How to make a good open-science repository?
Published in Research Data
In computational research areas, the paper itself is not enough: one needs to access the associated data and code in order to fully understand the contribution, to verify the claims or to build upon the results. Such additional material has different names: "replication package", "laboratory package", "supplementary material", "online appendix", etc. In this post, we put all those terms under the umbrella of "open-science repository".
> An open-science repository contains the data, code, or both that is required to study and reproduce the results of a published paper.
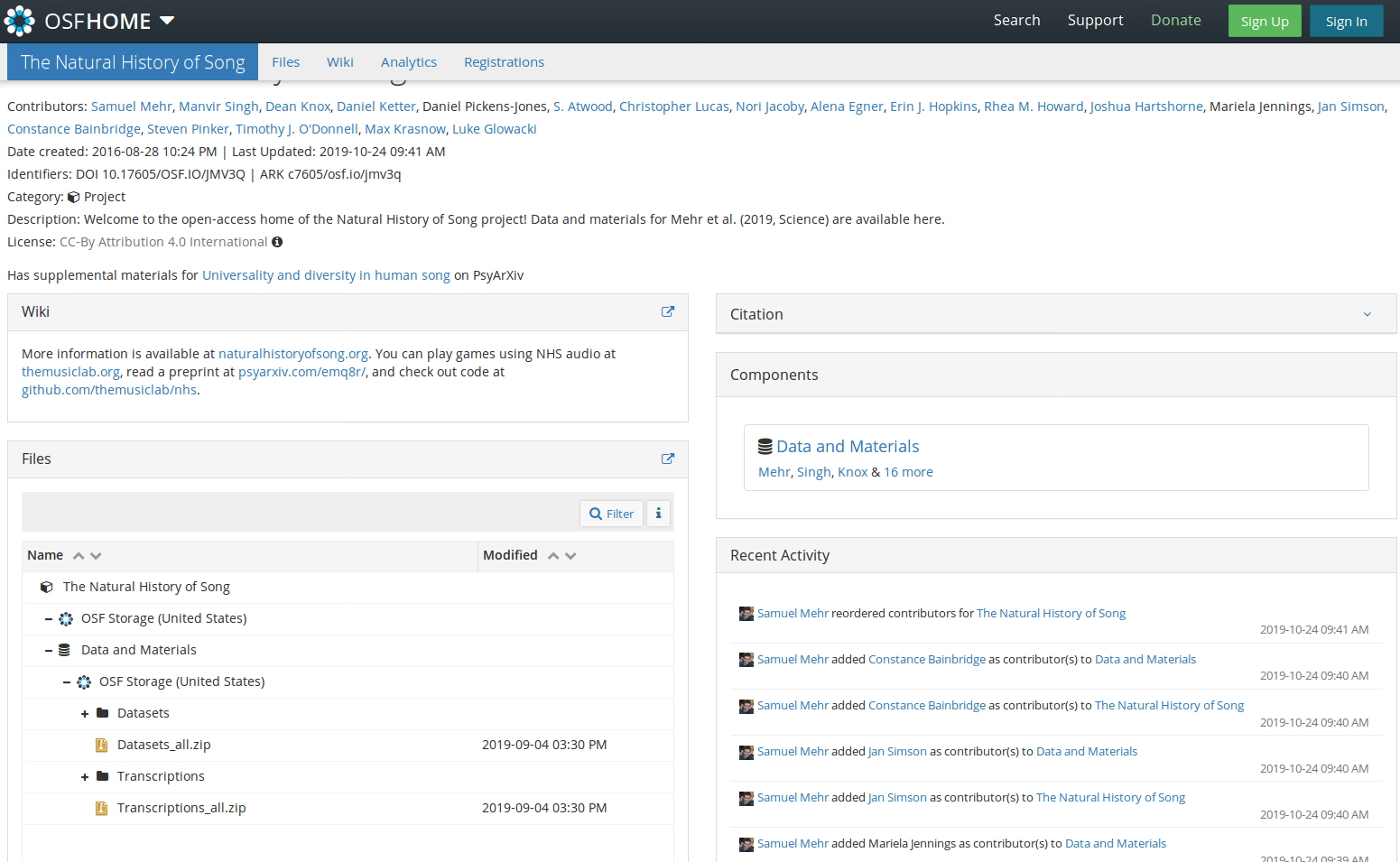
Fig 1: The open science repository of “The Natural History of Song” hosted on osf.io.
Requirements for an open-science repository
An open-science repository must be:
Downloadable: the data and code lies behind a single URL.
Findable: the open-science repository must be well indexed by search engines, it must be findable when googling for it (eg, based on the paper title).
Documented: an inventory of artifacts (files and folders) is included, the used file formats and the naming conventions are documented.
Complete: all numbers and figures can be re-computed from the artifacts in the open-science repository
Exercisable: the code must be executable, and does not depend on non publicly-available modules and libraries.
Durable: the repository URL must be stable in the long term (10 years, 100 years and more).
(Points inspired from the ACM policy and from the Sciclomatic project).
Where to host an open-science repository?
Open-science data and code must be pushed to platforms that are dedicated to provide long-term archival. Here are recommended options:
Zenodo by Cern
HAL by CNRS
archive.org by the Internet Archive foundation
Osf.io by the Center for Open Science
Github is also a good option because one gets versioning, replication, and communication (issue tracker) for free. But Github does not commit to providing stable URLs and long-term archival for decades. However, there is a direct bridge between Github and Zenodo: any Github repo can be transferred to Zenodo in one click, together with being given a DOI, see documentation.
