PTMGPT2: An Interpretable Protein Language Model for Enhanced Post-Translational Modification Prediction
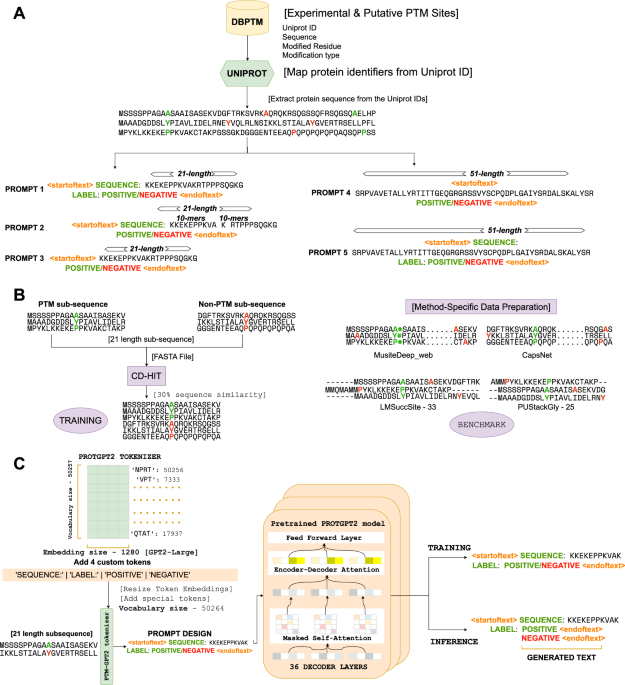
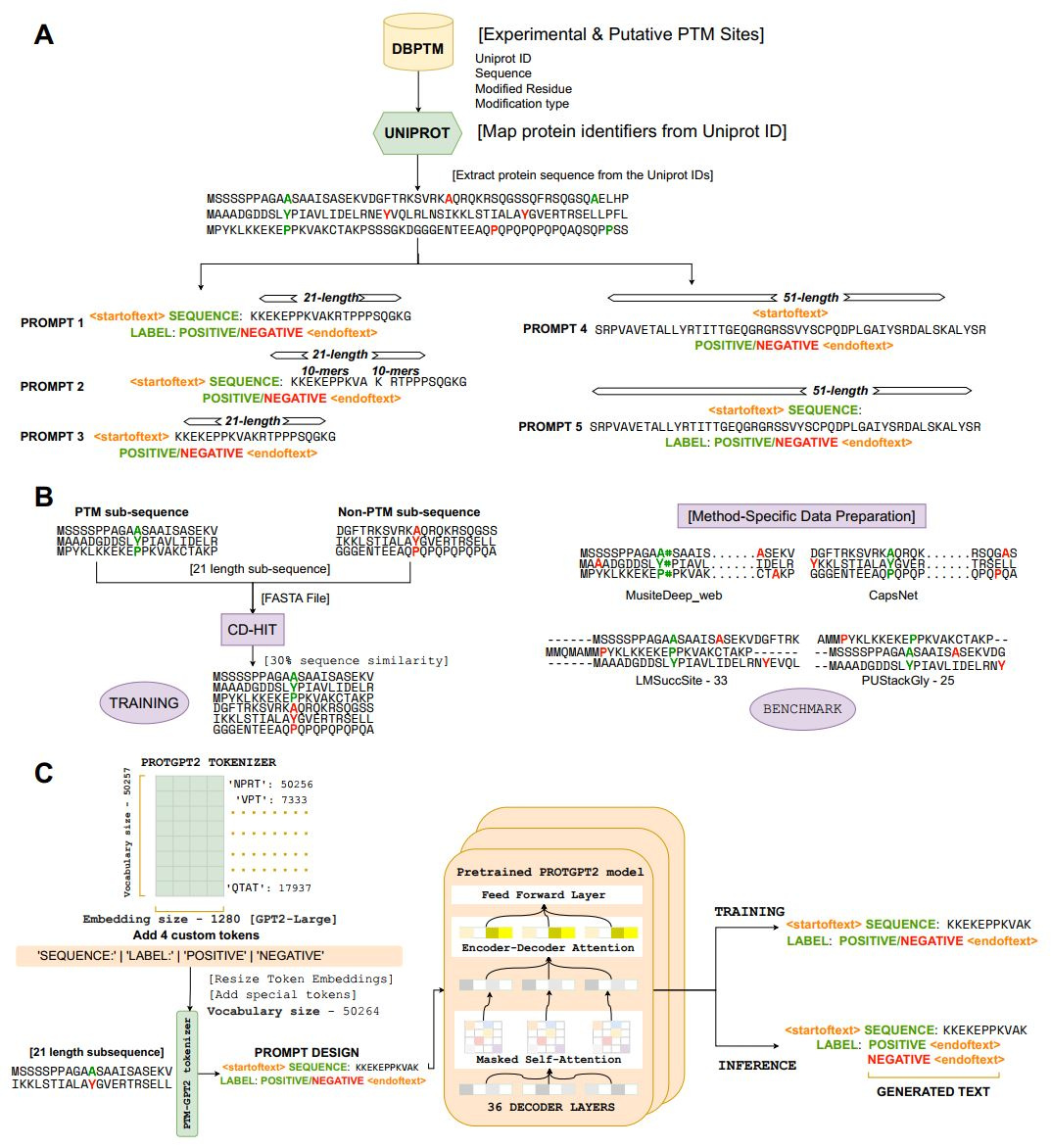
PTMGPT2 uses GPT-based architecture and prompt-based fine-tuning to predict post-translational modifications. It outperforms existing methods across 19 PTM types, offering interpretability and mutation analysis. This advances the understanding of protein function and disease research.
Published in Cell & Molecular Biology and Computational Sciences
Multiple Contributors
Follow the Topic
Protein Biochemistry
Life Sciences > Biological Sciences > Molecular Biology > Protein Biochemistry
Artificial Intelligence
Mathematics and Computing > Computer Science > Artificial Intelligence
-
Nature Communications
An open access, multidisciplinary journal dedicated to publishing high-quality research in all areas of the biological, health, physical, chemical and Earth sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Women's Health
A selection of recent articles that highlight issues relevant to the treatment of neurological and psychiatric disorders in women.
Publishing Model: Hybrid
Deadline: Ongoing
Tumor Microenvironment Crosstalk and Therapeutic Implications
With this cross-journal Collection, the editors at Nature Immunology, Nature Communications, Communications Medicine and Scientific Reports invite manuscripts that highlight cutting-edge research on TME crosstalk and its therapeutic implications. Topics of interest include immune modulation and checkpoint pathways, cancer-associated fibroblasts and stromal remodeling, angiogenesis and vascular normalization, metabolic reprogramming within the TME, and the role of microbiota in tumor-immune dynamics. We also welcome studies on novel therapeutic approaches that exploit TME vulnerabilities to advance cancer treatment.
Publishing Model: Hybrid
Deadline: Nov 02, 2026



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in