Condensing information on condensates
Published in Protocols & Methods


What are biomolecular condensates?
We have been on the quest for a definition for the last years, discussing with colleagues in Dresden and beyond. The definition still evolves with the discoveries in the field. Biomolecular condensates represent a newly recognized form of cellular self-organization. They selectively concentrate biomolecules (e.g., proteins and nucleic acids) with spatial and temporal precision, to give rise to membrane-less cellular compartments. Since their discovery, thousands of papers were published describing their role in biochemical processes, both in physiology and disease, as well as describing physico-chemical rules for their assembly and compositional bias.

As with every emerging field, new concepts and definitions are floating around until they crystallise and the community agrees on standards. Should we call the round objects observed under the microscope droplets, foci, puncta? Should we call the in vivo observed functional condensates membraneless organelles (MLOs) or biomolecular condensates?
It gets even more complicated, since the field of biomolecular condensates is highly interdisciplinary. Physics inspired biologists to discover a new form of self-organization in the cell driven by phase separation, and terms from physics got recycled for biological phenomena; as such, they needed context-revised definitions.
AI needs high-quality training data
How many unique condensates are known to date? What are their known protein components? What is the experimental evidence that a protein localizes to a condensate? Can we learn and predict the existence of yet undiscovered condensates and their protein components? Could we train an AI that predicts if a protein would form biomolecular condensates in the cell, by only knowing its protein sequence?
We are computational biologists, who would like to understand the sequence determinants of cellular self-organization. After seeing anecdotal evidence about how amino acid composition and patterns could drive phase-separation, we needed large, structured and curated experimental data to see if the findings and identified rules are generalizable. Overall, there is a need for comprehensive and curated data to aid. AI researchers.
Sustainable database via crowdsourcing
The aspects above motivated us to build CD-CODE database. This is a nearly impossible task for one single lab or even an institute such as ours (Max Planck Institute of Molecular Biology and Genetics, MPI-CBG Dresden), which is strategically positioned as a hub for condensate research. Therefore, we decided to build in the crowd-sourcing functionality to allow the community to engage. We had wild ideas at the beginning about creating a social media-like platform, with like and dislike buttons and chat options. Without having the resources of twitter or facebook, we settled on a simpler version that still keeps the history of all edits, has a user management system and aims to acknowledge all contributors (currently we have ~20 contributors). Eventually, the funding that was generously provided by Dewpoint Therapeutics and the Max Planck Gesellschaft (MPG), allowed us to hire a software engineer, Soumyadeep Ghosh (Deep), who led the development of the platform with the help of a student, Rajat Ghosh, and HongKee Moon and Lena Hersemann from the Scientific Computing facility at MPI-CBG. Without having someone with industry experience in professional software development, we could not have created such an interactive and user friendly platform.

Condensate-centric database
Of course, we were not the first ones to try and catalogue condensate-forming proteins. There were already four excellent databases for phase-separating proteins along with their condensate localizations (PhaSePro, LLPSDB, PhaSepDB, DrLLPS). However, we wanted to create a catalogue of “condensates” and their protein components, rather than of proteins with propensity to phase separate. The ambitious goal of our project was to create the UniProt of “condensates”. With input from the lab of Tony Hyman and the Dewpoint team (lead by Diana Mitrea and colleagues), who were the first users of the database, we outlined the vision of the project in 2020. Deep took on his first engineering task of creating a structured, clean and innovative database schema. He was aided by the half-bio and half-computer-science brains of Willis Chow, a PhD student, and Cedric Landerer, a postdoc in the Toth-Petroczy lab, to generate something like this:

