Scaling out Ising machines
Published in Electrical & Electronic Engineering

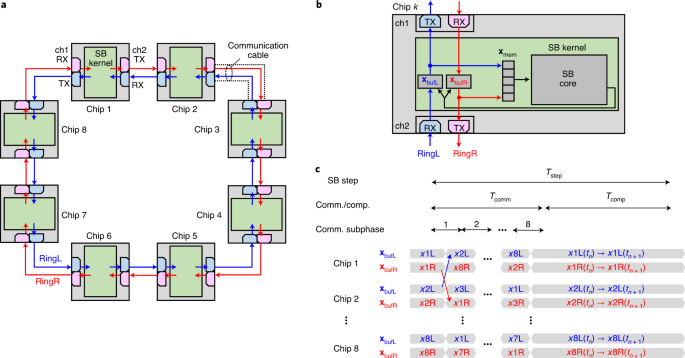
When I analysed the parallelism of the simulated bifurcation algorithm, I immediately found that there was a design space to explore a scale-out architecture of Ising machines. The problem was how to synchronize the multiple chips. The requirement for synchronization accuracy is getting more and more severe as we increase chips.
Combinatorial optimization problems are economically valuable but computationally hard to solve. After the appearance of D-wave’s quantum annealer in 2011 [1], special-purpose hardware devices called Ising machines have been extensively studied. Many combinatorial optimization problems can be converted to the ground-state search problems of Ising spin models, and Ising machines have been developed to quickly find the optimal or near optimal solutions of Ising problem. The computational complexity of combinatorial optimization scales exponentially with the problem size. The scalability for an Ising machine, as well as its speed performance, determines the practical applicability.
In summer 2017, I (computer scientist) run into my colleague, Hayato Goto (quantum computing specialist) at a workshop. Although we belonged to the same corporate research center, that was the first time for us to recognize each other (there were about one thousand researchers). Once he knew I was an FPGA (field-programmable gate array) specialist, he passionately talked about his idea to build an ultrafast Ising machine by combining our expertise. He was conceiving a novel classical algorithm for solving Ising problem, called simulated bifurcation (SB), which was derived from a quantum adiabatic optimization method also developed by him. He thought that if we implemented SB in a massively-parallel fashion with an FPGA, the SB machine would be very fast. Thus, our first-term project was started and the achievement was published in 2019 [2], which has attracted keen attention (as of today, 60 citations and 45,642 full views). Further, an enhanced version of SB algorithm has recently been published [3].
The single FPGA-based SB machines involved many processing elements (8,192 multiplier–accumulators per chip [2,4]) and more importantly, were able to fully utilize the computation resources in the time domain (activity factor of 92% [4]). This was achieved with customized on-chip memory subsystems to feed sufficient data to the processing elements. The machine size (maximum problem size) of such a single-FPGA implementation is limited apparently by on-chip memory. After that, based on the single-FPGA SB technology, we also developed a proof-of-concept device for ultra-high-speed financial transaction machines that detect most profitable transaction opportunities at microsecond speeds [5]. However, the capability of the transaction machine was limited to fully-connected 16-asset problems (a market graph with 16 nodes and 256 directed edges). What can we do if we want to take more assets into account? There is an apparent limitation in scaling up a single FPGA.
Those size-limitation issues strongly motivated me to pursue a scale-out architecture of Ising machines. A larger Ising machine can, in principle, be built by partitioning a spin system into multiple subsystems. In this case, the spin-spin couplings over the subsystems must be incorporated, and the partitioned subsystems also have to evolve in a single time domain. Communication and synchronization between the partitioned subsystems can easily degrade the speed performance. This difficulty is more pronounced for all-to-all connected systems, which are of more practical value than sparse ones. I wanted to develop a multi-chip architecture that enables us to continue scaling of both the machine size and speed performance.
It was not very difficult to devise a partitioned version of SB algorithm that can be executed simultaneously on multiple connected chips. However, the requirement for synchronization accuracy was very severe. I recognized this issue as soon as I started thinking of multi-chip architectures to implement the partitioned SB. For the Ising formulation, the computation of a spin-spin pairwise interaction is just one multiply-accumulation operation. This situation contrasts with conventional N-body simulations (full-connection SB has a computation pattern similar to N-body), where a pairwise gravitational (or Coulomb)-force computation consists of 38 to 40 floating-point operations. Because of the simple Ising interactions, we can greatly increase computation parallelism per chip and thus shorten the computation time per time-evolution step (synchronization interval), necessitating more elaborate synchronization mechanisms.
Masaya Yamasaki (my colleague, computer scientist) and I explored a wide variety of architectures and prototyped some candidates. Eventually, we reached a multi-chip architecture that relies on an autonomous synchronization mechanism. In the architecture, the chips are allowed to be launched independently, but can be synchronized autonomously through exchange processes of spin information between neighbouring chips. This autonomous synchronization mechanism leads to good scalability of the processing speed of the cluster while avoiding performance saturation due to communication overheads. Thus, in this paper, we have demonstrated a scale-out architecture for Ising machines with all-to-all spin-spin couplings that allows enlargement of the machine size and enhancement of the processing throughput by connecting multiple processing chips.
For more information, please refer to the full article in Nature Electronics: https://doi.org/10.1038/s41928-021-00546-4
Follow the Topic
-
Nature Electronics
This journal publishes both fundamental and applied research across all areas of electronics, from the study of novel phenomena and devices, to the design, construction and wider application of electronic circuits.



Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in