, using state-of-the-art platforms across genomic, transcriptomic, proteomic and metabolomic approaches. We selected five representative clinical strains per species (six strains in the case of KpSC) that are phylogenetically diverse and also dominant causes of lethal human sepsis, to build a molecular blueprint of both conserved and pathogen-specific responses. This project was an ambitious undertaking that required field-specific expertise in molecular microbiology, biochemistry, next-generation sequencing, high resolution mass spectrometry, and integrative bioinformatics; fortunately, we were supported by a knowledge base that spanned over 20 affiliations from leading Australian research-intensive universities and colleagues at the University of California San Diego (US).
In order to integrate and enable comparative analyses between each of the omic datasets, it was crucial that the experimental workflow allowed for batched extractions of RNA, proteins and metabolites from the same bacterial culture. Furthermore, the sensitivity of each omic approach demanded meticulous execution of the experimental procedures to limit technical variation. This required standardising and optimising growth conditions across all strains.
We performed extensive growth characterisation of each strain under minimal media conditions, and exposure to 100% human sera, in an effort to obtain reproducible physiological responses; this would ensure that the transcripts, proteins, and metabolites detected across biological replicates were always representative of mid-exponential growth. Our thinking behind using minimal media (i.e., Roswell Park Memorial Institute media) was to coerce the bacterial cells to express its full metabolic repertoire so as to provide a background signal that would accentuate metabolic biomarker identification when interrogating data derived from human serum exposed samples. We screened the growth of each strain at high throughput and high resolution (i.e. OD600measurements every 15 minutes for 16 hours) before scaling to size. Optimising for growth was particularly challenging with the fastidious GAS, which required essential amino acids and trace metals, and several KpSC strains that were highly capsulated. We worked in close coordination with teams specialising in RNA sequencing (Australian Genome Research Facility), proteomics (Monash Proteomics and Metabolomics Facility and the Australian Proteome Analysis Facility) and metabolomics (Metabolomics Australia) to generate samples. Protocols for growth and extraction were optimised to a high degree, which resulted in reproducible samples for downstream processing. For example, RNA integrity numbers (i.e., RIN scores) were consistently greater than 8.0, and the quality of our dataset was later revealed in our analyses with clear separation on the multidimensional scaling sample space (Figures 4 – 6 of the original article).
Next, we needed to devise a hierarchy in data management with clear provenance of each biological replicate and omic sample that would facilitate deep integration. It was a ground-up approach that started with hybrid long- and short-read assembled genomes that included an in silico approach to “fish” for small plasmids that might have been otherwise missed during the extraction for high molecular weight genomic DNA. Precisely, unmapped short reads (post-mapping Illumina reads to assembled long-read genomes) were passed through the assembly step, where any small plasmids present would circularise. These reference grade genomes were hence annotated and subsequently used to form the foundation for the remaining omic platforms.
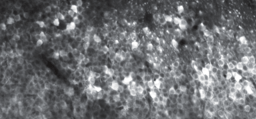
We discovered that exposure to human serum generated a global molecular signature of increased fatty acid and lipid biosynthesis and metabolism. This is consistent with cell envelope remodelling and nutrient adaptation for osmoprotection, which was crucially validated in vitro (Supplementary Figure 12 of the original article). We also identified the importance of cholesterol acquisition across the four bacterial species where our omic data indicated increased cholesterol association upon exposure to human serum and confocal microscopy was used to validate this close association (Figure 8 of the original article).
Our current findings represent only a fraction of what can be discovered, and it is our hope that the wealth of data generated here will be exploited to its fullest by the wider research community. We’ve hence made all of our data publicly available, with strains biobanked, and welcome any interests and calls for collaborations. This compendium of both conserved and pathogen-specific responses may provide targets for future therapeutic intervention.
This Antibiotic Resistant Sepsis Pathogens Framework Initiative consortium is supported by funding from Bioplatforms Australia (enabled by NCRIS).
Follow the Topic
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
Publishing Model: Hybrid
Deadline: Nov 02, 2026

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in