The good chunk of seed data parsed from existing databases was a nice beginning to fill up our fresh-and-ultra sophisticated schema; however, it was very sparse. The missing information can only be filled by experts and manual curation. Actually, we would have liked to develop an AI-powered smart bot that could scan all the literature in the condensate field and then decide with high accuracy the components of a condensate. Wait, did someone say ChatGPT?
Filling the database with life
In order to map and standardise the condensate names, Willis created a synonyms list of all the condensate names available. This was a difficult and crucial step since the terminology was not uniform, people were inventing new words, or using different terms to define the same phenomena. His bold efforts of going through all the not-so-meaninfgul condensate names and trying to find which ones are actually the same was the first step of the manual curation in our database.
Later Nadia Rostam, an experimental biologist, joined and took over the hard task of manual curation for enhancing the data in our database. Over a short period of one year, she curated the protein components of 100+ condensates while consulting with the Hyman lab and others across the campus. Interestingly, most known condensates are found in mammals and many are clade-specific, likely depicting a bias in scientists' choices of model organisms.
Condensate proteomes overlap
To facilitate our understanding of condensate-specificity of proteins, we collected all known condensates a given protein was found in, and we curated the experimental evidence for association of each protein with a given condensate. We used a confidence score, corresponding to zero to five stars (proteins that have zero or one star rating have not been manually curated yet) to quantify the degree of experimental evidence that supports the condensate localization designation.
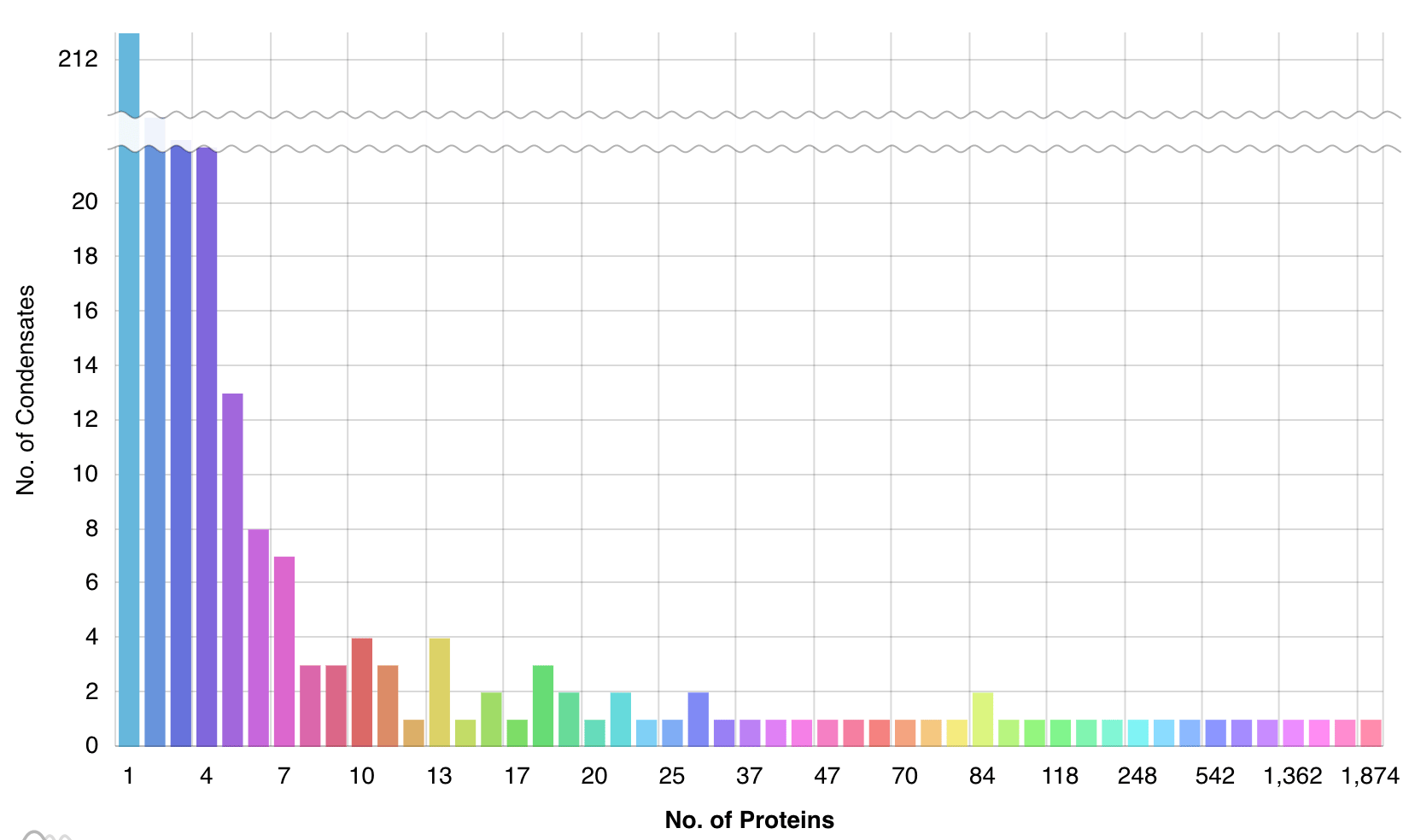
We found that many proteins localize in more than one condensate and the overlap between condensate proteomes is large. Marker proteins are used to define the identity of the condensates and they are thought to be uniquely associated with a given condensate. Our database revealed that several known marker proteins are not specific to one condensate.

The database has already facilitated our research, for example helped better designing markers and developing a CD-CODE data driven machine learning model to predict protein condensation (coming soon by Anna Hadarovich et al.).
WE NEED YOU!
We had many inspiring discussions (sometimes heated debates) about condensates with our colleagues in Dresden and at Dewpoint while developing CD-CODE. We hope the web application will facilitate world-wide engagement of researchers to curate the data and scrutinize the definitions related to condensates.

If you are also intrigued by biomolecular condensates and would like to learn about them or contribute to the curation of the wealth of information about them, join us!
Follow the Topic
-
Nature Methods
This journal is a forum for the publication of novel methods and significant improvements to tried-and-tested basic research techniques in the life sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Methods development in Cryo-ET and in situ structural determination
Publishing Model: Hybrid
Deadline: Oct 30, 2026

![When PSMA-targeted therapy is not enough: high-risk localized prostate cancer after repeated [177Lu]Lu-PSMA radioligand therapy](/cdn-cgi/image/metadata=copyright,fit=scale-down,format=auto,quality=95,width=256,height=256/https://public-storage.zapnito.com/Ku6h7Yyp4Q0LXqRRMICCHR2v4LcOsmxMrmDPtOYuI1c)

Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in