We recommend to use Github as working repository and to upload a backup archive to Zenodo or equivalent once the project is over.
FAQ about open-science repositories
How big can an open-science repository be? Completeness is more important than size. (Note that Github supports arbitrary large repositories -- in our group, we have one open-science repository of 8GB for example)
Should I push the raw, intermediate or final data? Many computational results are based on a sequence of steps (Raw data -> Intermediate data 1 -> Intermediate data 2 -> Final data -> Table, graphics and numbers in the paper). In this case, the best solution is to push all the data, including the raw data and the intermediate data. This facilitates the use by future researchers: 1) they can only use the part they are interested in 2) if they find surprising or buggy data or behavior, having the data from all intermediate steps helps a lot in understanding and fixing the problem.
What license should be put on the open-science repository? For research code, liberal licenses (MIT, BSD) maximizes impact, GPL-like maximizes back-contributions and control. For research data, MIT/BSD work well, and Creative Commons licenses are also appropriate (eg CC-BY-SA).
I have data as Excel CLS files or as Google Doc Spreadsheets, how to share them?
One good option is to push them on an archival repo such as Zenodo.
Checklist for creating a good open-science repository
Main points to check:
Downloadable: does the data and/or code lies behind a single URL?
Complete: can all numbers and figures from the paper be re-computed from the package?
Durable: will the repository URL last in the long term?
Documented: is there an inventory of artifacts (files and folders) included?
Other points:
Does the repository contain a main file that is easily identifiable, typically a README? (example README for a data repository)
Are all file formats documented? For tabular files (CSV, TSV, Excel) is the meaning of rows and columns explained? For database dumps, is the restoration procedure documented?
For those used artifacts that are versioned (eg a Python package), is the used version documented?
For executable artifacts, is compilation and execution documented?
For studies involving humans, are all training materials present? Documented?
When proprietary data/code is used, is the procedure to get the proprietary data documented?
Is the contact point documented? Who to contact in case of questions? How to be contacted (email, issue, etc)?
Does the README tell which paper(s) to cite if one uses the data?
Software technology for reproducible results
Container images, such as Docker images are a good option for freezing dependencies
Virtualization images, such as VirtualBox images, are helpful to get a running environment quickly.
The mainstream dependency management systems (Maven, PIP) are very valuable to specify the dependencies. Conda is a valuable technology in that space.
Jupyter Notebooks is very popular to document and typeset research code and results.
Outreach
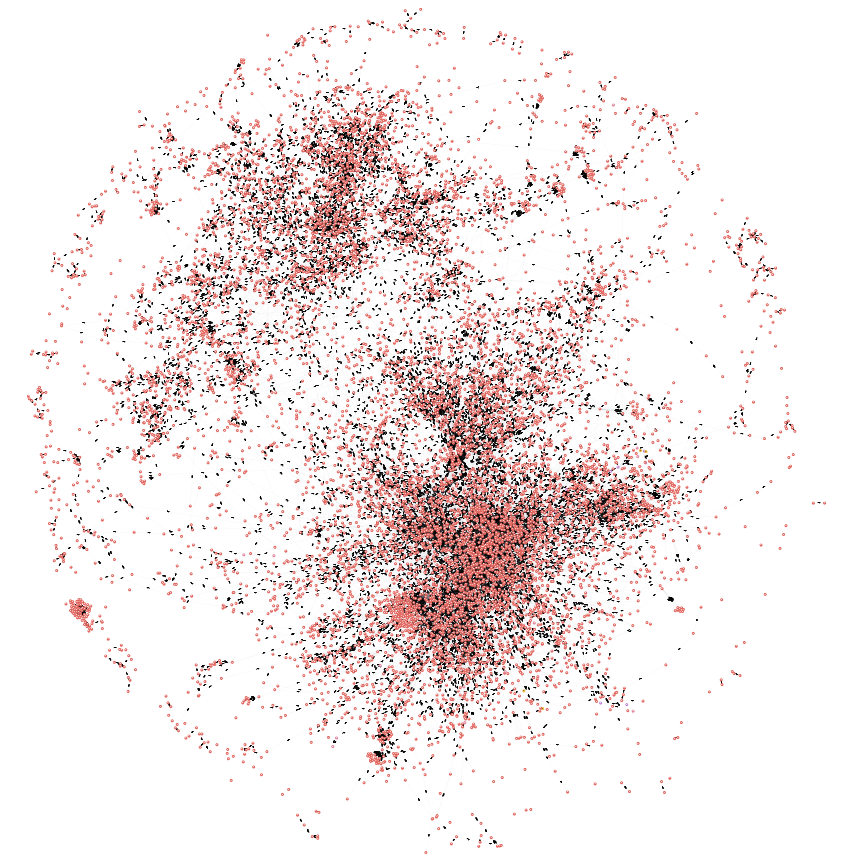
Note that, beyond reproducibility, open-science is also great for outreaching to society. In that case, having a beautiful repository with nice illustrations is very good idea. Illustrations of scientific data and code are inspiring for citizens and create an emotional connection with the data that appeals to a wider audience than our scientific peers.

Fig 2: artistic representation of the software dependency graph of Maven Central. Courtesy of Cesar Soto Valero.
Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in