EnzymeML: seamless data flow and modelling of enzymatic data
Published in Bioengineering & Biotechnology
In all fields of science, we face a rapidly increasing volume and complexity of research data. While more and more data is generated by an increasing number of researchers and increasing research expenditure worldwide1, this data is hardly manageable by our scholarly practice of communicating scientific results. While the manual management of your own data is laborious, accessing and re-analyzing data of other research groups is almost impossible. The predominantly manual handling of research data and the lack of standards are time-consuming and error-prone, and limit the productivity of researchers. Even worse, because of incomplete metadata and the lack of original data, published results are hardly reproducible, which leads to a loss of trust in scientific results. More and more researchers perceive an information overload and feel like drowning in a data tsunami.
This observation also applies to studies on catalytic activity, selectivity, and stability of enzymes and enzymatic networks. The rapid growth of data volume is fueled by high throughput experimental techniques such as liquid handling and microfluidics techniques for screening of enzyme libraries, substrate libraries, or reaction conditions. High-throughput analytics methods such as NMR spectroscopy, LC-MS, or GC-MS provide quantitative information on the concentrations of many metabolites at the same time. In most papers, only a small fraction of the huge amount of measured data is communicated and most of the originally measured data is generally not accessible. In addition, the description of reaction conditions is often incomplete2, which makes re-analysis of data and reproduction of the experiment impossible. Even if data is communicated, its re-use is considerably hampered, because standardized data formats for enzymatic data are missing, and the necessary re-formatting and copying/pasting is laborious and error-prone. In addition, the data describing enzymatic experiments is complex, because an enzymatic reaction depends on the protein sequence of the enzyme, the recombinant host organism, the reaction conditions, and on non-enzymatic side reactions, and effects such as inactivation or inhibition of the enzyme and evaporation of the medium are influencing the results.
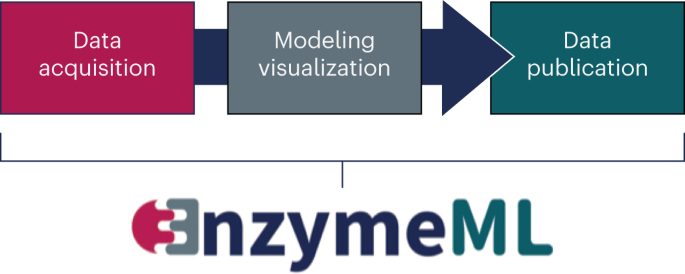
But there is hope, as we demonstrate in our paper on "EnzymeML: seamless data flow and modelling of enzymatic data" (https://www.nature.com/articles/s41592-022-01763-1). This paper describes a novel standardized data exchange format, EnzymeML, which is based on the widely used Systems Biology Markup Language3. EnzymeML serves as a format to comprehensively report the results of an enzymatic experiment: reaction conditions, measured data, the kinetic model, which was applied to analyse experimental data, and the estimated kinetic parameters4. EnzymeML provides a seamless communication channel between experimental platforms, electronic lab notebooks, tools for modelling of enzyme kinetics, publication platforms, and enzymatic reaction databases (Fig. 1).

Fig. 1 EnzymeML serves as a communication channel between experimental, modelling, and publication platform.
An EnzymeML document contains information about reaction conditions and the measured time course of substrate or product concentrations (Fig. 2). It is generated from an EnzymeML spreadsheet (https://enzymeml.org/tools/) or by the webtool BioCatHub (https://biocathub.net/). Kinetic modelling is performed by uploading EnzymeML documents to the modelling platforms COPASI5 or PySCeS6. The estimated kinetic parameters are then added to the EnzymeML document. The EnzymeML document containing the experimental and modelling results is then uploaded to a Dataverse7 installation (e.g. DaRUS, https://darus.uni-stuttgart.de) or to the reaction kinetics database SABIO-RK (http://sabio.h-its.org). The workflow of a project is encoded as Jupyter Notebook, which can be re-used, modified, or extended. Feasibility and usefulness of the EnzymeML toolbox are demonstrated in six scenarios, where data and metadata of different enzymatic reactions are collected, analysed, and uploaded to public data repositories for future re-use (https://github.com/EnzymeML/Lauterbach_2022)

Fig. 2 Structure of an EnzymeML document. An EnzymeML document is a ZIP container in OMEX format and contains the experiment file (in SBML format) with the metadata of the experiment, the kinetic model, and the estimated kinetic parameters, as well as the measurement files (in CSV format) with the time courses of substrate and product concentrations. The manifest file (in XML format) lists the content of the ZIP container.
Because EnzymeML documents are structured and standardized, the experimental results encoded in an EnzymeML document are interoperable and reusable by other groups. Because an EnzymeML document is machine-readable, it can be used in an automated workflow for storage, visualization, data analysis, and re-analysis of previously published data, without limitations of the size of each dataset or the number of experiments.
The digitalization of biocatalysis increases efficiency by automation, if we make data machine-readable and thus allow machines to assist us with management, visualization, and analysis of data. Digitalization improves the reproducibility of experiments and data analysis, and thus promotes trust in science. Making best use of the rapidly growing enzymatic data, the EnzymeML toolbox is a useful instrument that enables researchers to ride the research data wave.
References
- United Nations Educational, S. and C. O. UNESCO Science Report 2021: The Race Against Time for Smarter Development. (2021) doi:10.18356/9789210058575.
- Halling, P. et al. An empirical analysis of enzyme function reporting for experimental reproducibility: Missing/incomplete information in published papers. Biophys. Chem. 242, 22–27 (2018).
- Pleiss, J. Standardized Data, Scalable Documentation, Sustainable Storage – EnzymeML As A Basis For FAIR Data Management In Biocatalysis. ChemCatChem 13, 3909–3913 (2021).
- Range, J. et al. EnzymeML—a data exchange format for biocatalysis and enzymology. FEBS J. 289, 5864–5874 (2022).
- Bergmann, F. T. et al. COPASI and its applications in biotechnology. Journal of Biotechnology vol. 261 215–220 (2017).
- Christensen, C. D., Hofmeyr, J. H. S. & Rohwer, J. M. PySCeSToolbox: A collection of metabolic pathway analysis tools. Bioinformatics 34, 124–125 (2018).
- Crosas, M. The dataverse network®: An open-source application for sharing, discovering and preserving data. D-Lib Mag. 17, (2011).
Follow the Topic
-
Nature Methods
This journal is a forum for the publication of novel methods and significant improvements to tried-and-tested basic research techniques in the life sciences.

Related Collections
With Collections, you can get published faster and increase your visibility.
Methods development in Cryo-ET and in situ structural determination
Publishing Model: Hybrid
Deadline: Oct 30, 2026


Please sign in or register for FREE
If you are a registered user on Research Communities by Springer Nature, please sign in